股票数据定向爬虫实例
目的:获取上交所和深交所所有股票的名称和交易信息
输出:保存到文件中
技术路线:requests-bs4-re
候选数据网站的选择
选取原则:股票信息静态存于HTML页面中,非js代码生成,没有Robots协议限制
选取方法:浏览器F12,源代码查看
数据网站的确定
获取股票列表
东方财富网:http://quote.eastmoney.com/stocklist.html
获取个股信息
百度股票:http://gupiao.baidu.com/stock/
单个股票:http://gupiao.baidu.com/stock/sz002439.html
查看百度股票每只股票的网址:
https://gupiao.baidu.com/stock/sz300023.html
可以发现网址中有一个编号300023正好是这只股票的编号,sz表示的深圳交易所。因此我们构造的程序结构如下:
步骤1: 从东方财富网获取股票列表;
步骤2: 逐一获取股票代码,并增加到百度股票的链接中,最后对这些链接进行逐个的访问获得股票的信息;
步骤3: 将结果存储到文件。
查看百度个股信息网页的源代码,每只股票的信息在html代码中的存储方式如下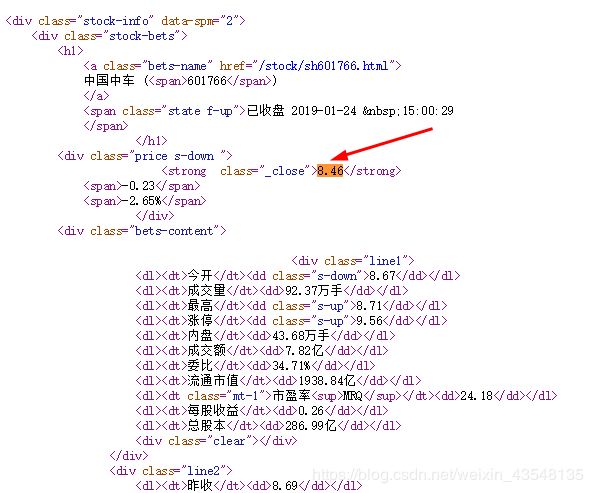
每一个信息源对应一个信息值,即采用键值对的方式进行存储
在python中键值对的方式可以用字典类型
因此,在本项目中,使用字典来存储每只股票的信息,然后再用字典把所有股票的信息记录起来,最后将字典中的数据输出到文件中
代码
1 import requests 2 from bs4 import BeautifulSoup 3 import traceback 4 import re 5 import bs4 6 7 def getHTMLText(url,code='utf-8'): #使用code提高解析效率 8 try: 9 r = requests.get(url) 10 r.raise_for_status() 11 r.encoding = code 12 return r.text 13 except: 14 return '爬取失败' 15 16 def getStockList(lst,stockURL): 17 html = getHTMLText(stockURL,'GB2312') 18 soup = BeautifulSoup(html,'html.parser') 19 a = soup.find_all('a') 20 for i in a : 21 try: 22 href = i.attrs['href'] 23 #以s开头,中间是h或z,后面再接六位数字 24 lst.append(re.findall(r'[s][hz]\d{6}',href)[0]) 25 except: 26 continue 27 28 def getStockInfo(lst,stockURL,fpath): 29 count = 0 30 for stock in lst: 31 url = stockURL + stock +'.html' 32 html = getHTMLText(url) 33 try: 34 if html == "": 35 continue 36 infoDict = {} 37 soup = BeautifulSoup(html,'html.parser') 38 stockInfo = soup.find('div',attrs={'class':'stock-bets'} 39 if isinstance(stockInfo,bs4.element.Tag): 40 name = stockInfo.find_all(attrs={'class':'bets-name'})[0] 41 infoDict.update({'股票名称':name.text.split()[0]}) 42 keyList = stockInfo.find_all('dt') 43 valueList = stockInfo.find_all('dd') 44 for i in range(len(keyList)): 45 key = keyList[i].text 46 val = valueList[i].text 47 infoDict[key] = val 48 with open(fpath,'a',encoding='utf-8') as f: 49 f.write(str(infoDict) + '\n') 50 count += 1 51 print('\r当前速度:{:.2f}%'.format(count*100/len(lst)),end='') 52 #打印爬取进度 53 except: 54 print('\r当前速度:{:.2f}%'.format(count*100/len(lst)),end='') 55 traceback.print_exc() 56 continue 57 58 def main(): 59 stock_list_url = 'http://quote.eastmoney.com/stocklist.html' 60 stock_info_url = 'http://gupiao.baidu.com/stock/' 61 output_file = 'C:/Users/Administrator/Desktop/Python网络爬虫与信息提取/BaiduStockInfo.txt' 62 slist = [] 63 getStockList(slist,stock_list_url) 64 getStockInfo(slist,stock_info_url,output_file) 65
66 main()
运行结果
