目录
NLTK(natural language toolkit)
一、初识数据分析与挖掘
1.1 什么是数据分析与挖掘技术?
所谓数据分析,即对已知的数据进行分析,然后提取出一些有价值的信 息,比如统计出平均数、标准差等信息,数据分析的数据量有时可能不会太大,而数据挖掘,是指对大量的数据进行分析与挖掘,得到一些未知的,有价值的信息等,比如从网站的用户或用户行为数据中挖掘出用户的潜在需求信息,从而对网站进行改善等。数据分析与数据挖掘密不可分,数据挖掘是数据分析的提升。
1.2 数据分析与挖掘技术能做什么事情?
数据挖掘技术可以帮助我们更好的发现事物之间的规律。所以,我们可以利用数据挖掘技术实现数据规律的探索,比如发现窃电用户、发掘用户潜在需求(啤酒尿布)、实现信息的个性化推送、风险防控、发现疾病与症状甚至疾病与药物之间的规律……等。
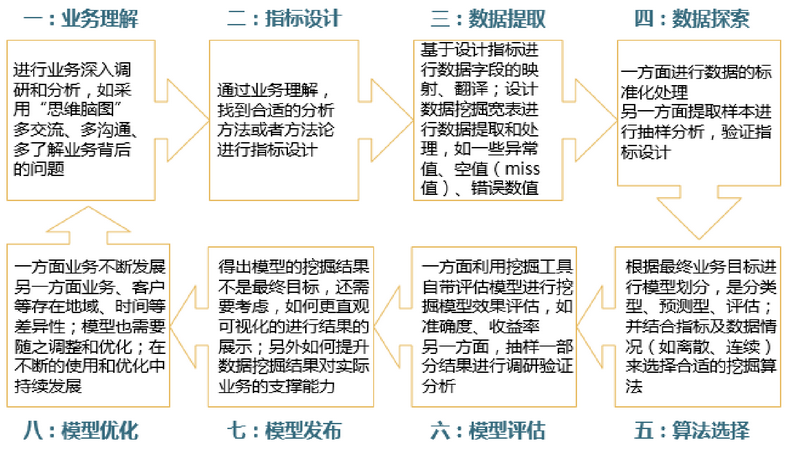
1.3 数据挖掘的过程
应用建模的八步法:业务理解、指标设计、数据提取、数据探索、算法选择、模型评估、模型发布、模型优化
二、数据挖掘与Python模块功能介绍
2.1 基本模块
Numpy
Python没有提供数组,列表(List)可以完成数组,但不是真正的数据,当数据量增大时,它的速度很慢。所以Numpy扩展包提供了数组支持以及高效的 处理函数,同时很多高级扩展包依赖它。
Pandas
Pandas是面板数据(Panel Data)的简写。它是Python最强大的数据分析和探索工具,因金融数据分析工具而开发,支持类似SQL的数据增删改查,支持时间序列分析,灵活处理缺失数据,后面详细介绍。
Scipy
Scipy提供矩阵支持,以及矩阵相关的数值计算模块。如果说Numpy让Python有了Matlab的味道,那么Scipy就让Python真正地成为二半个Matlib。因为涉及到矩阵内容,而课程中主要使用数组,所以不再介绍。
scikit-learn
Scikit-Learn是一个基于python的用于数据挖掘和数据分析的简单且有效的工具,它的基本功能主要被分为六个部分:分类(Classification)、回归(Regression)、聚类(Clustering)、数据降维(Dimensionality Reduction)、模型选择(Model Selection)、数据预处理(Preprocessing),前面写的很多文章算法都是出自该扩展包。
2.2 其他常用模块
Theano
用来定义、优化和模拟数学表达式计算,用于高效地解决多维数组的计算问题以及深度学、框架。
Keras
基于Theano的深度学习库,主要用于搭建人工神经网络、自编码器、卷积神经网络等深度学习模型。
Gensim
是一个python的自然语言处理库,能够将文档根据TF-IDF, LDA, LSI 等模型转化成向量模式,以便进行进一步的处理。此外,gensim还实现了word2vec功能,能够将单词转化为词向量,用于文本挖掘。
StatsModels
注重数据统计建模分析的数据处理模块,与Pandas结合,强大的数据挖掘组合。
NLTK(natural language toolkit)
Python自然语言处理模块,包括一系列的字符处理和语言统计模型。常用于学术研究和教学,应用领域有语言学、认知科学、人工智能、信息检索、机器学习等。
Mlpy
基于NumPy和SciPy的机器学习模块,CPython的拓展应用。
PyBrain
Python机器学习模块,用于处理神经网络、强化学习、无监督学习、进化算法。
Milk
Python机器学习工具箱,重点提高监督分类法与几种有效的分类分析:SVMs,kNN,随机森林和决策树等。
Pattern
Python的web挖掘模块,绑定了Google、Twitter、Wikipedia API,提供网络爬虫、HTML解析功能,文本分析包括浅层规则解析、WordNet接口、句法与语义分析、TF-IDF、LSA等,还提供聚类、分类和图网络可视化的功能。
Orange
基于组件的数据挖掘和机器学习软件套装,它功能友好强大,拥有快速而多功能的可视化编程前端,以便浏览数据分析和可视化,且绑定了Python已进行脚本开发。它包含了完整的一系列的组件以进行数据预处理,并提供了数据账目、过渡、建模、模式评估和勘探的功能。
MXNet
深度学习最新框架,性能和速度超越Theano。
XGBoost
是一个速度快、效果好的boosting模型,被封装成了Python模块。该模块能够自动利用CPU的多线程进行并行,同时提高了算法的精度。
...
