数据仓库建设好以后,用户就可以编写Hive SQL语句对其进行访问并对其中数据进行分析。
在实际生产中,究竟需要哪些统计指标通常由数据需求相关部门人员提出,而且会不断有新的统计需求产生,以下为网站流量分析中的一些典型指标示例。
注:每一种统计指标都可以跟各维度表进行钻取。
1. 流量分析1.1. 多维度统计PV总量按时间维度
--计算每小时pvs,注意gruop by语法
select count() as pvs,month,day,hour from ods_weblog_detail group by month,day,hour;
方式一:直接在ods_weblog_detail单表上进行查询
--计算该处理批次(一天)中的各小时pvs
drop table dw_pvs_everyhour_oneday;
create table dw_pvs_everyhour_oneday(month string,day string,hour string,pvs bigint) partitioned by(datestr string);
insert into table dw_pvs_everyhour_oneday partition(datestr='20130918')
select a.month as month,a.day as day,a.hour as hour,count() as pvs from ods_weblog_detail a
where a.datestr='20130918' group by a.month,a.day,a.hour;
--计算每天的pvs
drop table dw_pvs_everyday;
create table dw_pvs_everyday(pvs bigint,month string,day string);
insert into table dw_pvs_everyday
select count() as pvs,a.month as month,a.day as day from ods_weblog_detail a
group by a.month,a.day;
方式二:与时间维表关联查询
--维度:日
drop table dw_pvs_everyday;
create table dw_pvs_everyday(pvs bigint,month string,day string);
insert into table dw_pvs_everyday
select count() as pvs,a.month as month,a.day as day from (select distinct month, day from t_dim_time) a
join ods_weblog_detail b
on a.month=b.month and a.day=b.day
group by a.month,a.day;
--维度:月
drop table dw_pvs_everymonth;
create table dw_pvs_everymonth (pvs bigint,month string);
insert into table dw_pvs_everymonth
select count(*) as pvs,a.month from (select distinct month from t_dim_time) a
join ods_weblog_detail b on a.month=b.month group by a.month;
--另外,也可以直接利用之前的计算结果。比如从之前算好的小时结果中统计每一天的
Insert into table dw_pvs_everyday
Select sum(pvs) as pvs,month,day from dw_pvs_everyhour_oneday group by month,day having day='18';
按终端维度
数据中能够反映出用户终端信息的字段是http_user_agent。
User Agent也简称UA。它是一个特殊字符串头,是一种向访问网站提供所使用的浏览器类型及版本、操作系统及版本、浏览器内核、等信息的标识。例如:
User-Agent,Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.276 Safari/537.36
上述UA信息就可以提取出以下的信息:
chrome 58.0、浏览器 chrome、浏览器版本 58.0、系统平台 windows
浏览器内核 webkit
这里不再拓展相关知识,感兴趣的可以查看参考资料如何解析UA。
可以用下面的语句进行试探性统计,当然这样的准确度不是很高。
select distinct(http_user_agent) from ods_weblog_detail where http_user_agent like '%Chrome%' limit 200;
按栏目维度
