本篇博客介绍2016年3月17号发表于arXiv的论文《Learning Deep Representations of Fine-Grained Visual Descriptions》,首先要讲明的是,这篇文章并不是做文本生成图像的工作.它提出的模型是为了解决图像检索的问题,也就是给出一句话,找出和这句话最匹配的图像.文章提出了一个很有用的目标函数以及三种训练文本编码器的方式.提出的文本编码器在后续工作
《Generative Adversarial Text to Image Synthesis》 《Learning What and Where to Draw》等众多文本生成图像的工作中都有用到.所以在这篇博客中介绍一下.
部分内容引自:https://zhuanlan.zhihu.com/p/32390849
论文地址:https://arxiv.org/abs/1605.05395
源码地址:https://github.com/reedscot/cvpr2016
一、相关工作
续作《Generative Adversarial Text to Image Synthesis》相关理解:https://blog.csdn.net/zlrai5895/article/details/81416053
续作《Learning What and Where to Draw》相关理解:https://blog.csdn.net/zlrai5895/article/details/81411273
对GAN的相关理解:https://blog.csdn.net/zlrai5895/article/details/80648898
二、基本思想及成果

解决图像检索的问题,也就是给出一句话,找出和这句话最匹配的图像.文章提出了一个很有用的目标函数以及三种训练文本编码器的方式.
三、 数据集
本次实验使用的数据集是加利福尼亚理工学院鸟类数据库-2011(CUB_200_2011)。
四、模型结构:
1、文本和图像编码器
我们通过优化下面这个损失来得到最终的sentence embedding。


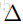
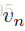

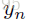
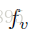
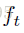

可以看到它们最终的输出是预测的标签。


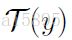

从文本编码器的角度来看,这意味着文本特征必须对匹配图像产生比以下两种情况更高的兼容性得分
- 不与任何文本匹配的图像
- 不与任何图像匹配的文本
2 learning
由于0-1损失是不连续的,将Objective.改为优化连续和凸的函数。
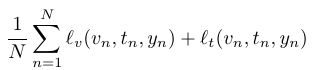
错误分类的损失写成:
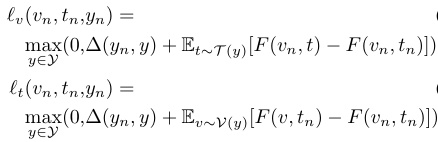
实验的文本编码器模型共有三个(下文会给出介绍),所以通过所有文本网络参数反向传播来进行端到端的训练。
图像编码器使用GoogLeNet。
3 文本编码器
共三种 ,每种又分为对字符(char)编码和词汇编码(word)
(1)Text-based ConvNet (CNN)
基于文本的CNN可以被看作是标准的图像CNN,除了图像宽度是1像素并且通道数量等于字母大小。 2D卷积和空间max-pooling被1D卷积和时间max-pooling替代。 在每个卷积层之后,使用整流线性激活单元(ReLU)。整个网络是利用卷积,池化和阈值激活函数,然后通过全连接来投影到嵌入空间。 文本嵌入函数 ——是CNN的最后隐藏层。
字符序列的最大输入长度受网络体系结构的限制,但是在这个限制之下的可变长度序列是通过在最终输入字符后零填充。 Word-CNN与Char-CNN完全相同,除了Char-CNN的字母表被替换为Word-CNN的词汇之外。 当然,词汇量要大得多,通常至少有几千字,而字母表中只有几十个字符。 但是,序列长度显着减少。
(2)Convolutional Recurrent Net (CNN-RNN)
纯卷积文本模型的一个潜在缺陷是它们缺少沿着输入文本序列的强烈的时间依赖性。 但是CNN模型又是非常快速的,可以很好地适应像字符串这样的长序列。 为了获得循环模型和CNN的好处:在一个中等水平的时间CNN隐藏层之上叠加一个循环性网络。 直观上,CNN隐藏激活沿着时间维度(当维度减少到8)被分割并且被当作输入向量序列。 整个网络仍然是端到端的。
这种方法的优点是可以利用快速卷积网络有效地学习low-level的时态特征,而时态结构仍然可以在更为抽象的中层特征层次上被利用。 这可以被看作是在抽象或概念层面建模时间结构,而不是由字边界来严格界定。 该方法非常适合字符级处理(Char-CNN-RNN)的情况。 我们也评估一个字级版本(Word-CNN-RNN)。
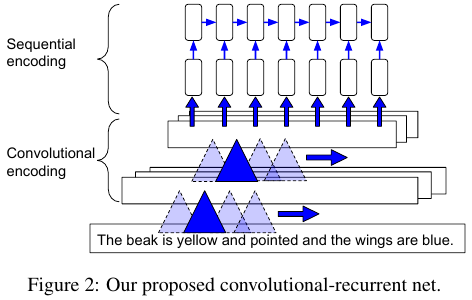
最终的编码特征是序列上的平均隐藏单元激活,即 ,其中
是第
帧的隐藏激活向量,L是序列长度。 得到的评分函数可以看作是与查询图像兼容的线性累积(如图1所示)。 它也是一个关于文本序列的线性化版本。这具有的优点是在分类或检索的测试时间,可以使用平均隐藏单元作为特征,但是为了判断,可以将分数计算回溯到文本处理的每一步。
(3)Long Short-Term Memory (LSTM)
与CNN模型相反,LSTM明确地考虑了从文字或字符开始的时间结构。 为了从LSTM文本编码器中提取文本嵌入,取最后一层隐藏单元的时间平均,即 (类似于上一节定义)。