继续介绍文本生成图像的相关工作,本文给出的是2016年12月10日发表于 arXiv 的文章《Stackgan: Text to photo-realistic image synthesis with stacked generative adversarial networks》
论文地址:https://arxiv.org/pdf/1612.03242v1.pdf
源码地址:https://github.com/hanzhanggit/StackGAN-Pytorch
原本想要看一下tensorflow的代码,但是源码要求tensorflow0.12版本,代码也出了很多问题... 改用pytorch代码对模型进行解析。
个人感觉StackGAN本质上仍然是只是两个cGAN的组合,突破性并不是很大。不过它是第一次在只给定文本的条件下生成真实的256*256的图片。
一、相关工作
在介绍StackGAN前,首先对cGAN(Conditional GAN)进行大致的介绍。在GAN中,损失函数如下所示:
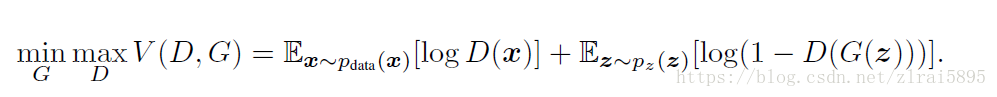
Conditional GAN的想法是把原始的生成过程变成基于某些额外信息的生成,损失函数变为:
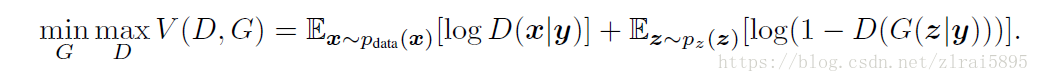
D 和 G 拟合的分布都变成了条件概率分布。在 CGAN 的工作中,这个额外的 y 信息,是通过在输入层直接拼接样本与 y 信息的向量而实现的。具体使用的 y 信息有 one-hot vector,也有图像(也就是基于另一个图像去生成)。
二、基本思想
StackGAN本质上就是两个Conditional GAN的堆叠。如果我们没办法一次生成高分辨率又 plausible 的图片,那么可以分两次生成。第一阶段的Conditional GAN利用文本描述提取出的嵌入向量(text embedding)粗略勾画物体主要的形状和颜色,生成低分辨率的图片。第二阶段的对抗生成网络将第一阶段的低分辨率图片和文本描述提取出的嵌入向量(text embedding)作为输入,生成细节丰富的高分辨率图片。
关于词嵌入向量可以参考https://blog.csdn.net/zlrai5895/article/details/81255243部分内容。StackGAN的模型结构图如下:
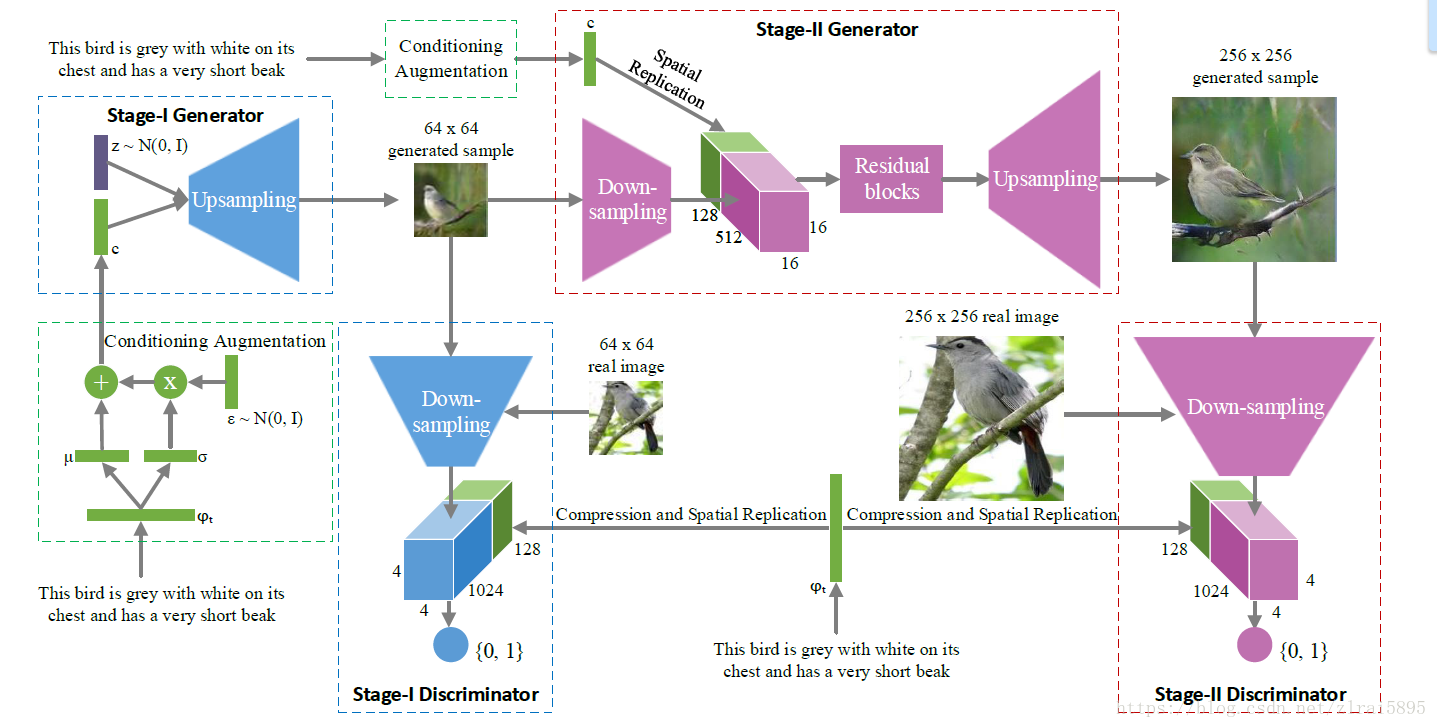
- 三、数据集介绍
本次实验使用的数据集是COCO2014,关于COCO数据集的介绍可参考https://blog.csdn.net/zlrai5895/article/details/81255243部分内容。
四、模型结构
还是先上结构图:
1、文本编码器
我们使用预训练好的char-CNN-RNN文本编码器,https://github.com/reedscot/icml2016中给出了训练该编码器的网络源码以及预训练好的编码器。我们并不对此进行详细介绍。直接使用文本编码器生成的COCO数据集嵌入向量text_embedding。
2、第一阶段
由结构图可见,对于获得的text_embedding,stackGAN 没有直接将 embedding 作为 condition,而是用embedding 接了一个 FC 层得到了一个正态分布的均值和方差,然后从这个正态分布中 sample 出来要用的 condition。最终的condition(c0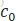
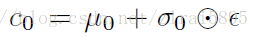

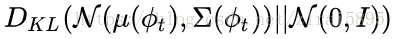
得到的c与服从标准正态分布的z连接起来,作为第一阶段generator的输入。
generator 使用的并不是常用的 Deconv ,而是若干个上采样加保持大小不变的 3x3 的 conv 的组合,这是最近提出的一种避免 Deconv 棋盘效应的上采样方法。discriminator 是若干步长为 2 的 conv ,再与 resize 的 embedding 合起来,接一个 FC。
第一阶段的输出是64*64的低分辨率图像。以batch_size=16为例,部分代码如下:
def forward(self, text_embedding, noise):
print(text_embedding.shape,noise.shape)#[16,1024] [16,100]
c_code, mu, logvar = self.ca_net(text_embedding)
print(noise.shape,c_code.shape) # (torch.Size([16, 100]), torch.Size([16, 128]))
z_c_code = torch.cat((noise, c_code), 1) # 16x228
h_code = self.fc(z_c_code)# torch.Size([16, 16384])
h_code = h_code.view(-1, self.gf_dim, 4, 4) #torch.Size([16, 1024, 4, 4])
h_code = self.upsample1(h_code) #torch.Size([16, 512, 8, 8])
h_code = self.upsample2(h_code)#torch.Size([16, 256, 16, 16])
h_code = self.upsample3(h_code)#torch.Size([16, 128, 32, 32])
h_code = self.upsample4(h_code)#torch.Size([16, 64, 64, 64])
# state size 3 x 64 x 64
fake_img = self.img(h_code)##torch.Size([16, 3, 64, 64])
return None, fake_img, mu, logvar其中 有关self.fc的定义:
ngf = self.gf_dim #1024
# TEXT.DIMENSION -> GAN.CONDITION_DIM
self.ca_net = CA_NET()
# -> ngf x 4 x 4
self.fc = nn.Sequential(
nn.Linear(ninput, ngf * 4 * 4, bias=False),
nn.BatchNorm1d(ngf * 4 * 4),
nn.ReLU(True))3、第二阶段
第二阶段的 generator 并没有噪声输入,而是将第一阶段生成的低分辨率图像下采样以后与replicated的c0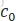
第二阶段的 discriminator 与第一阶段大体相同。
部分代码如下:
def forward(self, text_embedding, noise):
_, stage1_img, _, _ = self.STAGE1_G(text_embedding, noise)
#fake_img [16,3,64,64]
stage1_img = stage1_img.detach()#返回一个新的 从当前图中分离的 Variable。 返回的
# Variable 永远不会需要梯度
encoded_img = self.encoder(stage1_img) #[16,256,512] output:[16,512,16,16]
c_code, mu, logvar = self.ca_net(text_embedding)# 输入torch.Size([16, 1024])
#输出 torch.Size([16, 128]))
