前言
因为东方财富网的Js限制,第一页很好爬取,但是第二页开始的网页地址并没有改变,看了下xpath页面元素也和第一页没什么区别,所以只好曲线救国,用selenium找到“下一页”按钮进行跳转再爬取,好处是肯定都能爬到,坏处则是必须一直开着chromedriver,而且爬取效率并不高。
7月27日更新:
通过后台查看,发现以下代码可以直接读取json格式的数据,这样直接提取即可(可能不同的时间、不同的ip获取的地址都是不同的,需要自己F12后台查看)
http://15.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112405246752243253328_1595824090101&pn=2&pz=100&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:1+t:2,m:1+t:23&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1595824090123
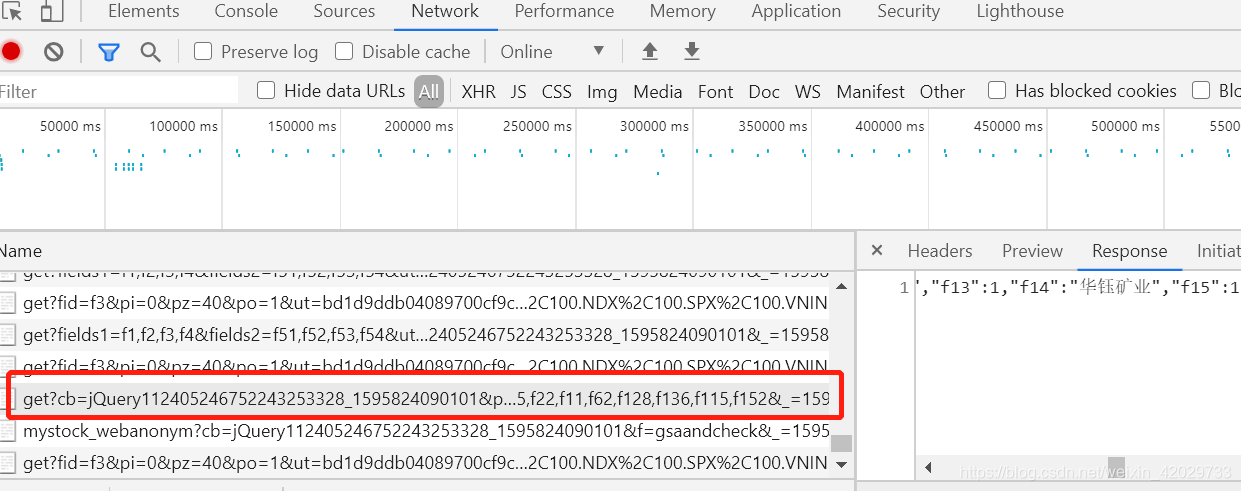 pn是page number 页数
pn是page number 页数
pz是page size 每一页的展示页数
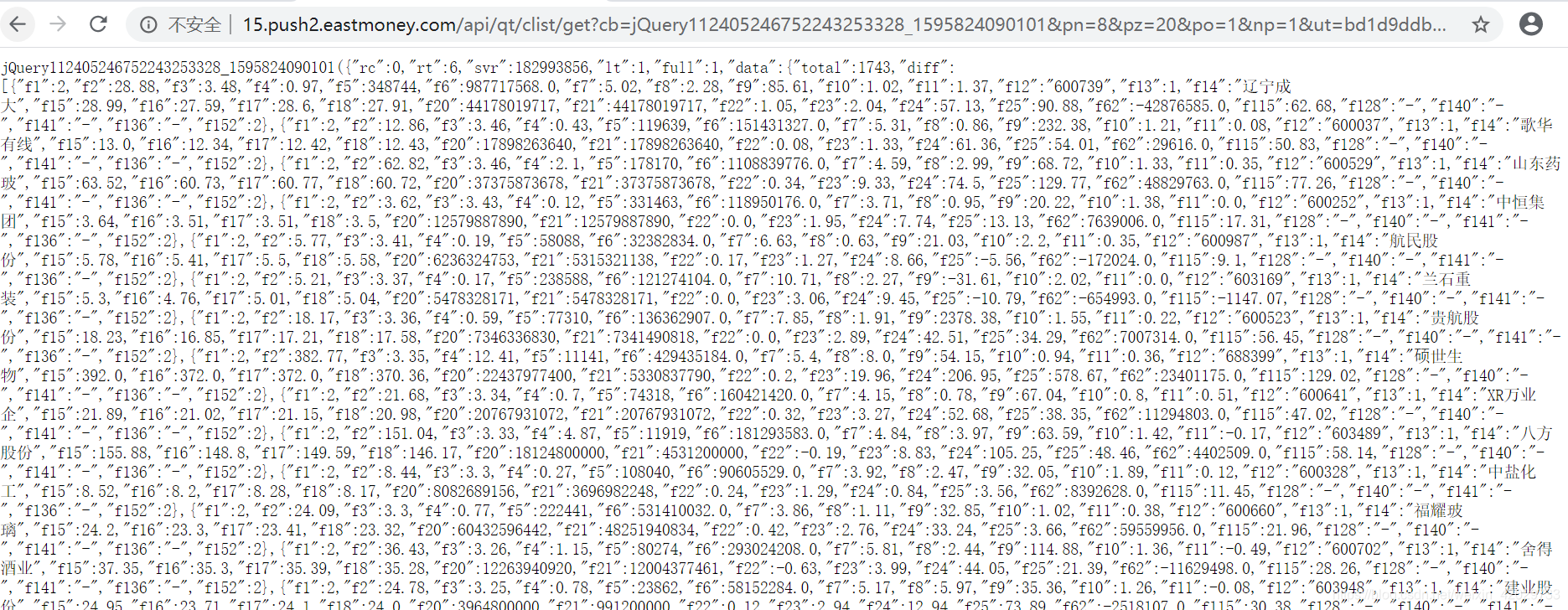
读取后的结果如下图所示:
代码
from selenium import webdriver
from time import sleep
import mysql.connector as mysql
'''爬取上证指数的所有股票信息,保存到本地文件/数据库'''
def extractor(xpath_text):
'''根据xpath获取内容'''
TCases = driver.find_element_by_xpath(xpath_text)
return TCases.text
def export_to_file(stock_dict):
'''导出股票数据'''
with open('沪指股票数据.csv', 'a', encoding='gbk') as file:
file.write(','.join(stock_dict.values()))
file.write('\n')
db = mysql.connect(
host = 'localhost',
user = 'root',
passwd = '',
database = 'testdb2'
)
cursor = db.cursor()
query = "insert into stocks (symbol, name, new, chg_rate, change_value, vol, amount, amplitude, high, low, open, prev_close, qrr, turnover_rate, pe, pb) Values (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s);"
