Table of Contents
数据库类别
目前广泛使用的关系数据库有如下几种:
付费的商用数据库:
-
Oracle,典型的高富帅;
-
SQL Server,微软自家产品,Windows定制专款;
-
DB2,IBM的产品,听起来挺高端;
-
Sybase,曾经跟微软是好基友,后来关系破裂,现在家境惨淡。
这些数据库都是不开源而且付费的,最大的好处是花了钱出了问题可以找厂家解决,不过在Web的世界里,常常需要部署成千上万的数据库服务器,当然不能把大把大把的银子扔给厂家,所以,无论是Google、Facebook,还是国内的BAT,无一例外都选择了免费的开源数据库:
-
MySQL,大家都在用,一般错不了;
-
PostgreSQL,学术气息有点重,其实挺不错,但知名度没有MySQL高;
-
sqlite,嵌入式数据库,适合桌面和移动应用。
python连接数据库
python连接sqlite
sqlite是用c编写的,非常小,它被内置于python当中,所以如果使用sqlite,我们无需下载数据库以及与数据库相连接的驱动,使用方式如下。
我们创建一个user表,并向其中插入一行数据
import sqlite3 # 导包
try:
# 连接到SQLite3
conn = sqlite3.connect(r'D:\test.db') # 说白了就是把这个文件读取到内存中,如果没有就创建
# 创建一个Cursor,用来执行sql语句:
cursor = conn.cursor()
# 执行一条sql,创建user表
cursor.execute('create table user(id varchar(20) primary key, name varchar(20))') # 表有两列,一列为id,一列为姓名
# 插入一条数据
cursor.execute('insert into user(id, name) values(\'1\', \'zzh\')') # 插入一行数据,id为1,name为zzh
# 查看插入的数据数
print(cursor.rowcount) # rowcount能返回数据库中受影响的行数,因为插入了一行数据,所以返回1
# 通过connect对象提交事务
conn.commit() # 只有提交了事务,数据才真正的被插入到了数据库当中
except Exception as e:
print(e)
conn.rollback() # 出现异常,事务回滚,意思就是再将插入的数据撤销
finally:
# 关闭cursor
cursor.close()
# 关闭数据库连接
conn.close()
查看数据
try:
# 创建连接
conn = sqlite3.connect(r'D:\test.db')
# 创建 cursor 对象
cursor = conn.cursor()
# 查询数据库
cursor.execute('select * from user where id=?', ('1',)) # 问号代表占位符,类似于%s
# 获得查询结果
values = cursor.fetchall() # 通过fetchall函数取得返回的数据
# 打印结果
print(values)
finally:
# 关闭cursor和connect对象
cursor.close()
conn.close()python连接mysql
使用mysql需要下载mysql数据库以及连接mysql需要的驱动。
安装驱动在终端执行
$ pip install mysql-connectorimport mysql.connector # 导入MySQL驱动
# 创建连接
config = {
'host': '数据库所在的电脑的ip地址',
'user': '数据库用户名',
'password': '数据库密码',
'database': '数据库名'
}
# ip默认为127.0.0.1,端口号默认为3306
# conn = mysql.connector.connect(host='数据库所在的电脑的ip地址', user='数据库用户名', password='数据库密码', database='数据库名')
conn = mysql.connector.connect(**config)
#
# # 创建cursor对象
cursor = conn.cursor()