网站栏目可以理解为网站中内容相关的主题集中。体现在域名上来看就是不同的栏目会有不同的二级目录。比如某网站网址为www.xxxx.cn,旗下栏目可以通过如下方式访问:
栏目维度:../job
栏目维度:../news
栏目维度:../sports
栏目维度:../technology
那么根据用户请求url就可以解析出访问栏目,然后按照栏目进行统计分析。
按referer维度
--统计每小时各来访url产生的pv量
drop table dw_pvs_referer_everyhour;
create table dw_pvs_referer_everyhour(referer_url string,referer_host string,month string,day string,hour string,pv_referer_cnt bigint) partitioned by(datestr string);
insert into table dw_pvs_referer_everyhour partition(datestr='20130918')
select http_referer,ref_host,month,day,hour,count(1) as pv_referer_cnt
from ods_weblog_detail
group by http_referer,ref_host,month,day,hour
having ref_host is not null
order by hour asc,day asc,month asc,pv_referer_cnt desc;
--统计每小时各来访host的产生的pv数并排序
drop table dw_pvs_refererhost_everyhour;
create table dw_pvs_refererhost_everyhour(ref_host string,month string,day string,hour string,ref_host_cnts bigint) partitioned by(datestr string);
insert into table dw_pvs_refererhost_everyhour partition(datestr='20130918')
select ref_host,month,day,hour,count(1) as ref_host_cnts
from ods_weblog_detail
group by ref_host,month,day,hour
having ref_host is not null
order by hour asc,day asc,month asc,ref_host_cnts desc;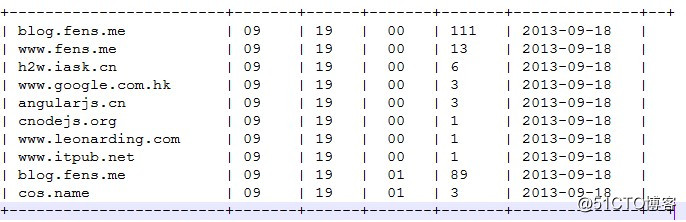
注:还可以按来源地域维度、访客终端维度等计算
1.2. 人均浏览量
需求描述:统计今日所有来访者平均请求的页面数。
人均浏览量也称作人均浏览页数,该指标可以说明网站对用户的粘性。
人均页面浏览量表示用户某一时段平均浏览页面的次数。
计算方式:总页面请求数/去重总人数
remote_addr表示不同的用户。可以先统计出不同remote_addr的pv量,然后累加(sum)所有pv作为总的页面请求数,再count所有remote_addr作为总的去重总人数。
--总页面请求数/去重总人数
drop table dw_avgpv_user_everyday;
create table dw_avgpv_user_everyday(
day string,
avgpv string);
insert into table dw_avgpv_user_everyday
select '20130918',sum(b.pvs)/count(b.remote_addr) from
(select remote_addr,count(1) as pvs from ods_weblog_detail where datestr='20130918' group by remote_addr) b;
1.3. 统计pv总量最大的来源TOPN (分组TOP)
需求描述:统计每小时各来访host的产生的pvs数最多的前N个(topN)。
row_number()函数
Ø 语法:row_number() over (partition by xxx order by xxx) rank,rank为分组的别名,相当于新增一个字段为rank。
Ø partition by用于分组,比方说依照sex字段分组
Ø order by用于分组内排序,比方说依照sex分组,组内按照age排序
Ø 排好序之后,为每个分组内每一条分组记录从1开始返回一个数字
Ø 取组内某个数据,可以使用where 表名.rank>x之类的语法去取
以下语句对每个小时内的来访host次数倒序排序标号:
select ref_host,ref_host_cnts,concat(month,day,hour),