url = 'http://quote.eastmoney.com/center/gridlist.html#sh_a_board'
driver = webdriver.Chrome("D:\python\爬虫\chromedriver.exe")
driver.get(url)
sleep(5)
for page_num in range(1, 81):
for i in range(1, 11):
for ele_type in ['odd', 'even']:
stock_dict = {}
number_list = ['2', '3', '5', '6', '7', '8', '9', '10', '11', '12', '13', '14', '15', '16', '17', '18']
ele_list = ['代码', '名称', '最新价', '涨跌幅', '涨跌额', '成交量', '成交额', '振幅', '最高价', '最低价', '今开',
'昨收', '量比', '换手率', '市盈率', '市净率']
for j, name in zip(number_list, ele_list):
temp_xpath = "/html/body/div[@class='page-wrapper']/div[@id='page-body']/div[@id='body-main']/div[@id='table_wrapper']/div[@class='listview full']/table[@id='table_wrapper-table']/tbody/tr[@class='{}'][{}]/td[{}]".format(
ele_type, i, j)
stock_dict[name] = extractor(temp_xpath)
print(list(stock_dict.values()))
cursor.execute(query, list(stock_dict.values()))
db.commit()
# export_to_file(stock_dict)
#到下一页继续爬
driver.find_element_by_xpath("/html/body/div[@class='page-wrapper']/div[@id='page-body']/div[@id='body-main']/div[@id='table_wrapper']/div[@class='listview full']/div[@class='dataTables_wrapper']/div[@id='main-table_paginate']/a[@class='next paginate_button']").click()
sleep(1)
driver.close()