c_code = c_code.view(-1, self.ef_dim, 1, 1)#output:[16,128,1,1]
c_code = c_code.repeat(1, 1, 16, 16) #output: [16,128,16,16] replicated
i_c_code = torch.cat([encoded_img, c_code], 1) #output:[16,640,16,16] cat
h_code = self.hr_joint(i_c_code)
# input:[16,128+128*4,16,16] output:[16,512,16,16]
h_code = self.residual(h_code) #output:[16,512,16,16]
h_code = self.upsample1(h_code)#[16,256,32,32]
h_code = self.upsample2(h_code)#[16,128,64,64]
h_code = self.upsample3(h_code)#[16,64,128,128]
h_code = self.upsample4(h_code)#[16,32,256,256]
fake_img = self.img(h_code)#[16,3,256,256]
return stage1_img, fake_img, mu, logvar其中self.hr_joint和self.residual代码如下:
self.hr_joint = nn.Sequential(
conv3x3(self.ef_dim + ngf * 4, ngf * 4),# output:[16,128+128*4,128*4]
nn.BatchNorm2d(ngf * 4),
nn.ReLU(True))self.residual = self._make_layer(ResBlock, ngf * 4)
def _make_layer(self, block, channel_num):
layers = []
for i in range(cfg.GAN.R_NUM):
layers.append(block(channel_num))
return nn.Sequential(*layers)
class ResBlock(nn.Module):
def __init__(self, channel_num):
super(ResBlock, self).__init__()
self.block = nn.Sequential(
conv3x3(channel_num, channel_num),
nn.BatchNorm2d(channel_num),
nn.ReLU(True),
conv3x3(channel_num, channel_num),
nn.BatchNorm2d(channel_num))
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
residual = x
out = self.block(x)
out += residual
out = self.relu(out)
return out
五、训练
第一阶段的损失函数:
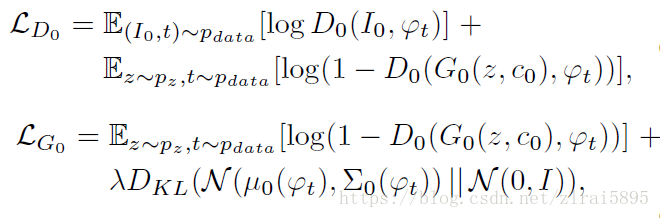
第二阶段的损失函数:
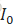
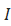
模型结构图中可以注意到的是,text_bedding 也是最后鉴别器的输入之一。在训练期间,鉴别器将真实图片+对应的text_bedding作为正样本对。负样本对包括两种:真实的图片+不配套的text_bedding、生成的图片+对应的text_bedding。