row_number() over (partition by concat(month,day,hour) order by ref_host_cnts desc) as od from dw_pvs_refererhost_everyhour;
效果如下:
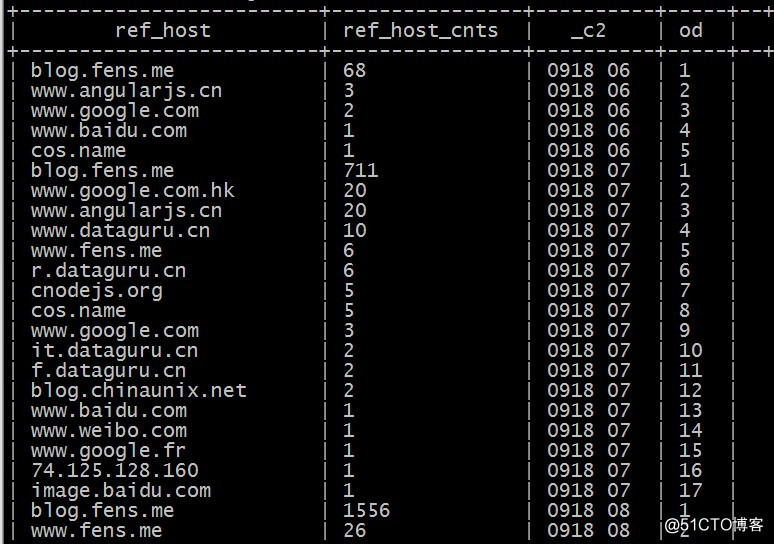
根据上述row_number的功能,可编写hql取各小时的ref_host访问次数topn
drop table dw_pvs_refhost_topn_everyhour;
create table dw_pvs_refhost_topn_everyhour(
hour string,
toporder string,
ref_host string,
ref_host_cnts string
)partitioned by(datestr string);
insert into table dw_pvs_refhost_topn_everyhour partition(datestr='20130918')
select t.hour,t.od,t.ref_host,t.ref_host_cnts from
(select ref_host,ref_host_cnts,concat(month,day,hour) as hour,
row_number() over (partition by concat(month,day,hour) order by ref_host_cnts desc) as od
from dw_pvs_refererhost_everyhour) t where od<=3;
结果如下: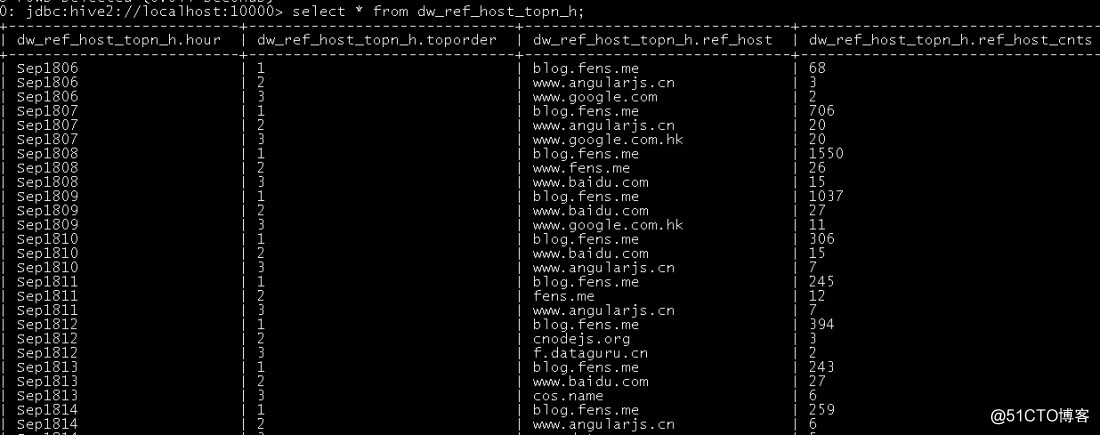
2. 受访分析(从页面的角度分析)2.1. 各页面访问统计
主要是针对数据中的request进行统计分析,比如各页面PV ,各页面UV 等。
以上指标无非就是根据页面的字段group by。例如:
--统计各页面pv
select request as request,count(request) as request_counts from
ods_weblog_detail group by request having request is not null order by request_counts desc limit 20;
2.2. 热门页面统计
--统计每日最热门的页面top10
drop table dw_hotpages_everyday;
create table dw_hotpages_everyday(day string,url string,pvs string);
insert into table dw_hotpages_everyday
select '20130918',a.request,a.request_counts from
(select request as request,count(request) as request_counts from ods_weblog_detail where datestr='20130918' group by request having request is not null) a
order by a.request_counts desc limit 10;
3. 访客分析
3.1. 独立访客
需求描述:按照时间维度比如小时来统计独立访客及其产生的pv。
对于独立访客的识别,如果在原始日志中有用户标识,则根据用户标识即很好实现;此处,由于原始日志中并没有用户标识,以访客IP来模拟,技术上是一样的,只是精确度相对较低。
--时间维度:时
drop table dw_user_dstc_ip_h;
create table dw_user_dstc_ip_h(
remote_addr string,
pvs bigint,
hour string);
insert into table dw_user_dstc_ip_h
select remote_addr,count(1) as pvs,concat(month,day,hour) as hour
from ods_weblog_detail
Where datestr='20130918'
group by concat(month,day,hour),remote_addr;
在此结果表之上,可以进一步统计,如每小时独立访客总数:
select count(1) as dstc_ip_cnts,hour from dw_user_dstc_ip_h group by hour;
--时间维度:日
select remote_addr,count(1) as counts,concat(month,day) as day
from ods_weblog_detail
Where datestr='20130918'
group by concat(month,day),remote_addr;
--时间维度:月
select remote_addr,count(1) as counts,month
from ods_weblog_detail
