此笔博文是上篇的后续
爬取时间:2020-03-27
爬取难度:★★★★☆☆
请求链接:https://wp.m.163.com/163/page/news/virus_report/index.html?_nw_=1&_anw_=1
爬取目标:爬取该网站上我国以及世界各国的历史总数数据(确诊、治愈、死亡等信息)并保存为 CSV 文件
涉及知识:requests、json、time、CSV储存、pandas等。
上一篇讲到了当日数据的爬取,这篇我们继续讲解怎样爬取历史总数据
获取疫情相关信息2
一、爬取历史数据
1、爬取全国历史数据
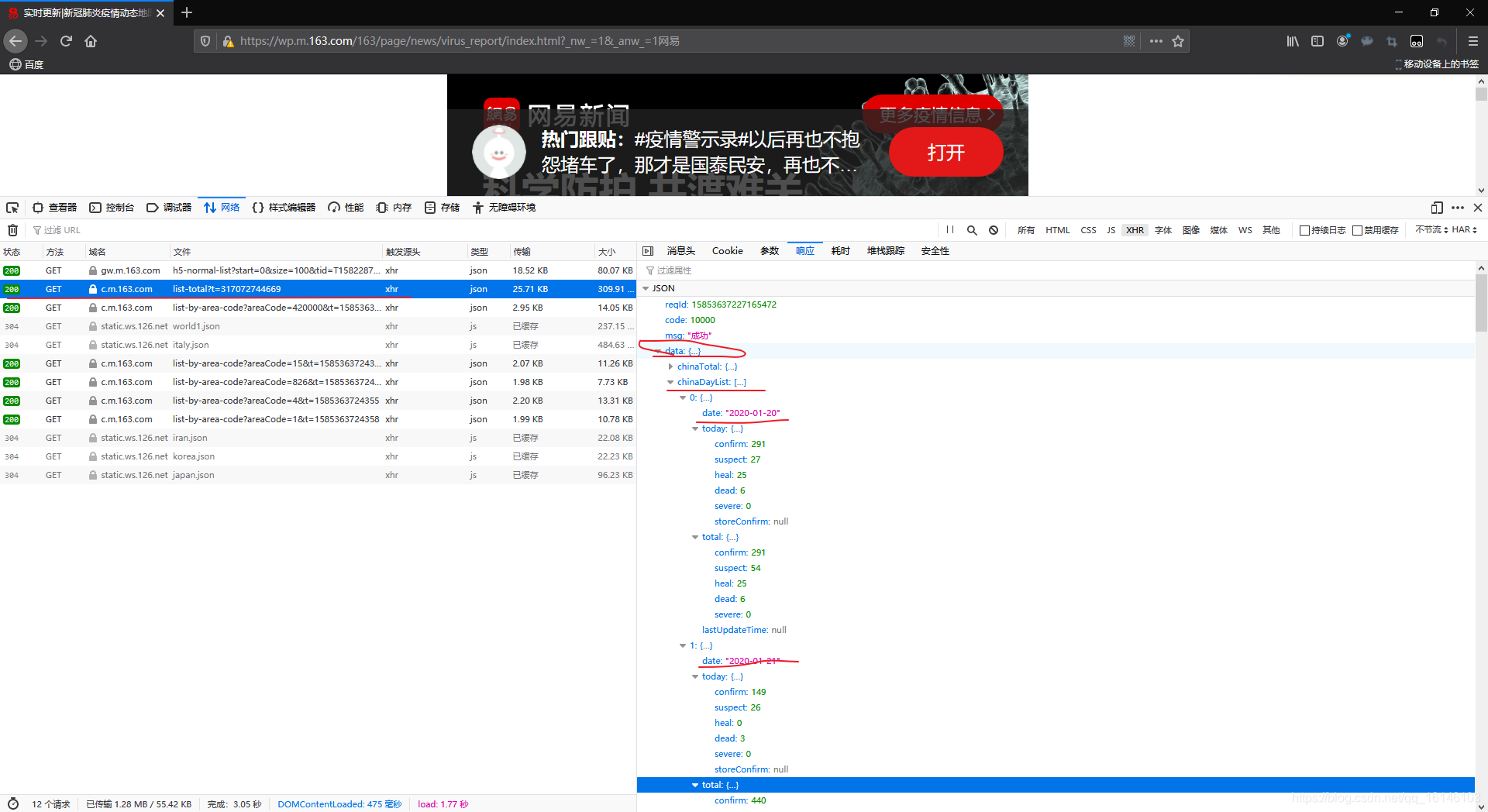
根据上图,我们可以看到在数据data中,总共有四个键,其中chinaDayList存放着中国的历史数据。
下面我们先看一下格式:
chinaDayList = data['chinaDayList'] # 取出
type(chinaDayList)

我们可以看到chinaDayList为列表形式。
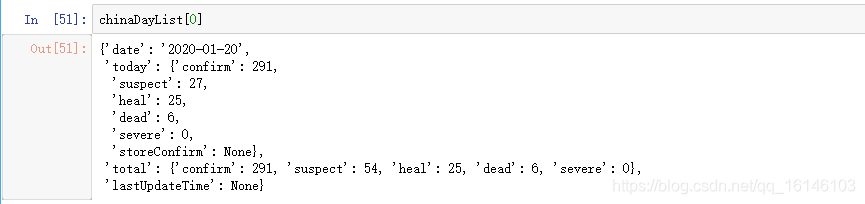
从上图可以看到today、total中也嵌套着字典,因此直接使用定义好的方法从chinaDayList中提取全国历史数据。
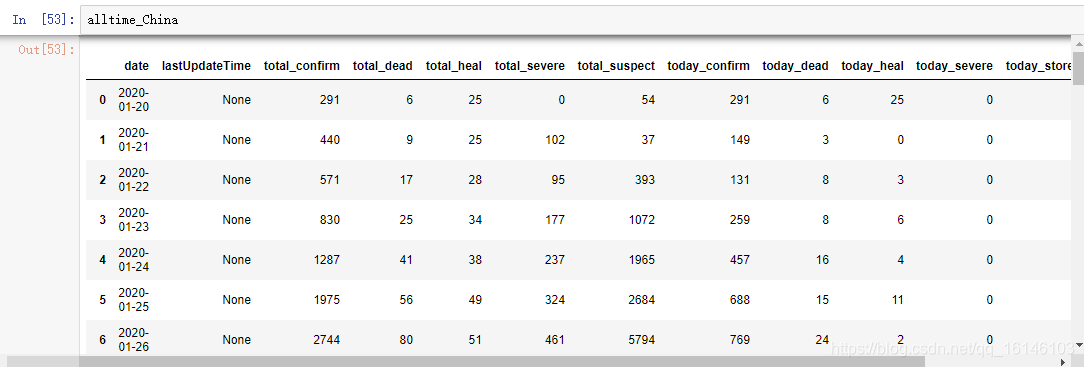
alltime_China = get_data(chinaDayList,['date','lastUpdateTime'])
alltime_China
2、爬取各省历史数据
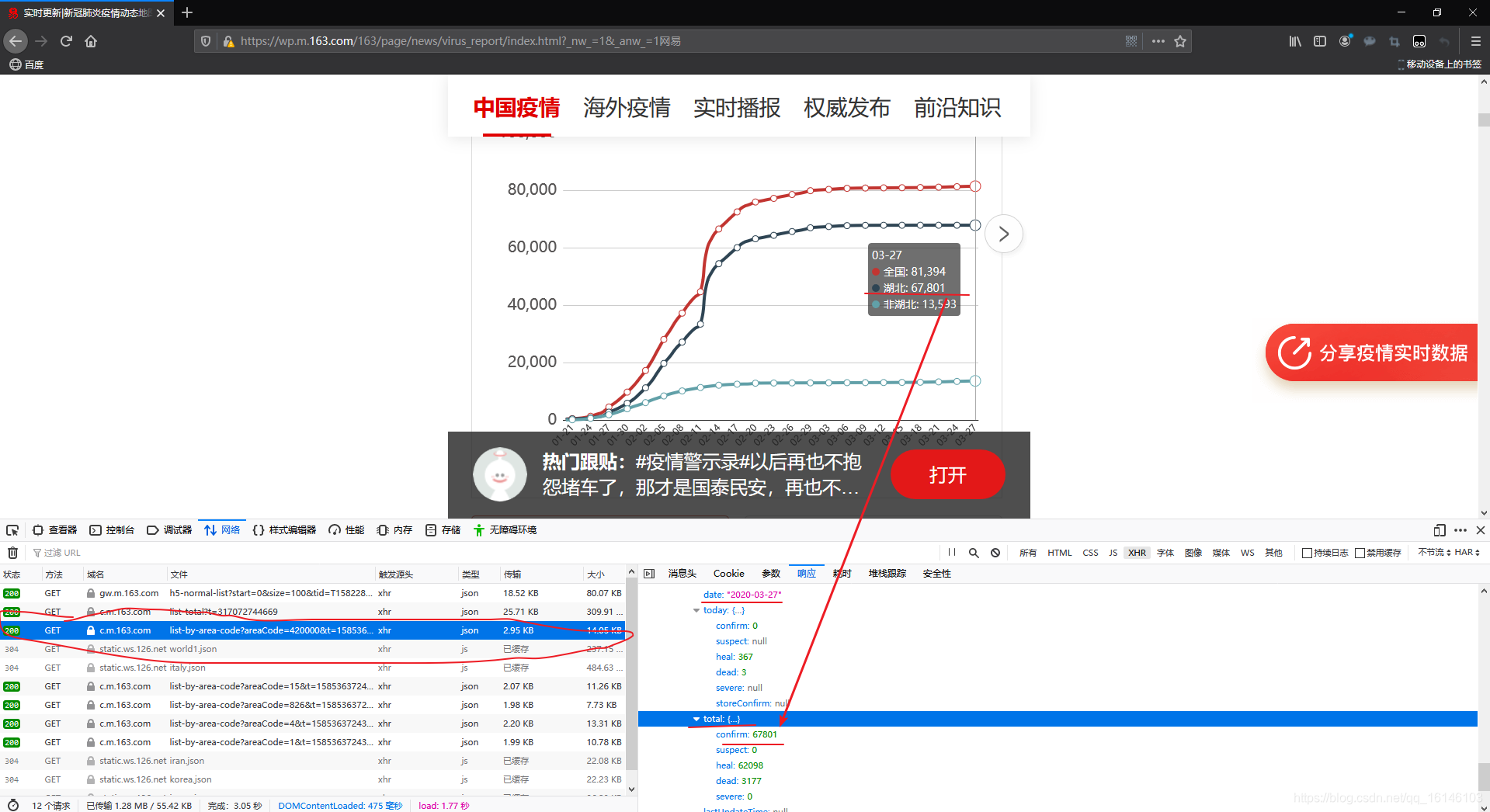
由上图我们可以看到湖北省的历史数据。
我们先以获取湖北省的历史数据为例:
url = 'https://c.m.163.com/ug/api/wuhan/app/data/list-by-area-code?areaCode=420000' # 定义数据地址
r = requests.get(url, headers=headers) # 进行请求
data_json = json.loads(r.text) # 获取json数据
同时我们看到数据都在list内

我们下面先尝试获取一天的内容:

我们可以看出一个省一天的的数据格式如上,这和之前的数据结构一样,因此可以使用之前的方法得到数据。
