爬取网易财经中股票的历史交易数据
需求分析
得到股票代码
股票代码的信息是在东方财富网中获取(http://quote.eastmoney.com/stocklist.html)
得到股票的历史交易记录
股票的历史交易记录是可以在网易财经中直接下载excel表的,地址(http://quotes.money.163.com/trade/lsjysj_603088.html#06f01)这是某一股票的历史交易记录详情,我们可以在页面中找到下载的链接地址。
代码撸起来
首先我们需要在东方财富网中获取到股票的代码,在(http://quote.eastmoney.com/stocklist.html)页面中我们可以看到股票代码,我们可以利用xpath结合正则表达式将这些股票代码获取到
获取股票代码列表的代码:
class StockCode(object): def __init__(self): self.start_url = "http://quote.eastmoney.com/stocklist.html#sh" self.headers = { "User-Agent": ":Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36" } def parse_url(self): # 发起请求,获取响应 response = requests.get(self.start_url, headers=self.headers) if response.status_code == 200: return etree.HTML(response.content) def get_code_list(self, response): # 得到股票代码的列表 node_list = response.xpath('//*[@id="quotesearch"]/ul[1]/li') code_list = [] for node in node_list: try: code = re.match(r'.*?\((\d+)\)', etree.tostring(node).decode()).group(1) print code code_list.append(code) except: continue return code_list def run(self): html = self.parse_url() return self.get_code_list(html)分析网易财经中历史交易记录下载页面获取到下载的链接。
