深度学习优化函数详解系列目录
深度学习优化函数详解(0)– 线性回归问题
深度学习优化函数详解(1)– Gradient Descent 梯度下降法
深度学习优化函数详解(2)– SGD 随机梯度下降
深度学习优化函数详解(3)– mini-batch SGD 小批量随机梯度下降
深度学习优化函数详解(4)– momentum 动量法
深度学习优化函数详解(5)– Nesterov accelerated gradient (NAG)
深度学习优化函数详解(6)– adagrad
深度学习优化函数详解(7)– adadelta
深度学习优化函数详解(8)– adam
后面两篇文章代码已经写完了,文章一直懒得写,等有空再补上吧。。。
本系列的全部代码在这里:https://github.com/tsycnh/mlbasic 喜欢的同学记得给个star哦~
序
在做一些深度学习的算法的时候,都会用到优化函数,在各种成熟的框架中,基本就是一行代码的事,甚至连默认参数都给你设置好了,基本不用动什么东西,最后也会有比较好的优化结果。但是对于优化函数这么核心,这么基本的东西总是模棱两可实在不应该。于是想自己把一些常用的优化函数从原理上搞清楚,所以才有了这个系列的文章。每一篇文章都有配套的python代码,文末会给出地址。
线性回归问题(Linear Regression)
假设我们有一组数据,是一些房子的面积和价格。如下
| 面积 | 30 | 35 | 37 | 59 | 70 | 76 | 88 | 100 |
|---|---|---|---|---|---|---|---|---|
| 价格 | 1100 | 1423 | 1377 | 1800 | 2304 | 2588 | 3495 | 4839 |
用这些数据我们可以在坐标系中绘制出一系列散点
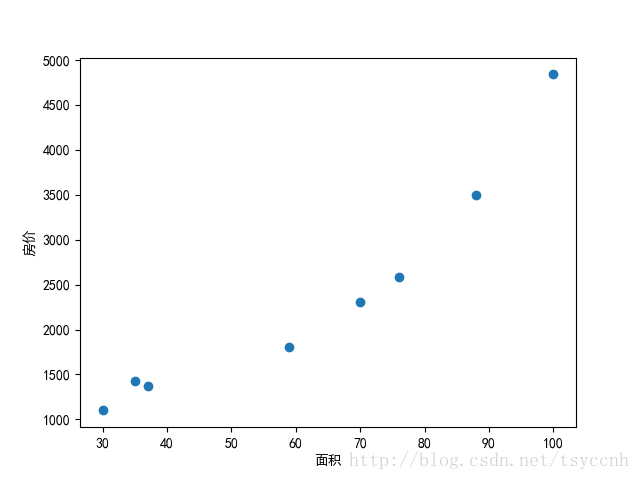
我们所想要解决的问题,就是给出任意的一个面积,预测对应的房价。 所以这是一个预测问题。也就是回归问题。
这里我们用最简单的线形模型来做房价预测。那么这个问题也可以称之为线性回归问题。
线形模型简单来说就是直角坐标系中的一根线,用
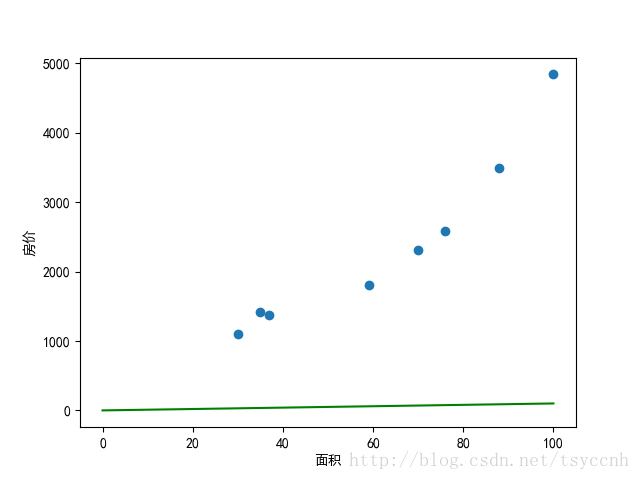
可以看出,参数 并未提供太大的斜率,这是由于横坐标和纵坐标尺度差距太大所造成的,在后期的训练中,数据在各个维度上尺度差异太大很容易造成训练速度过慢。所以一般来说,在训练之前,我们首先会对数据做归一化处理,统一归到 之间,上公式:
这样就得到归一化之后的数据
| 面积(x) | 0.0 | 0.0714 | 0.1 | 0.4143 | 0.5714 | 0.6571 | 0.8286 | 1.0 |
|---|---|---|---|---|---|---|---|---|
| 价格(y) | 0.0 | 0.0864 | 0.0741 | 0.1872 | 0.3220 | 0.3980 | 0.6405 | 1.0 |
再画一遍上面的图。
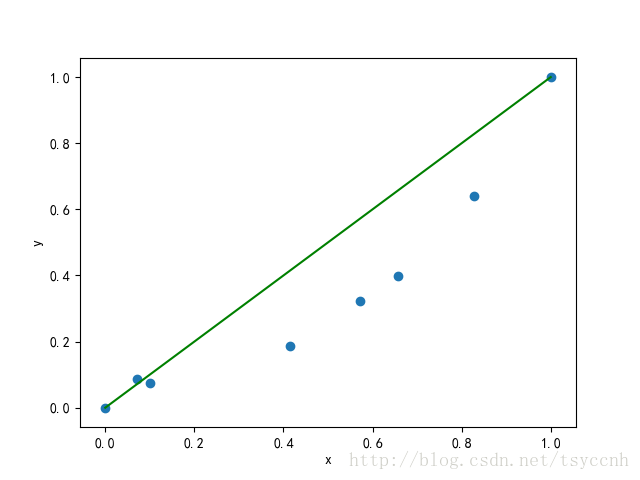
再对数据做过预处理之后,我们现在就来评判 这条线多大程度上完成了预测。显然的,我们会用到我们的训练数据 代入到模型 中,看看和实际结果差多少。通过模型得到的结果我们称之为预测值
| 面积(x) | 0.0 | 0.0714 | 0.1 | 0.4143 | 0.5714 | 0.6571 | 0.8286 | 1.0 |
|---|---|---|---|---|---|---|---|---|
| 价格(y) | 0.0 | 0.0864 | 0.0741 | 0.1872 | 0.3220 | 0.3980 | 0.6405 | 1.0 |
| 预测值( ) | 0.0 | 0.0714 | 0.1 | 0.4143 | 0.5714 | 0.6571 | 0.8286 | 1.0 |
| 差值( ) | 0 | -0.015 | 0.0259 | 0.2271 | 0.2494 | 0.2592 | 0.1880 | 0 |
通过差值可以很明显的看出预测和实际真值有一定的差距,那么如何定量描述这种差距呢?通常我们会用差值的平方和 来表示,如下
| 差值的平方和 | 0 | 0.000225 | 0.00067081 | 0.05157441 | 0.06220036 | 0.06718464 | 0.035344 | 0 |
|---|
接着把每一个平方和的值做一个累加,得到一个值0.2172。我们一共有8组数据,再把这个数除以8。然后再除以2,就得到了一个我们称之为loss的数值0.01357,写成公式就是下面这样:
除以2是为了后面求梯度的时候方便,除以m是做一个平均的量化。
这种求loss的方法称之为Mean Squared Error (MSE), 即均方差。
接下来的目标很明确,就是
如何不断的调整参数 来使loss越来越小,最终令预测尽可能接近真实值。
从这一点出发,很多人做了很多不同的工作,我们将这些方法统称为优化函数
后面的文章将一一解读各种常用的优化函数