data_hubei = get_data(json_hubei['data']['list'],['date'])
data_hubei['name'] = '湖北省'
data_hubei
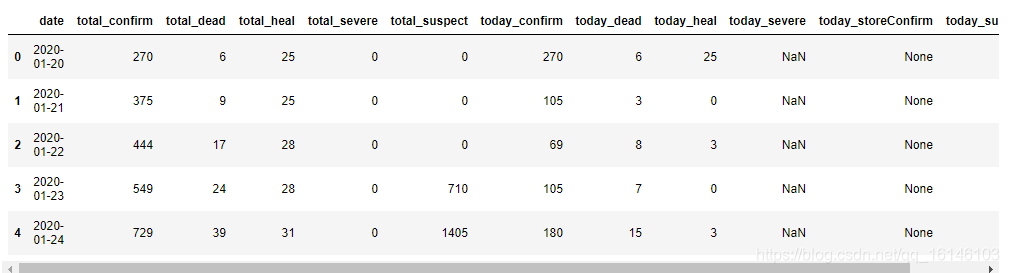
既然一个省的数据这样就可以得到了,那么怎样才能得到我们每个省的历史数据呢?
我们在湖北省历史数据的地址中,我们发现参数aeraCode=420000,而这刚好和全国各省实时数据today_province中的id对应,那么我们可以看一下:
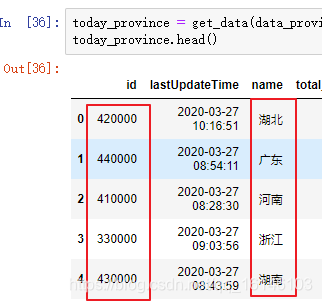
通过上图我们可以看到每个省都对应着不同的ID,是否真的如我们所想的一样,我们看一下各省的行政代码:
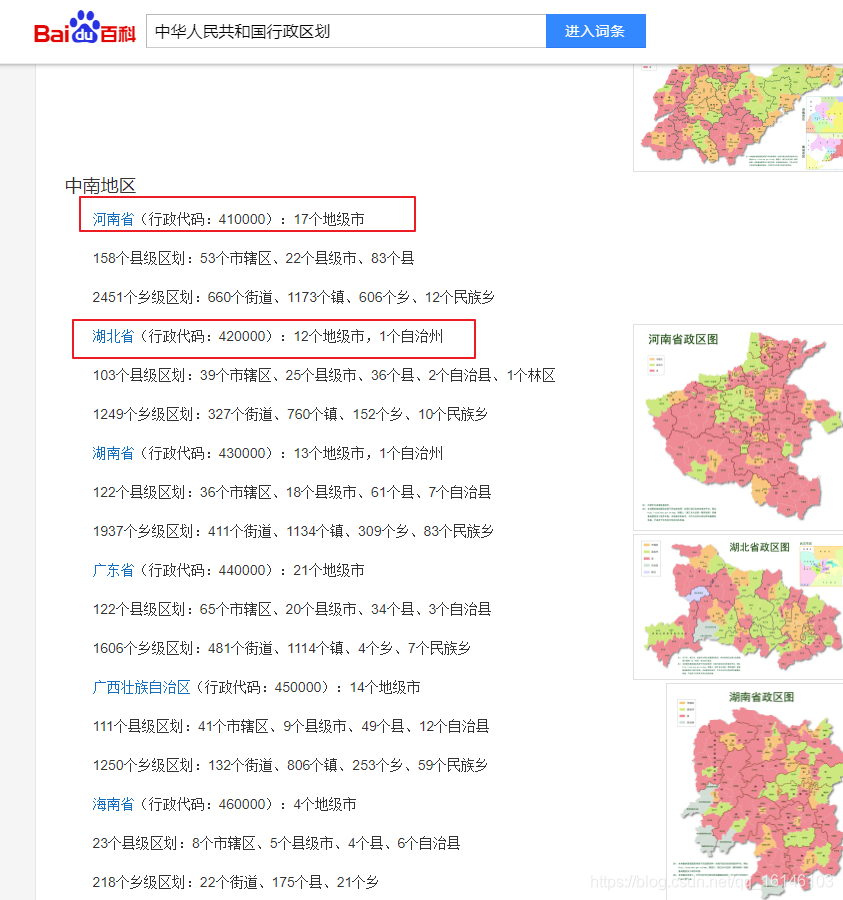
由此我们可以确定编号为各省的行政区划。
那么,各省的ID我们也可以知道怎样拼接了:
'https://c.m.163.com/ug/api/wuhan/app/data/list-by-area-code?areaCode='+ id
为了方便,我们可以生成一个字典:
province_dict = { num:name for num ,name in zip(today_province['id'],today_province['name'])}
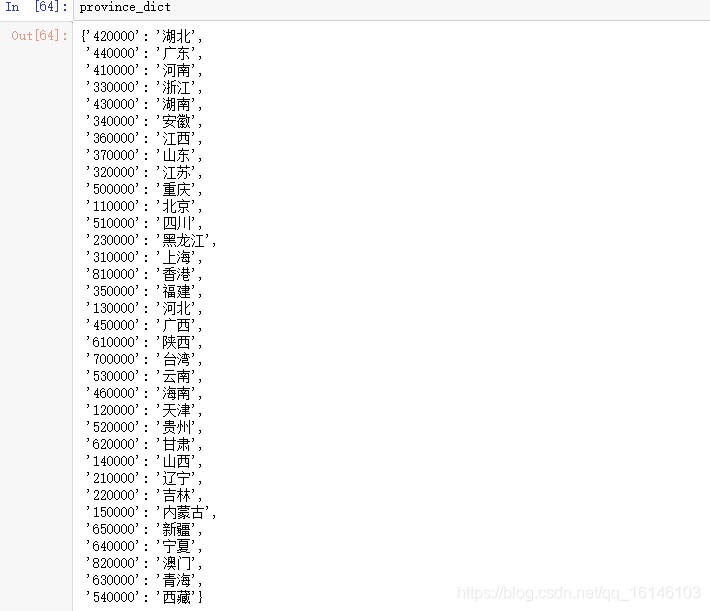
因为每一个省的列名是相同的,所以多个省的数据合并起来就可以存入一个数据中
start = time.time()
for province_id in province_dict: # 遍历各省编号
try:
# 按照省编号访问每个省的数据地址,并获取json数据
url = 'https://c.m.163.com/ug/api/wuhan/app/data/list-by-area-code?areaCode='+province_id
r = requests.get(url, headers=headers)
data_json = json.loads(r.text)
# 提取各省数据,然后写入各省名称
province_data = get_data(data_json['data']['list'],['date'])