三、选择模块安装与技巧
模块安装的顺序与方式建议如下:
1、numpy+mkl(下载安装) 下载地址:https://pan.baidu.com/s/1XJek5BKyOvRQjzrbeFQa3w
2、pandas(网络安装)
3、matplotlib(网络安装)
4、scipy(下载安装) 下载地址:https://pan.baidu.com/s/1vxaPw3JVjQvY0aRe5jzhcg
5、statsmodels(网络安装)
6、Gensim(网络安装)
下载安装步骤
①下载百度云盘对应的模块,模块的版本和python、操作系统对应(amd64对应64位系统,cp35对应python3.5)
②win+r进入运行命令框,对话框内输入:cmd 进入DOS系统,进入下载文件夹路径输入:pip install ***(模块全名+格式)

网络安装步骤
cmd模式下输入:pip install pandas
提示:successful 则安装成功。
四、python安装及环境变量设置(pip安装)
pip是依赖python的,首先检查下windows机器上有没有安装python,或者有没有添加到环境变量中,如果都没有需要安装或者加入环境变量(python3.5下载地址:https://pan.baidu.com/s/1UNaVrrDWJ-S8uVtBPS1OSw)
4.1 配置环境变量
右键我的电脑 -> 属性 -> 高级系统设置 -> 环境变量 -> 编辑PATH -> Python安装路径 -> 点击确定
(或者在python安装的时候勾选自动设置变量)
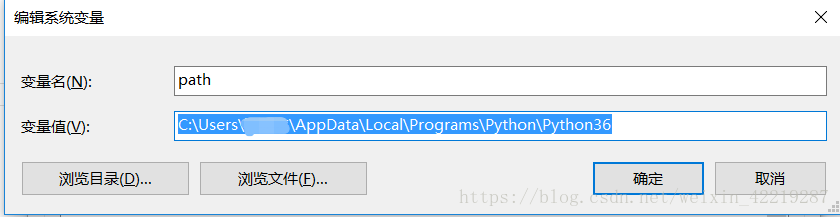
注意:Path 路径有的可能要在最后加上分号 ;
不知道python安装路径情况(红框就是安装路径)

4.2 PIP下载安装
1、先下载 pip 下载地址是:https://pan.baidu.com/s/1TROnH9jEhvbf_n7TnLORSA
2、选择 :pip-18.0.tar文件进行下载(2018/09/16)
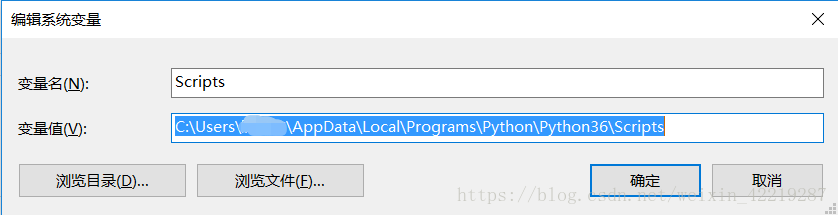
3、下载完成之后,解压到一个文件夹,用CMD控制台进入解压目录,输入:python setup.py install (环境变量没配置好无法调用python命令,推荐一款CMD增强版软件powercmd,下载地址:https://pan.baidu.com/s/1JWACrS9lRqFLFPHbkyD7-w)
4、设置pip环境变量:C:\Users\****\AppData\Local\Programs\Python\Python36\Scripts
5、cmd中输入pip 检验是否安装成功