爬虫策略制定
1、 从东方财富网中获取(http://quote.eastmoney.com/stocklist.html)股票代码
2、 从网易财经中可以直接下载csv格式文件,地址类似于http://quotes.money.163.com/trade/lsjysj_600508.html#01b07
3、 两个网站都不需要cookie,很好爬,注意控制访问时间间隔就可以,爬信息不要太暴力了
4、 东方财富网中获取的股票代码中好多都是基金的代码(如1 、5 、等开头),这类基金在网易财经中无法获得数据,故要ban掉这些股票代码
获取股票代码
这里要用到beautifulsoup,pip install bs4
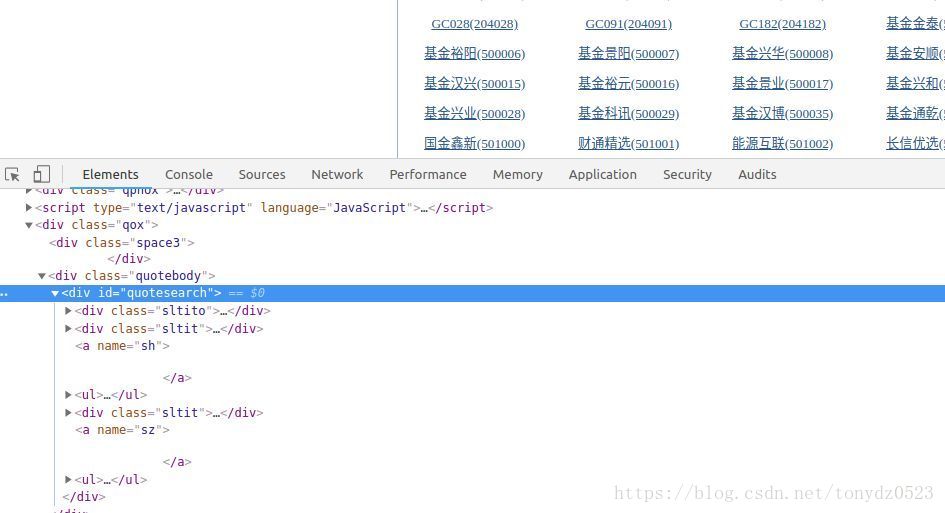
所有的股票代码都在 <div id="quotesearch"> 下的 两个 <ul> 标签下的 <a> 标签中;
获取的股票代码存储到本地txt ,或者存储到redis数据数据库中, 方便分布式爬取或是中途停止重新爬取
redis安装可以看这里:https://blog.csdn.net/tonydz0523/article/details/82493480
代码如下:
import requests
import random
from bs4 import BeautifulSoup as bs
import time
import redis
def get_stock_names():
"""
通过东方财富网上爬取股票的名称代码,并存入redis数据库和本地txt文档
"""
rds = redis.from_url('redis://:[email protected]:6379', db=1, decode_responses=True) # 连接redis db1
url = "http://quote.eastmoney.com/stocklist.html"
headers = {
'Referer': 'http://quote.eastmoney.com',
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36'
}
response = requests.get(url, headers=headers).content.decode('gbk') # 网站编码为gbk 需要解码
soup = bs(response, 'lxml')
all_ul = soup.find('div', id='quotesearch').find_all('ul') # 获取两个ul 标签数据
with open('stock_names.txt', 'w+', encoding='utf-8') as f:
for ul in all_ul:
all_a = ul.find_all('a') # 获取ul 下的所有的a 标签
for a in all_a:
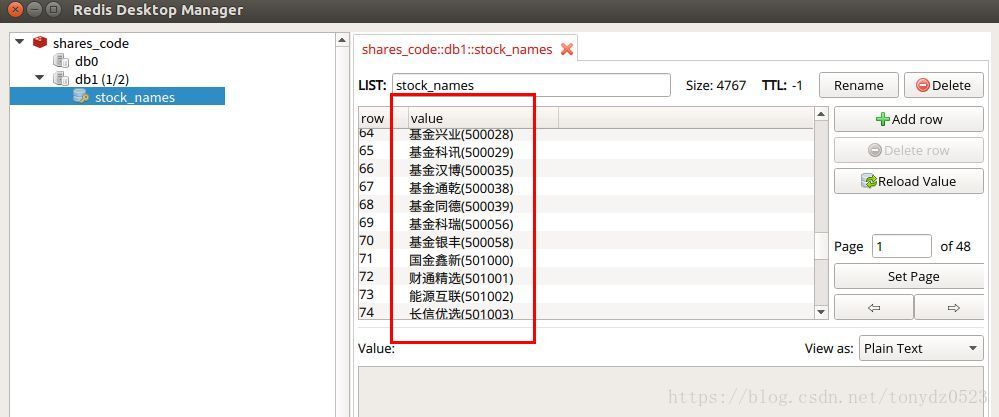
rds.rpush('stock_names', a.text) # a.text 为a标签中的text数据 rpush将数据右侧插入数据库
f.write(a.text + '\n')
redis 中的数据:
获取股票历史数据
分析网页:
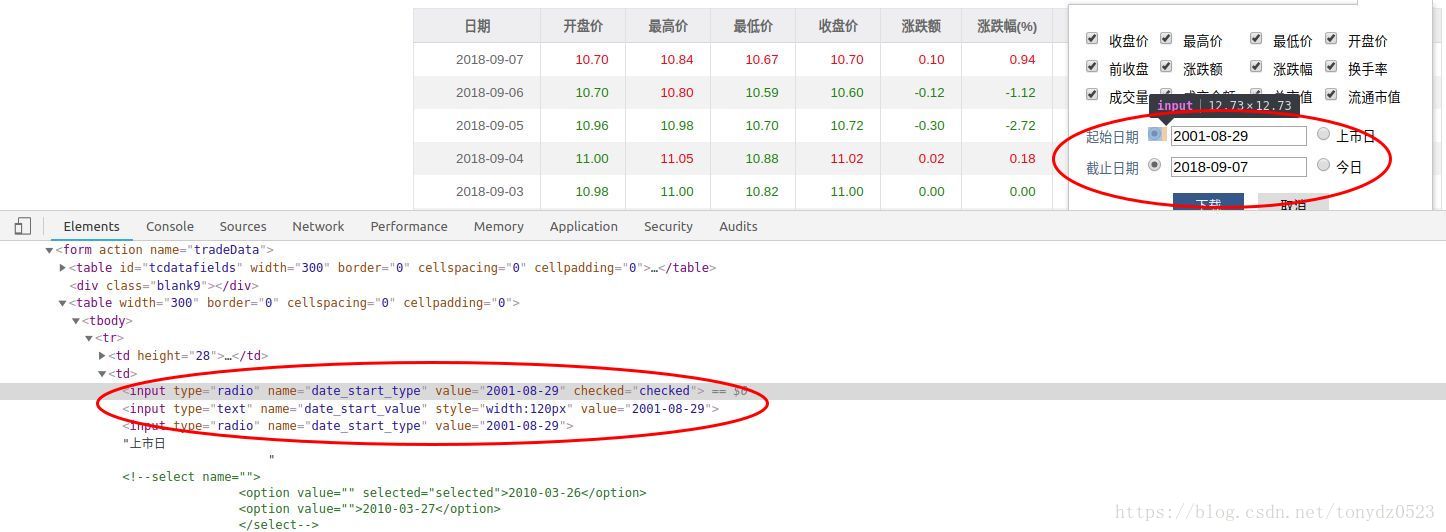
这里可获取股票的时间信息,name="date_start_type"&name="date_end_type"的 <input>标签下的value值
stock_url = 'http://quotes.money.163.com/trade/lsjysj_{}.html'.format(stock_code)
respones = requests.get(stock_url, headers=headers).text
soup = bs(respones, 'lxml')
start_time = soup.find('input', {'name': 'date_start_type'}).get('value').replace('-', '')
end_time = soup.find('input', {'name': 'date_end_type'}).get('value').replace('-', '')我们点击下载,响应如下图:

可见我们只要知道code ,start ,end 参数就可以获取到数据,另,这里的code与我们获取到的有些许差别,这里的code沪市的前面多一个0,深市的前面都一个1
代码如下:
def get_data():
headers = {
'Referer': 'http://quotes.money.163.com/',
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36'
}
while True:
stock_name = rds.lpop('stock_names') # redis上获取 股票名
# for stock_name in stock_names:
if stock_name:
try:
stock_code = stock_name.split('(')[1].split(')')[0]
# 由于东方财富网上获取的代码一部分为基金,无法获取数据,故将基金剔除掉。
# 沪市股票以6,9开头,深市以0,2,3开头,但是部分基金也是2开头,201/202/203/204这些也是基金
# 另外获取data的网址股票代码 沪市前加0, 深市前加1
if int(stock_code[0]) in [0, 2, 3, 6, 9]:
if int(stock_code[0]) in [6, 9]:
stock_code_new = '0' + stock_code
elif int(stock_code[0]) in [0, 2, 3]:
if not int(stock_code[:3]) in [201, 202, 203, 204]:
stock_code_new = '1' + stock_code
else: continue
else: continue
else: continue
stock_url = 'http://quotes.money.163.com/trade/lsjysj_{}.html'.format(stock_code)
respones = requests.get(stock_url, headers=headers).text
soup = bs(respones, 'lxml')
start_time = soup.find('input', {'name': 'date_start_type'}).get('value').replace('-', '') # 获取起始时间
end_time = soup.find('input', {'name': 'date_end_type'}).get('value').replace('-', '') # 获取结束时间
time.sleep(random.choice([1, 2])) # 两次访问之间休息1-2秒
download_url = "http://quotes.money.163.com/service/chddata.html?code={}&start={}&end={}&fields=TCLOSE;HIGH;LOW;TOPEN;LCLOSE;CHG;PCHG;TURNOVER;VOTURNOVER;VATURNOVER;TCAP;MCAP".format(stock_code_new, start_time, end_time)
data = requests.get(download_url, headers=headers)
with open('stock_data/{}.csv'.format(stock_name), 'wb') as f: #保存数据
for chunk in data.iter_content(chunk_size=10000):
if chunk:
f.write(chunk)
print("{}数据已经下载完成".format(stock_name))
except Exception as e:
rds.rpush('stock_names', stock_name)
print(e)
else:break大功告成:
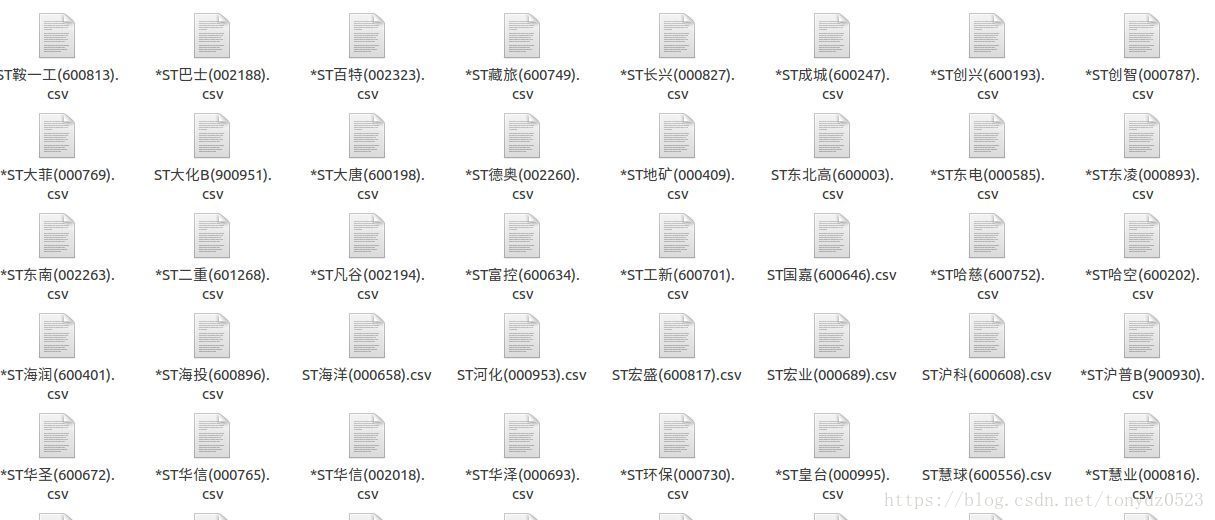
这样就把数据下载到本地了,不过这样操作数据很不方便,下一篇我会写如何把这些csv文件导入到mysql数据库中。
参考:https://blog.csdn.net/pythoncodez/article/details/77623287