province_data['name'] = province_dict[province_id]
# 合并数据
if province_id == '420000':
alltime_province = province_data
else:
alltime_province = pd.concat([alltime_province,province_data])
print('-'*20,province_dict[province_id],'成功',
province_data.shape,alltime_province.shape,
',累计耗时:',round(time.time()-start),'-'*20)
# 设置延迟等待
time.sleep(20)
except:
print('-'*20,province_dict[province_id],'wrong','-'*20)
运行如果成功会出现下图:

3、爬取世界各国的数据
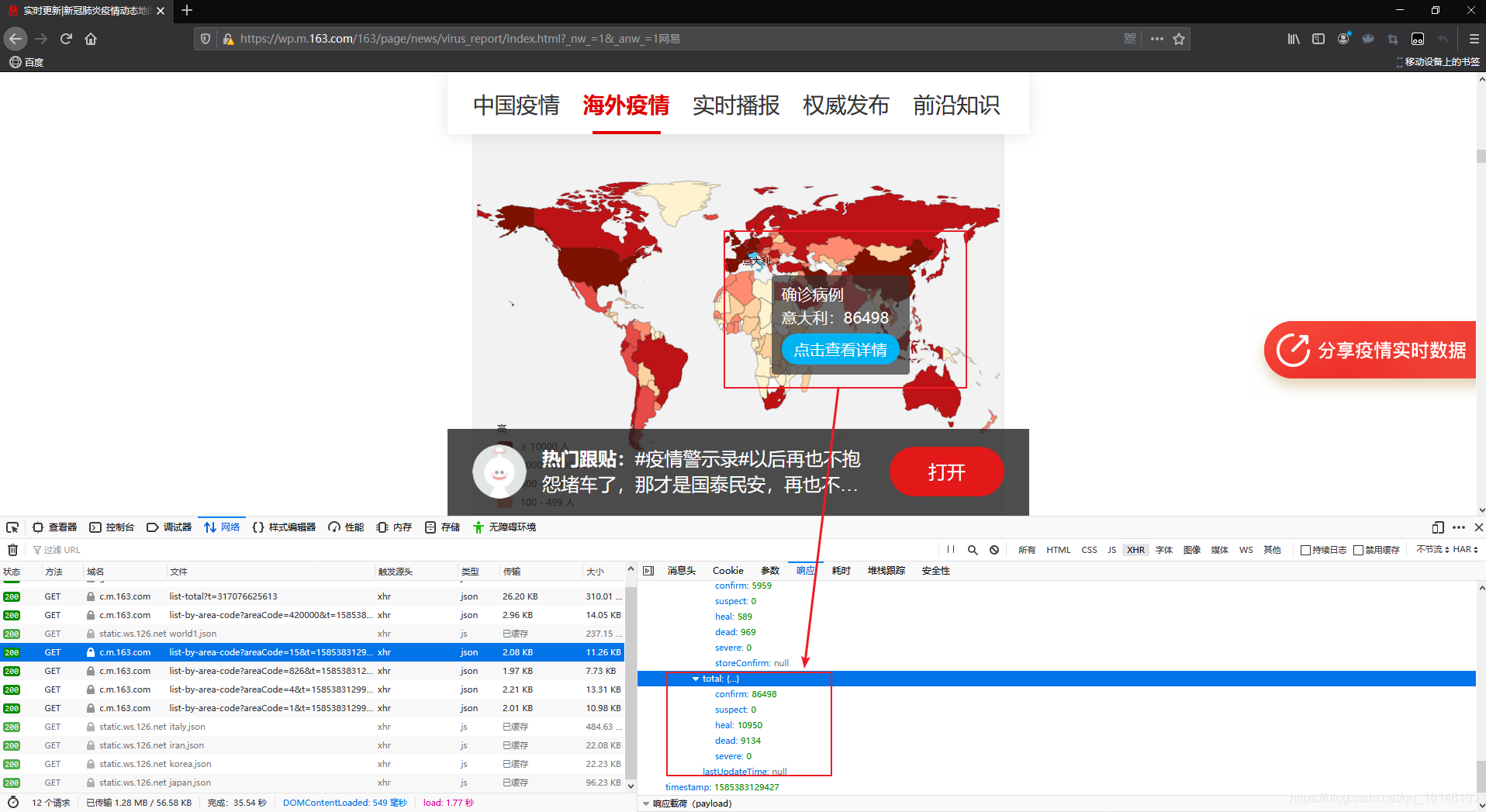
通过对比,我们找到了意大利的数据:
我们还是先以一个国家为例:
url_italy = 'https://c.m.163.com/ug/api/wuhan/app/data/list-by-area-code?areaCode=15' # 意大利的数据地址
r = requests.get(url_italy, headers=headers) # 进行访问
italy_json = json.loads(r.text) # 导出json数据
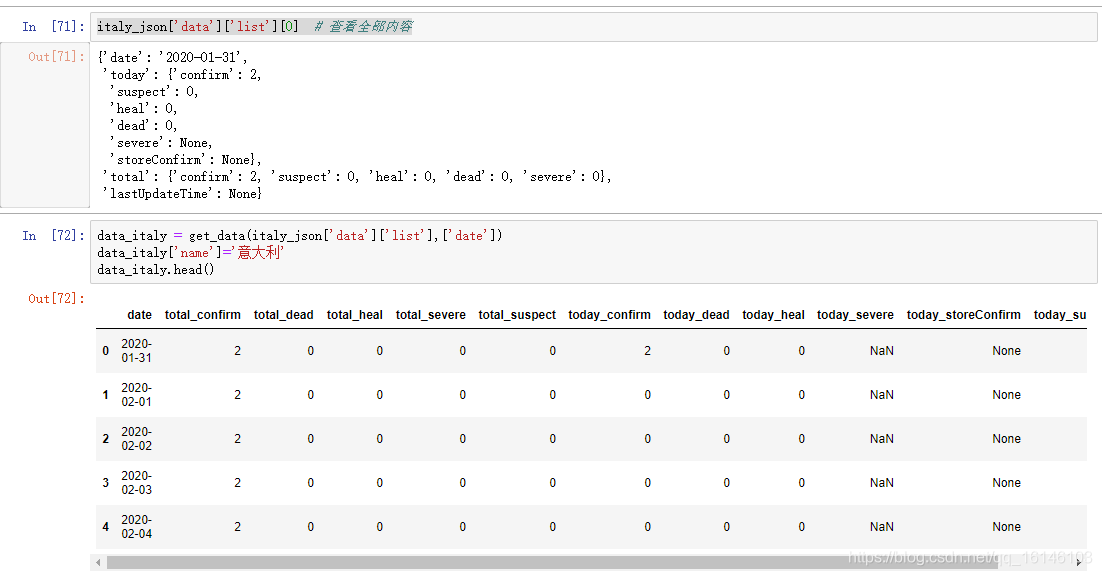
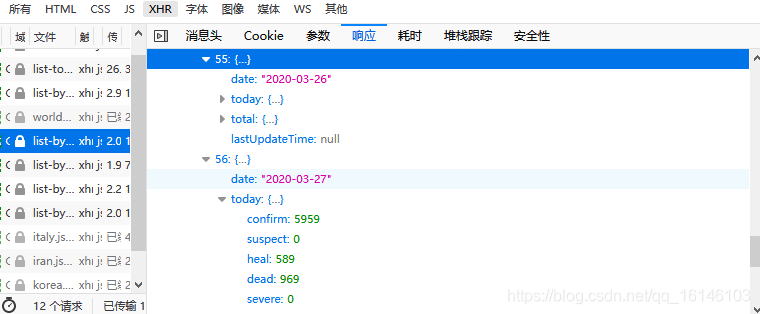
经过观察,我们发现世界各国的历史数据与我国各省的总历史数据相似。因此使用定义好的方法生成数据,然后把国家名称写入数据。
data_italy = get_data(italy_json['data']['list'],['date']) # 生成数据
data_italy['name'] = '意大利' # 写入国家名称
data_italy.head()