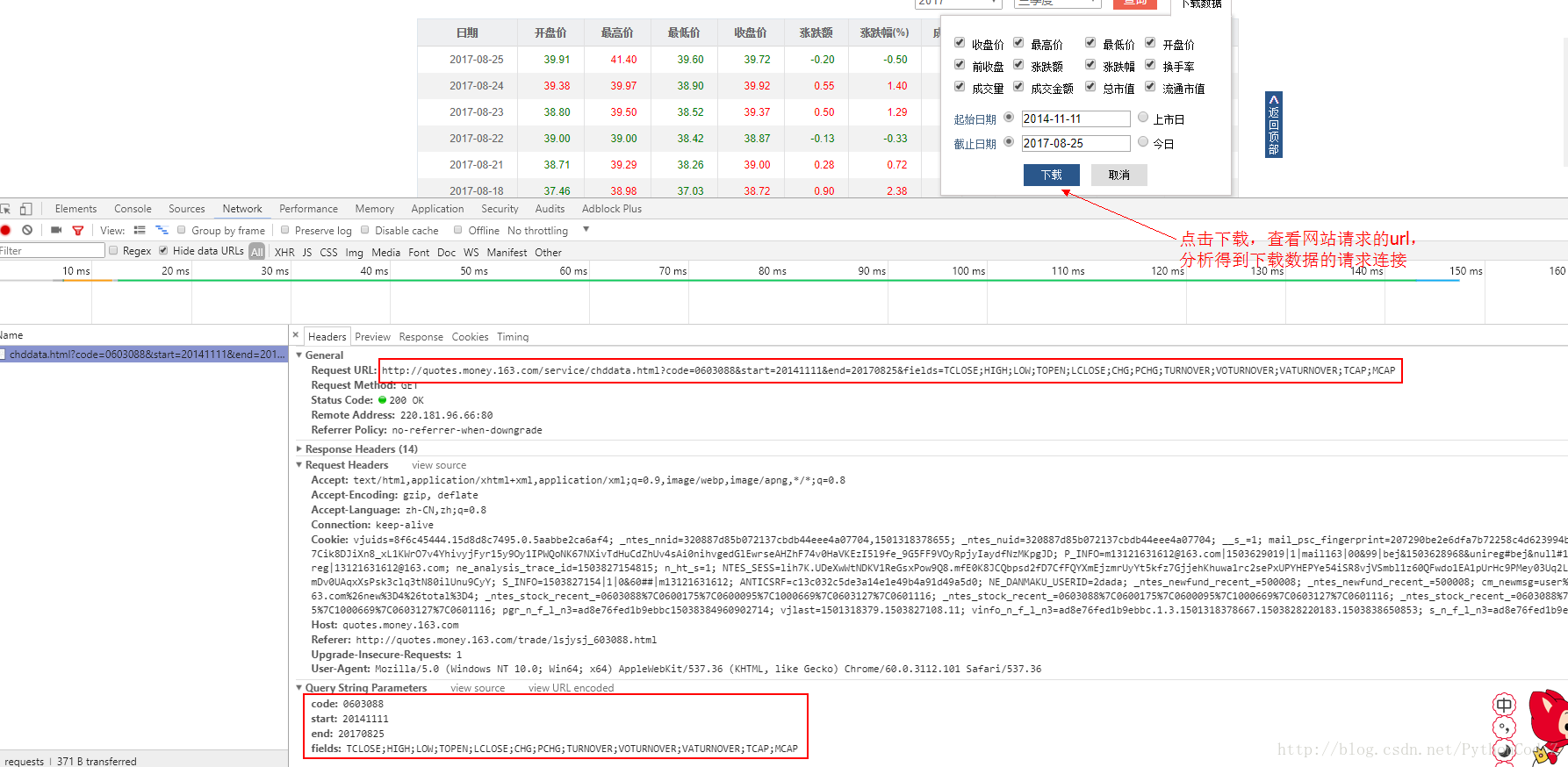
- 使用谷歌浏览器检查工具,切换到network,在我们在点击下载的时候可以得到请求接口:
- 上图中,我们分析到,在点击下载时的url地址,需要传递的参数就是我们的股票代码和下载的起始时间和结束的时间,以及fields后面跟着的一堆参数值,在这里需要注意的是请求的url中股票代码前还多了一位是0。那么我们在爬取的时候,就需要理由xpath来提取页面中要下载数据的起始时间和结束时间,然后将在东方财富网中获取到的股票代码和url进行拼接,拼接成我们想要请求的下载连接。
下载历史交易记录的代码
class Download_HistoryStock(object): def __init__(self, code): self.code = code self.start_url = "http://quotes.money.163.com/trade/lsjysj_" + self.code + ".html" print self.start_url self.headers = { "User-Agent": ":Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36" } def parse_url(self): response = requests.get(self.start_url) print response.status_code if response.status_code == 200: return etree.HTML(response.content) return False def get_date(self, response): # 得到开始和结束的日期 start_date = ''.join(response.xpath('//input[@name="date_start_type"]/@value')[0].split('-')) end_date = ''.join(response.xpath('//input[@name="date_end_type"]/@value')[0].split('-')) return start_date,end_date def download(self, start_date, end_date): download_url = "http://quotes.money.163.com/service/chddata.html?code=0"+self.code+"&start="+start_date+"&end="+end_date+"&fields=TCLOSE;HIGH;LOW;TOPEN;LCLOSE;CHG;PCHG;TURNOVER;VOTURNOVER;VATURNOVER;TCAP;MCAP" data = requests.get(download_url) f = open(self.code + '.csv', 'wb') for chunk in data.iter_content(chunk_size=10000): if chunk: f.write(chunk) print '股票---',self.code,'历史数据正在下载' def run(self): try: html = self.parse_url() start_date,end_date = self.get_date(html) self.download(start_date, end_date) except Exception as e: print e运行项目,开始下载数据:
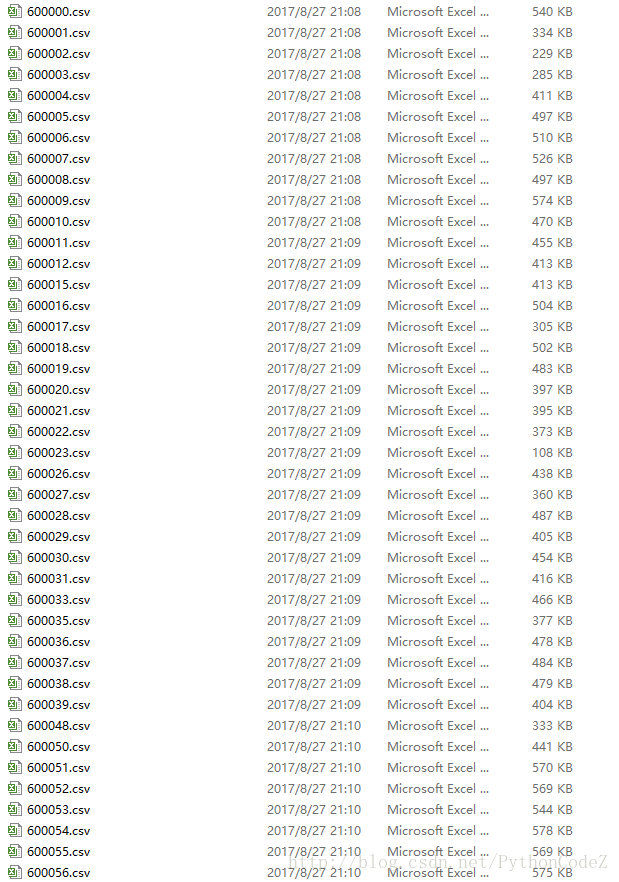
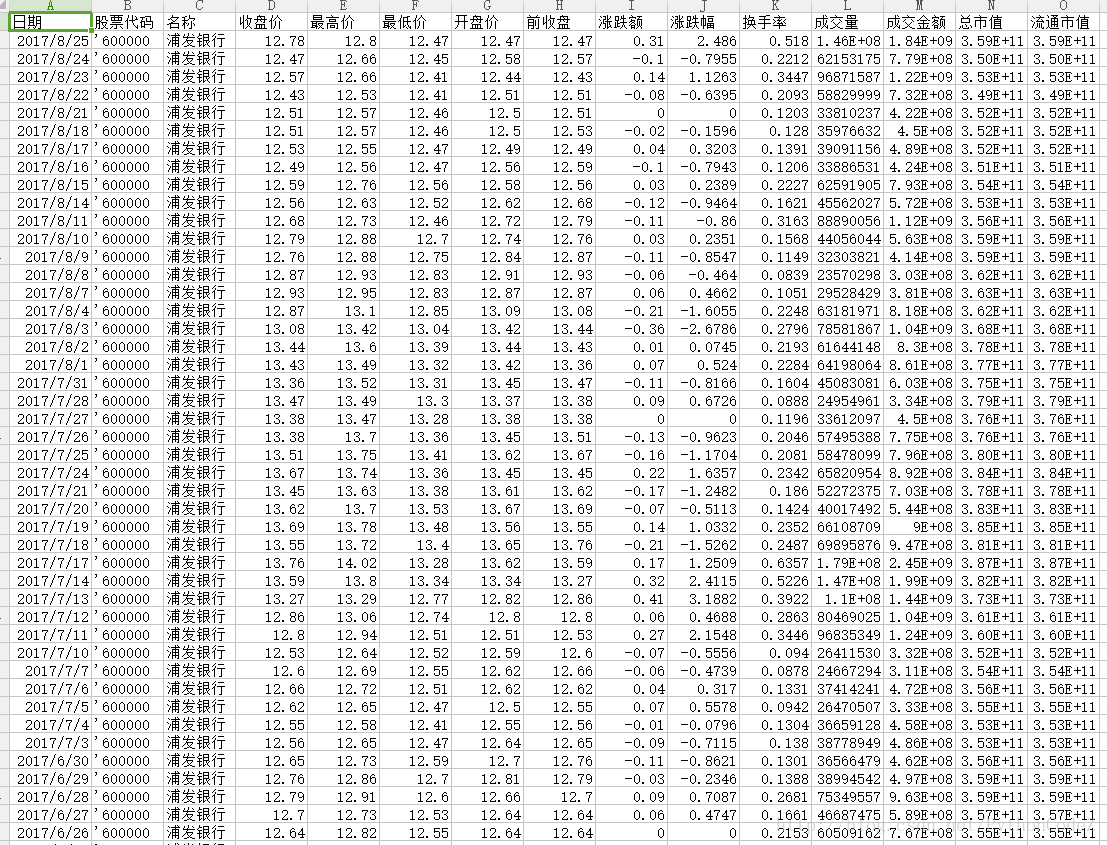
if __name__ == '__main__': code = StockCode() code_list = code.run() for temp_code in code_list: time.sleep(1) download = Download_HistoryStock(temp_code) download.run()下载数据的时候发现,获取到的股票代码2-5开头的都下载不到历史的交易记录,但是从6开始,是可以下载了,下面是下载来的数据效果: