写在开头
想看正文的可以直接跳过这段,只不过是一个诗人的无病呻吟而已。
不积跬步无以至千里,不积小流无以成江海。这是我写的第一篇博客,情不自禁就想先发表一些感慨,聊一聊我作为一个狼人悍跳预言家的心路历程,希望各位好人能认下我这匹预言家(狗头)。本来想装一个深情且高冷的大牛牛牛,说不到3秒就破功哈哈哈哈哈嗝。
在下是某普通学校的研一学生,主要研究方向是图像描述。平时也喜欢无聊写写不正经随笔什么的,至于写这些看论文的过程的博客的想法,还是没多久前受实验室一位师姐的启发。在边写博客边学习的同时,这些“文章”亦可留作以后回看。本人学历有限,阅历也有限,水平更是很有限(不然也不至于2020年了还在看2015年的论文),所以本篇内容以及自己的一些观点在大神看来难免会觉得幼稚。没有关系,有什么觉得我说得不好的地方可以直接指出来,我会再研究研究的。
文章简介
这篇文章是Li Fei-Fei教授在cvpr2015的一篇文章,与同一年的一篇提出了NIC模型的文章都是我在研究图像描述时的入门论文。这篇文章在当时有两个方面的突破(以下英文摘录自文章):
-
We develop a deep neural network model that infers the latent alignment between segments of sentences and the region of the image that they describe.
提出了一种深度神经网路模型,该模型用来将训练样本中图片中的一些重点部分与生成句中的词组相对应。 -
We introduce a multimodal Recurrent Neural Network architecture that takes an input image and generates its description in text.
提出一种多通道RNN框架来描述一张图片。
模型介绍
目标一:部分图片与词组作对应
那么作者是如何想到要将图片中的一些重点部分与生成句中的词组向对应的呢?可以看到文中这句话:
Our key insight is that sentences written by people make frequent references to some particular, but unknown location in the image.
人们在尝试描述一个图片时通常会抓取图片中的一些特殊部分。
举个栗子吧。下图是训练的图所对应的描述:

将该描述中的片段与图中片段相对应:
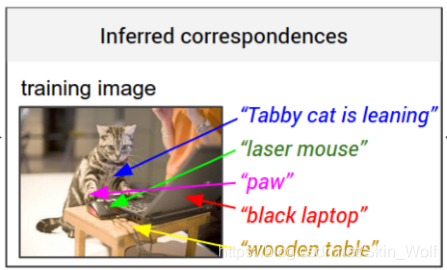
测试后的结果:
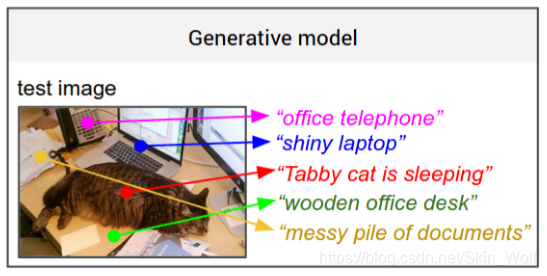
这就是作者提出的第一个目标的效果示意图。那么这样的目标是如何完成的呢?
答案就是RCNN+BRNN!!!
图像分割
RCNN大家应该很熟悉了,是老牌的用来分割图像的模型了,老到什么程度呢?就像我们现在看美国的密苏里号战列舰那个样。当然这篇论文写于5102年,这个分割图片的方法我盲猜一下在当时应该是首选吧。不管有多老,这个方法总还是有点风韵犹存的,那咱们就来探秘一下这位老美人儿吧(滑稽)。
文中是这样讲的:
we use the top 19 detected locations in addition to the whole image and compute the representations based on the pixels Ib.