又因为原始数据中没有国家名称,为了得到每个国家的名称,需要生成国家编号和国家名称的键值对,这样就可以存储国家名称,在之前的世界各国实时数据today_world中有国家的编号和名称,可以用它来生成键值对。
country_dict = {key:value for key,value in zip(today_world['id'], today_world['name'])}
下面我们来查看下是不是我们想要的结果:
country_dict

得到的结果是我们想要的。
下面我们要做的就是通过每个国家的编号访问每个国家历史数据的地址,然后获取每一个国家的历史数据。
start = time.time()
for country_id in country_dict: # 遍历每个国家的编号
try:
# 按照编号访问每个国家的数据地址,并获取json数据
url = 'https://c.m.163.com/ug/api/wuhan/app/data/list-by-area-code?areaCode='+country_id
r = requests.get(url, headers=headers)
json_data = json.loads(r.text)
# 生成每个国家的数据
country_data = get_data(json_data['data']['list'],['date'])
country_data['name'] = country_dict[country_id]
# 数据叠加
if country_id == '9577772':
alltime_world = country_data
else:
alltime_world = pd.concat([alltime_world,country_data])
print('-'*20,country_dict[country_id],'成功',country_data.shape,alltime_world.shape,
',累计耗时:',round(time.time()-start),'-'*20)
time.sleep(10)
except:
print('-'*20,country_dict[country_id],'wrong','-'*20)
最后运行成功的截图如下:

二、完整代码
- 中国:
# =============================================
# --*-- coding: utf-8 --*--
# @Time : 2020-03-27
# @Author : 不温卜火
# @CSDN : https://blog.csdn.net/qq_16146103
# @FileName: All collection.py
# @Software: PyCharm
# =============================================
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0'}
url = 'https://c.m.163.com/ug/api/wuhan/app/data/list-total' # 定义要访问的地址
r = requests.get(url, headers=headers) # 使用requests发起请求
data_json = json.loads(r.text)
data = data_json['data']
data_province = data['areaTree'][2]['children']
areaTree = data['areaTree']
# 将提取数据的方法封装成函数
def get_data(data, info_list):
info = pd.DataFrame(data)[info_list] # 主要信息
today_data = pd.DataFrame([i['today'] for i in data]) # 提取today的数据
today_data.columns = ['today_' + i for i in today_data.columns]
total_data = pd.DataFrame([i['total'] for i in data])
total_data.columns = ['total_' + i for i in total_data.columns]
return pd.concat([info, total_data, today_data], axis=1)
today_province = get_data(data_province,['id','lastUpdateTime','name'])
province_dict = { num:name for num ,name in zip(today_province['id'],today_province['name'])}
start = time.time()
for province_id in province_dict: # 遍历各省编号
try:
# 按照省编号访问每个省的数据地址,并获取json数据
url = 'https://c.m.163.com/ug/api/wuhan/app/data/list-by-area-code?areaCode=' + province_id
r = requests.get(url, headers=headers)
data_json = json.loads(r.text)
# 提取各省数据,然后写入各省名称
province_data = get_data(data_json['data']['list'], ['date'])
province_data['name'] = province_dict[province_id]
# 合并数据
if province_id == '420000':
alltime_province = province_data
else:
alltime_province = pd.concat([alltime_province, province_data])
print('-' * 20, province_dict[province_id], '成功',
province_data.shape, alltime_province.shape,
',累计耗时:', round(time.time() - start), '-' * 20)
# 设置延迟等待
time.sleep(10)
except:
print('-' * 20, province_dict[province_id], 'wrong', '-' * 20)
def save_data(data, name):
file_name = name + '_' + time.strftime('%Y_%m_%d', time.localtime(time.time())) + '.csv'
data.to_csv(file_name, index=None, encoding='utf_8_sig')
print(file_name + '保存成功!')