# 创建user表
cursor.execute('create table user (id varchar(20) primary key, name varchar(20))')
# 插入一条数据
cursor.execute('insert into user (id, name) values (%s, %s)', ['1', 'zzh'])
# 查看受影响的行数
print(cursor.rowcount)
# 提交事务
conn.commit()
# 关闭
cursor.close()
# 重新创建
cursor = conn.cursor()
# 查表
cursor.execute('select * from user where id = %s', ('1',))
values = cursor.fetchall()
print(values) # 输出的结果只有字段值,没有对应的字段名,如果先让输出结果是key-value形式
cursor.close() # 在创建cursor对象时要传递cursor_class参数
conn.close() # cursor_class=mysql.connector.cursor.MySQLCursorDict上面的示例存在一个严重的问题,就是我们的插入语句,所插入的内容,我们在写代码的时候往往是不知道的,一般都是用户操作页面,在输入框中输入内容,然后传递到后端,后端接收到值,做一些逻辑处理,然后再存入数据库,所以excute函数还有其他的用法,如下:
#通过tuple方式插入(利用%s作为占位符)
insert2=("insert into user(name,age) values(%s,%s)")
data=('Tom',20)
cursor.execute(insert2,data) #通过dict方式插入(利用%(字段)s作为占位符)
insert3=("insert into user(name,age) values(%(name)s,%(age)s)")
data={
'name':'Tom',
'age':21
}
cursor.execute(insert3,data) #批量插入
insertmany=("insert into user(name,age) values(%s,%s)")
data=[
('Tom1',20),
('Tom2',21),
('Tom3',22)
]
cursor.executemany(insertmany,data)使用SQLAlchemy
SQLAlchemy是一个ORM框架即将实体类与数据库表关联起来,实体类中的一个属性对应着数据库中的一个字段,通过实体类创建出来的对象,就相当于数据库表中的一行数据,所以无论是我们将数据库查询出来的数据,存入实体对象中,还是通过操作实体对象从而达到操作数据库中数据都是非常方便的。
简单使用
首先下载相关模块
pip install sqlalchemy如果已经安装过Anaconda 该模块已经存在,直接使用就好
下面是通过sqlalchemy框架向表中插入数据,然后查询数据
from sqlalchemy import Column, String, create_engine
from sqlalchemy.orm import sessionmaker
from sqlalchemy.ext.declarative import declarative_base
# 创建对象的基类
Base = declarative_base()
# 定义User对象
class User(Base):
# 表的名字
__tablename__ = 'user'
# 表的结构
id = Column(String(20), primary_key=True) # 注意这里的
name = Column(String(20))
# 初始化数据库连接
# mysql 代表数据库类型
# mysqlconnector 代表数据库驱动名
# user替换成数据库用户名
# ip替换成数据库所在的ip地址
# port 替换成端口号,mysql就是3306
engine = create_engine('mysql+mysqlconnector://root:user@ip:port/test')
# 根据上面的配置获得一个创建会话的对象:
DBSession = sessionmaker(bind=engine)
# 通过DBSession创建Session
session = DBSession()