group by month,remote_addr;
3.2. 每日新访客
需求:将每天的新访客统计出来。
实现思路:创建一个去重访客累积表,然后将每日访客对比累积表。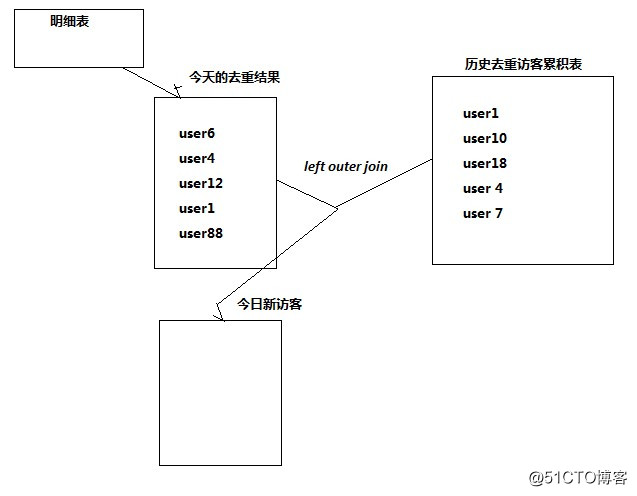
--历日去重访客累积表
drop table dw_user_dsct_history;
create table dw_user_dsct_history(
day string,
ip string
)
partitioned by(datestr string);
--每日新访客表
drop table dw_user_new_d;
create table dw_user_new_d (
day string,
ip string
)
partitioned by(datestr string);
--每日新用户插入新访客表
insert into table dw_user_new_d partition(datestr='20130918')
select tmp.day as day,tmp.today_addr as new_ip from
(
select today.day as day,today.remote_addr as today_addr,old.ip as old_addr
from
(select distinct remote_addr as remote_addr,"20130918" as day from ods_weblog_detail where datestr="20130918") today
left outer join
dw_user_dsct_history old
on today.remote_addr=old.ip
) tmp
where tmp.old_addr is null;
--每日新用户追加到累计表
insert into table dw_user_dsct_history partition(datestr='20130918')
select day,ip from dw_user_new_d where datestr='20130918';
验证查看:
select count(distinct remote_addr) from ods_weblog_detail;
select count(1) from dw_user_dsct_history where datestr='20130918';
select count(1) from dw_user_new_d where datestr='20130918';
注:还可以按来源地域维度、访客终端维度等计算
4. 访客Visit分析(点击流模型)
4.1. 回头/单次访客统计
需求:查询今日所有回头访客及其访问次数。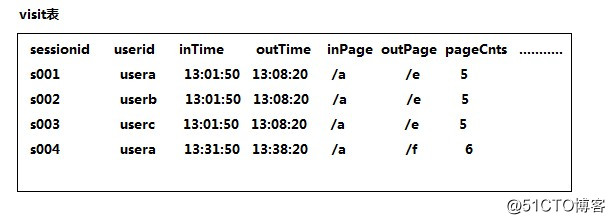
实现思路:上表中出现次数>1的访客,即回头访客;反之,则为单次访客。
drop table dw_user_returning;
create table dw_user_returning(
day string,
remote_addr string,
acc_cnt string)
partitioned by (datestr string);
insert overwrite table dw_user_returning partition(datestr='20130918')
select tmp.day,tmp.remote_addr,tmp.acc_cnt
from
(select '20130918' as day,remote_addr,count(session) as acc_cnt from ods_click_stream_visit group by remote_addr) tmp
where tmp.acc_cnt>1;
4.2. 人均访问频次
需求:统计出每天所有用户访问网站的平均次数(visit)
总visit数/去重总用户数
select sum(pagevisits)/count(distinct remote_addr) from ods_click_stream_visit where datestr='20130918';
5. 关键路径转化率分析(漏斗模型)
5.1. 需求分析
转化:在一条指定的业务流程中,各个步骤的完成人数及相对上一个步骤的百分比。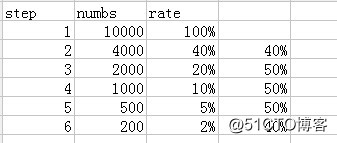
5.2. 模型设计
定义好业务流程中的页面标识,下例中的步骤为:
Step1、 /item
Step2、 /category
Step3、 /index
Step4、 /order
5.3. 开发实现
l 查询每一个步骤的总访问人数
--查询每一步人数存入dw_oute_numbs
create table dw_oute_numbs as