if __name__ == '__main__':
save_data(alltime_province, 'alltime_province')
- 2、世界:
# =============================================
# --*-- coding: utf-8 --*--
# @Time : 2020-03-27
# @Author : 不温卜火
# @CSDN : https://blog.csdn.net/qq_16146103
# @FileName: All collection.py
# @Software: PyCharm
# =============================================
import requests
import pandas as pd
import json
import time
pd.set_option('max_rows',500)
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0'}
url = 'https://c.m.163.com/ug/api/wuhan/app/data/list-total' # 定义要访问的地址
r = requests.get(url, headers=headers) # 使用requests发起请求
data_json = json.loads(r.text)
data = data_json['data']
data_province = data['areaTree'][2]['children']
areaTree = data['areaTree']
# 将提取数据的方法封装成函数
def get_data(data, info_list):
info = pd.DataFrame(data)[info_list] # 主要信息
today_data = pd.DataFrame([i['today'] for i in data]) # 提取today的数据
today_data.columns = ['today_' + i for i in today_data.columns]
total_data = pd.DataFrame([i['total'] for i in data])
total_data.columns = ['total_' + i for i in total_data.columns]
return pd.concat([info, total_data, today_data], axis=1)
today_world = get_data(areaTree,['id','lastUpdateTime','name'])
country_dict = {key: value for key, value in zip(today_world['id'], today_world['name'])}