# 创建一个User对象
new_user = User(id='11', name='Bob')
# 添加到session
session.add(new_user)
# 提交事务
session.commit()
# 创建Query查询,filter是where条件,最后调用one()返回唯一行,如果调用all()则返回所有符合条件行:
user = session.query(User).filter(User.name == 'zzh').all()
# 打印类型和对象的name属性:
print('type:', type(user))
for n in user: # 如果调用all()则会返回一个list
print('name:', n.name)
# 关闭Session:
session.close()一对多关联
先看一下数据库表
student表
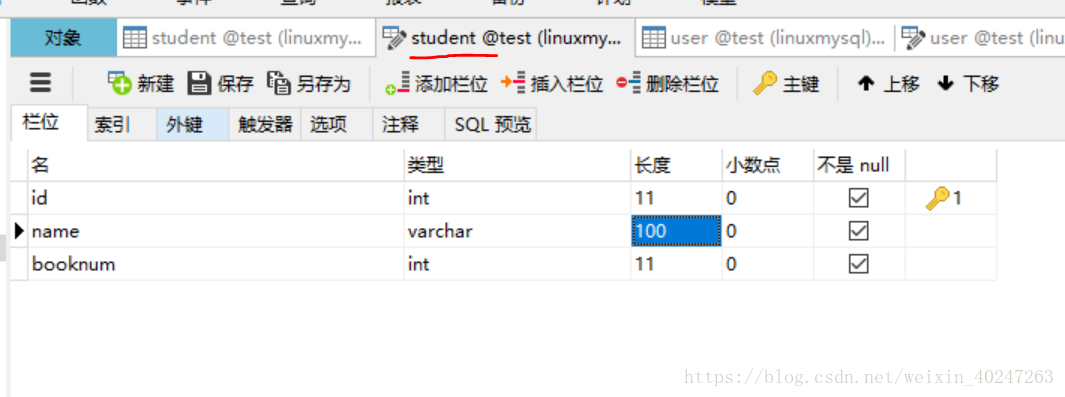
book表
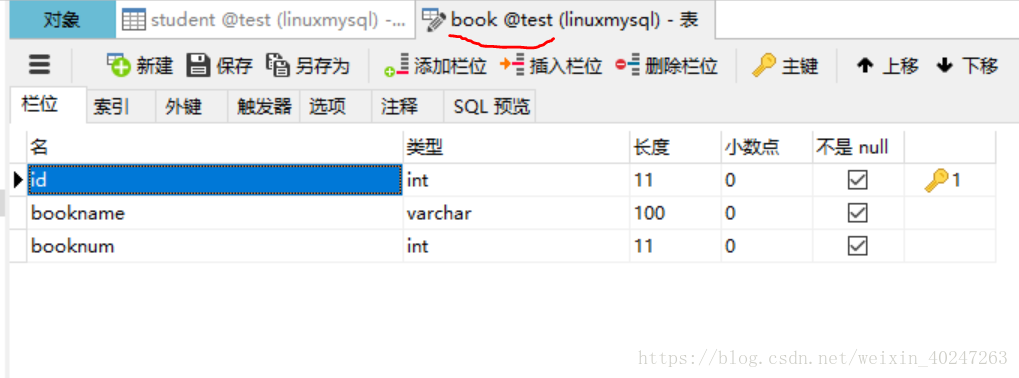
book表的booknum是外键,与studnet表的booknum关联
下面是代码
from sqlalchemy import Column, String, create_engine, ForeignKey, Integer
from sqlalchemy.orm import sessionmaker, relationship
from sqlalchemy.ext.declarative import declarative_base
# 创建对象的基类
Base = declarative_base()
# 定义Student对象
class Student(Base):
# 表的名字
__tablename__ = 'student'
# 表的结构、下面等号左边的变量名一定要和数据库中的字段名一样
id = Column(Integer, primary_key=True)
name = Column(String(20))
booknum = Column(Integer)
# 一对多: 注意relationship中的参数是 关联的对象名,Book而不是类名book
book = relationship('Book') # 含义:将book表中所关联的行数获取到并放入book变量中,名字随便起
# 定义Student对象
class Book(Base):
# 表的名字
__tablename__ = 'book'
# 表的结构
id = Column(Integer, primary_key=True)
bookname = Column(String(20))
# 多对一 通过外键关联
booknum = Column(Integer, ForeignKey('student.booknum'))
# 初始化数据库连接
# mysql 代表数据库类型
# mysqlconnector 代表数据库驱动名
engine = create_engine('mysql+mysqlconnector://root:user@ip:port/test')
# 根据上面的配置获得一个创建会话的对象:
DBSession = sessionmaker(bind=engine)
# 通过DBSession创建Session
session = DBSession()
# 创建Query查询,filter是where条件,最后调用one()返回唯一行,如果调用all()则返回所有行:
student = session.query(Student).filter(Student.name == 'zzh').one()
# 打印类型和对象的name属性:
print('type:', type(student))
print('name:', student.name)
for n in student.book: # student表的booknum字段带出来了book表的多行数据,并存入了studnet.book中
print('books:', n.bookname) # 遍历打印bookname
# 关闭Session:
session.close()运行结果如下:
type: <class '__main__.Student'>
name: zzh
books: java
books: python