我们使用检测出排名前19个图片的子框加上图片本身来进行卷积操作。
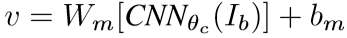
CNN(Ib) 将 Ib 转变成4096维的向量,Wm 的维度是 h*4096 (h 在 1000-1600维之间),所以每张图片用20个h维的向量描述。
句子分割
为了建立RCNN所产生的20个h维向量(即图片的20个部分)与给定描述中部分词组的关系,我们还需要把句中的词组也变成h维向量。我们能想到最简单的方法就是把这些单词接投影到向量中,然而这样的方法没有考虑到单词不是与20个图像顺序对应的,同时也没有考虑到单词特定语境下蕴含的其他信息。当然还有一些其他的改进如将单词改为词组,这些方法都不能取得我们理想的效果。
为了解决这个问题,我们需要用到BRNN(双向RNN)。BRNN在把每个单词变为h维向量的同时还会用一个index t来记录每个单词在句子中的位置,至于这个t是怎么代表语境下的特殊意义的,我们先来看一下完整的公式:

其中第一个公式里的It是一个列向量指示器,在单词表的第t个单词的索引都有一个值。用 word2vec 将单词转为300维的向量表示,即权重Ww。这一步是准备工作,到了第二个公式则是将这些一股脑儿输入进BRNN模型里面。而公式三四代表着BRNN中的两个方向的RNN,最后得出的St中既包含了单词的位置,又包含在语境中的特殊含义,在最后用ReLU作为激活函数。
注:Word2vec,是一群用来产生词向量的相关模型。这些模型为浅而双层的神经网络,用来训练以重新建构语言学之词文本。网络以词表现,并且需猜测相邻位置的输入词,在word2vec中词袋模型假设下,词的顺序是不重要的。训练完成之后,word2vec模型可用来映射每个词到一个向量,可用来表示词对词之间的关系,该向量为神经网络之隐藏层。
目标对应
有了前面的两步,我们已经分别将图片与描述都转为h维向量,接下来就是要两两对应了。呐这篇文章是这样讲的:
our strategy is to formulate an image-sentence score as a function of the individual region word scores.
我们提出一种得分机制来当作不同单词在各个区域的得分。
最匹配的对应关系当然是所有对应的总得分最高的时候。那么这个得分是如何计算的呢?
这里该文章作者借用另外一篇文章的计算方法,即计算第i个图像部分的向量表示与第t个单词的点积,然后通过下面这个公式来定义最终得分:
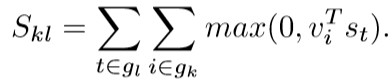
其中gk与gl分别为图片k与句子l中的片段。连同其附加的“多实例学习”目标一起,该分数可解释为只要点积为正,句子片段就会与图像区域的子集对齐。当然,作者还对此公式进行了简化,同时减轻了对其他目标及其超参数的需求:
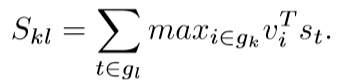
其实这个优化呢我也是一知半解的,原先的相似性度量是把每一对大于0的点积求和得出最终得分,改版后就是只针对每个图像最大的点积算出对应句子片段的得分,这个优化的好处我没法解释,简化了计算倒是很容易理解的,但是大牛既然成功实用过了,那我们就先记下这个方法,以后看到其他论文有类似的再说。这个计算Skl过程可以由下面这个图更直观地看出来:
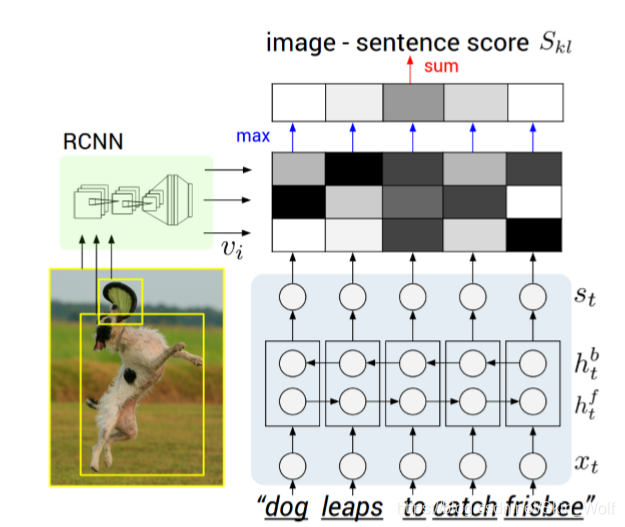
最后就是损失函数了:

看到这个里面有Slk,这就解释了刚才的优化为什么只针对每个图像最大的点积,这个Slk则是针对每个句子片段的最大点积,而Skk的意思应该是一个得分标准。后面的+1是为防止没有与标准值特别符合的(因为点积和大于0即代表合格,分越大越好),便只能从不合格里面选出最接近的了(打篮球高个子不够,只能从矮个子里面选最高的),当然又不能点积分过低,于是实在找不到就从点积和(-1,0)之间找个最好的吧,毕竟脸打肿了也是可以充胖子的。
解码
由于我们最终对生成文本片段而不是单个单词感兴趣,因此我们希望将单词的扩展、连续序列对齐到单个边界框。现在出现另外一个问题,我们光是追求讲每个单词放入得分最高的区域是不行的,这会导致单词会没有意义地分散开来。
要解决这个问题,我们将真正的配对视为马尔可夫随机场(MRF)中的潜在变量,这个马尔可夫随机场其实就是对相邻单词在同一图片区域比对有额外加分。那么给定N个单词与M个边界的图片,我们用如下公式来顺着句子用一个链式结构来建立一个马尔可夫随机场(MRF):
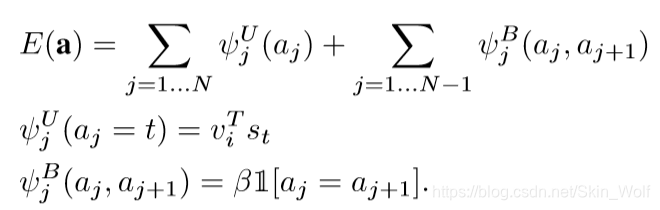
其中,β是用来对较长词组会有额外加分,即鼓励尽量用多单词的词组进行匹配。这个参数的设置允许在只有一个单词对应时(β=0)进行另外插值,当β很大时允许将整个句子对应到某个得分最高的区域。最终输出是一组带有文本片段的图像区域。
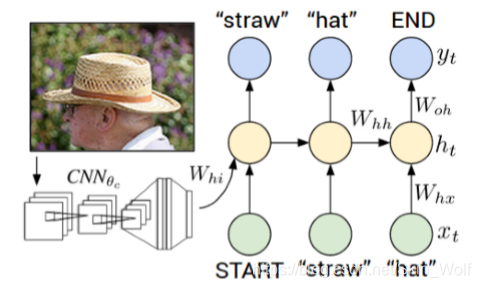
目标二:图像描述的生成(VGGnet+RNN )
有了前面的内容的铺垫,到了完成第二个目标的时候了。第二个目标的关键在于模型的设计,而该模型在收到一张图片后能预测出可变长度的输出序列。在写这篇文章前类似这样的工作是这样做的:给定一个单词以及先前时间步的其他语境意义时,定义该输出序列中下一个单词的概率分布。作者在此基础上做了一个简单有效的扩展,即额外训练输入图像内容的生成过程。话不多说上公式:
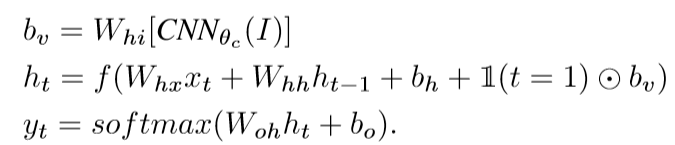
Xt为t时刻的输入;ht为t时刻的语境意义,会带入到t+1时刻计算;yt为下一个输出单词。由下图可以直观地看出RNN地训练过程:每一步RNN接受都接受上一步的单词与语境义,同时在句中下一个单词基础上定义一个分布。RNN在第一个时间步的输入取决于图像信息。要注意的是训练的时候每一时刻输入的是标准答案,测试的时候的输入是上一时刻概率最大的单词。
实验
用了三个数据集:Flickr8K、Flickr30K 和 MSCOCO,分别包含8000、31000、123000张图片,每张图片都有五句描述。对于Flickr8K 和 Flickr30K 采用1000张图片作为验证集,1000张图片作为测试集。对于MSCOCO采用5000张图片作为验证集,5000张作为测试集。
预处理:将所有句子转为小写,然后选取出现不少于五次的单词,对于三个数据集分别得到 2538,7414,8791个单词。
其他具体实验步骤就不作过多的介绍。
总结
- 提出了一种通过常见的multimodal embedding就可以将训练数据图像部分与文字相对应的模型,并且该模型的表现达到当时最好(貌似每个论文都会有这么一句彩虹屁);
- 描述了一种Multimodal RNN框架,该框架可以用来生成图像描述。并且在不同的检测标准下该方法都优于平均基准。
后记
总之,以上便是我对这篇论文的大概理解。鉴于本人刚入门,学术水平有限,有些个人意见当然是难登大雅之堂。所以大家有觉得不对或者不准确的地方可以评论私信指出来,有兴趣的可以一起讨论讨论。
在写完这篇笔记后,原本稍微了解便一带而过的地方也更加清晰了,看来这个方法值得坚持下去。本文一些内容有参考过别人写的文章,并且在此基础上加了一些个人意见。同时我希望这几年的研究生生活中我也可以写出几篇像这样优秀的论文。