start = time.time()
for country_id in country_dict: # 遍历每个国家的编号
try:
# 按照编号访问每个国家的数据地址,并获取json数据
url = 'https://c.m.163.com/ug/api/wuhan/app/data/list-by-area-code?areaCode=' + country_id
r = requests.get(url, headers=headers)
json_data = json.loads(r.text)
# 生成每个国家的数据
country_data = get_data(json_data['data']['list'], ['date'])
country_data['name'] = country_dict[country_id]
# 数据叠加
if country_id == '9577772':
alltime_world = country_data
else:
alltime_world = pd.concat([alltime_world, country_data])
print('-' * 20, country_dict[country_id], '成功', country_data.shape, alltime_world.shape,
',累计耗时:', round(time.time() - start), '-' * 20)
time.sleep(10)
except:
print('-' * 20, country_dict[country_id], 'wrong', '-' * 20)
def save_data(data, name):
file_name = name + '_' + time.strftime('%Y_%m_%d', time.localtime(time.time())) + '.csv'
data.to_csv(file_name, index=None, encoding='utf_8_sig')
print(file_name + '保存成功!')
if __name__ == '__main__':
save_data(alltime_world,'alltime_world')
三、结果
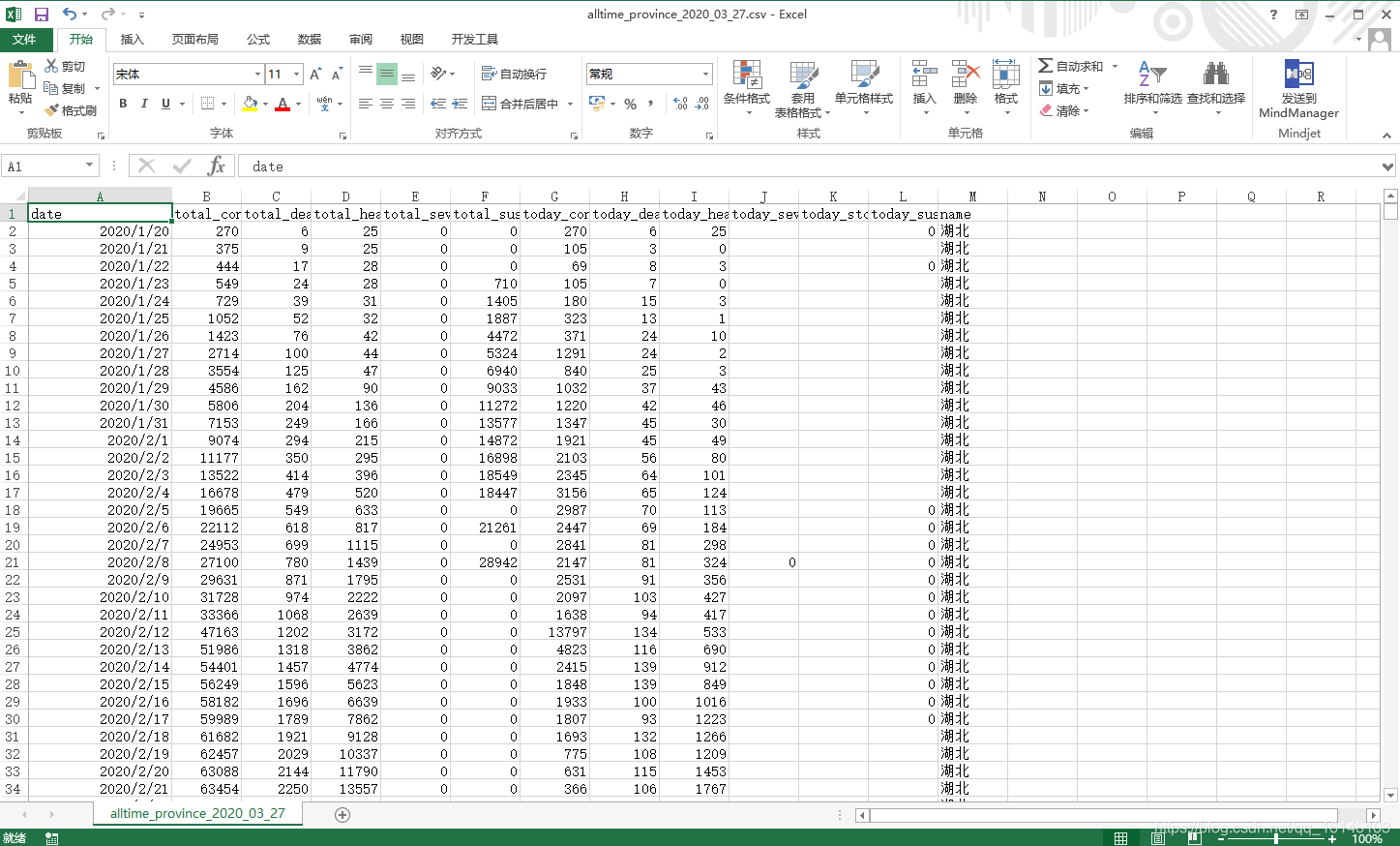
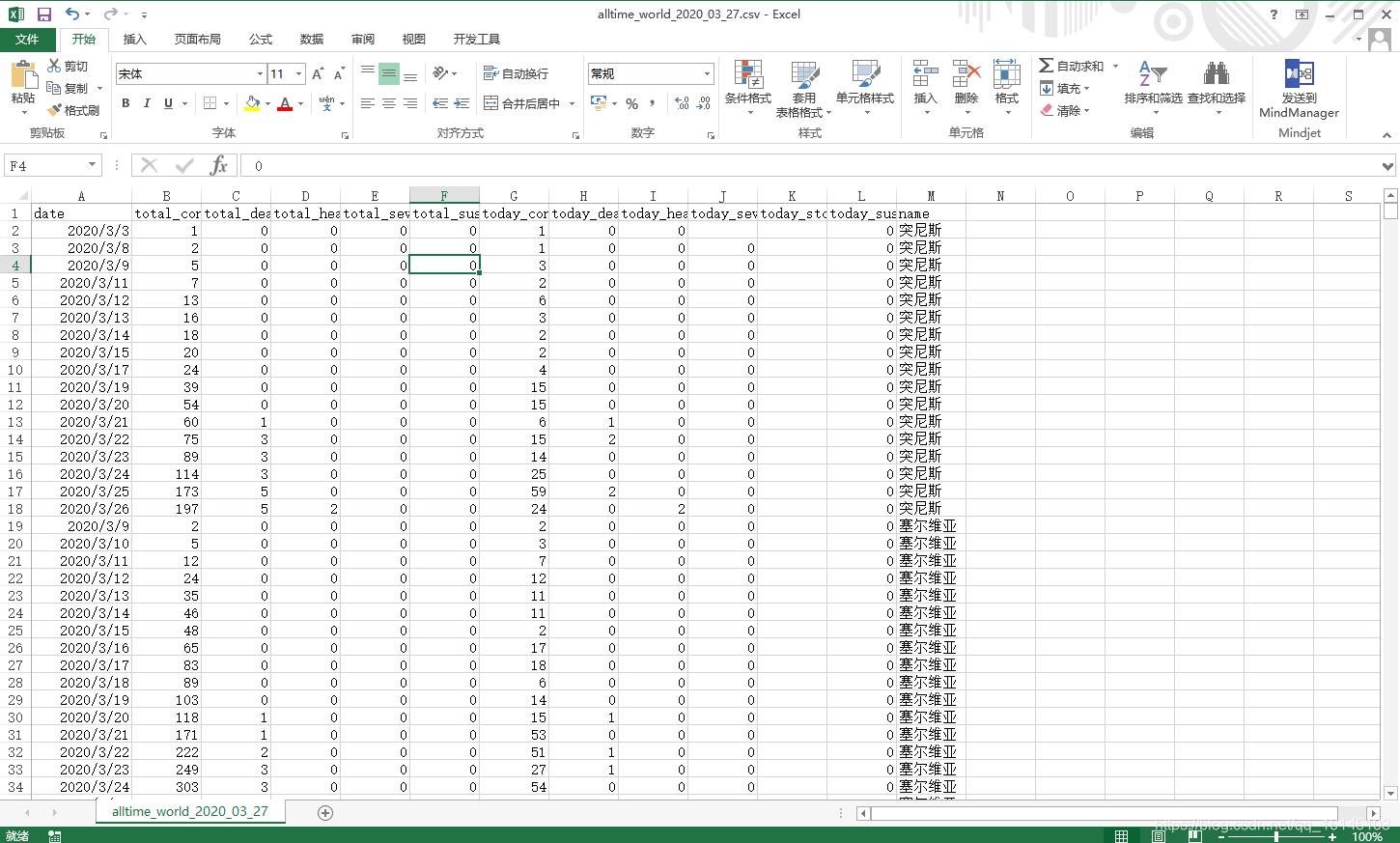
四、总结
- 代码可能还有更高效的写法
- 由于是第一次写这种类型的博文,逻辑结构可能会差点
- 没有采用IP代理池,只是设置了延时进行反爬,速度会有一点慢,可以采用高并发多线程的IP代理池完成爬取。
- 如果像要爬取数据或者自己爬取不出来的话可以私聊博主。