select 'step1' as step,count(distinct remote_addr) as numbs from ods_click_pageviews where datestr='20130920' and request like '/item%'
union
select 'step2' as step,count(distinct remote_addr) as numbs from ods_click_pageviews where datestr='20130920' and request like '/category%'
union
select 'step3' as step,count(distinct remote_addr) as numbs from ods_click_pageviews where datestr='20130920' and request like '/order%'
union
select 'step4' as step,count(distinct remote_addr) as numbs from ods_click_pageviews where datestr='20130920' and request like '/index%';
注:UNION将多个SELECT语句的结果集合并为一个独立的结果集。
l 查询每一步骤相对于路径起点人数的比例
思路:级联查询,利用自join
--dw_oute_numbs跟自己join
select rn.step as rnstep,rn.numbs as rnnumbs,rr.step as rrstep,rr.numbs as rrnumbs from dw_oute_numbs rn
inner join
dw_oute_numbs rr;
--每一步的人数/第一步的人数==每一步相对起点人数比例
select tmp.rnstep,tmp.rnnumbs/tmp.rrnumbs as ratio
from
(
select rn.step as rnstep,rn.numbs as rnnumbs,rr.step as rrstep,rr.numbs as rrnumbs from dw_oute_numbs rn
inner join
dw_oute_numbs rr) tmp
where tmp.rrstep='step1';
l 查询每一步骤相对于上一步骤的漏出率
--自join表过滤出每一步跟上一步的记录
select rn.step as rnstep,rn.numbs as rnnumbs,rr.step as rrstep,rr.numbs as rrnumbs from dw_oute_numbs rn
inner join
dw_oute_numbs rr
where cast(substr(rn.step,5,1) as int)=cast(substr(rr.step,5,1) as int)-1;
select tmp.rrstep as step,tmp.rrnumbs/tmp.rnnumbs as leakage_rate
from
(
select rn.step as rnstep,rn.numbs as rnnumbs,rr.step as rrstep,rr.numbs as rrnumbs from dw_oute_numbs rn
inner join
dw_oute_numbs rr) tmp
where cast(substr(tmp.rnstep,5,1) as int)=cast(substr(tmp.rrstep,5,1) as int)-1;
l 汇总以上两种指标
select abs.step,abs.numbs,abs.rate as abs_ratio,rel.rate as leakage_rate
from
(
select tmp.rnstep as step,tmp.rnnumbs as numbs,tmp.rnnumbs/tmp.rrnumbs as rate
from
(
select rn.step as rnstep,rn.numbs as rnnumbs,rr.step as rrstep,rr.numbs as rrnumbs from dw_oute_numbs rn
inner join
dw_oute_numbs rr) tmp
where tmp.rrstep='step1'
) abs
left outer join
(
select tmp.rrstep as step,tmp.rrnumbs/tmp.rnnumbs as rate
from
(
select rn.step as rnstep,rn.numbs as rnnumbs,rr.step as rrstep,rr.numbs as rrnumbs from dw_oute_numbs rn
inner join
dw_oute_numbs rr) tmp
where cast(substr(tmp.rnstep,5,1) as int)=cast(substr(tmp.rrstep,5,1) as int)-1
) rel
on abs.step=rel.step;