目录
1.3.4 Dynamic Pooling之Chunk-MaxPooling
3.2.1 Word Representation Learning
3.2.2 Text Representation Learning
1 TextCNN
TextCNN通过一维卷积来获取句子中n-gram的特征表示。TextCNN对文本浅层特征的抽取能力很强,在短文本领域如搜索、对话领域专注于意图分类时效果很好,应用广泛,且速度快,一般是首选;对长文本领域,TextCNN主要靠filter窗口抽取特征,在长距离建模方面能力受限,且对语序不敏感。

1.1 嵌入层(embedding layer)
textcnn使用预先训练好的词向量作embedding layer。对于数据集里的所有词,因为每个词都可以表征成一个向量,因此我们可以得到一个嵌入矩阵MM, MM里的每一行都是词向量。这个MM可以是静态(static)的,也就是固定不变。可以是非静态(non-static)的,也就是可以根据反向传播更新。
为什么采用不同大小的卷积核,不同的感受视野,卷积核的宽取词汇表的纬度,有利于语义的提取。
embedding layer分类:
- CNN-rand
作为一个基础模型,Embedding layer所有words被随机初始化,然后模型整体进行训练。
- CNN-static
模型使用预训练的word2vec初始化Embedding layer,对于那些在预训练的word2vec没有的单词,随机初始化。然后固定Embedding layer,fine-tune整个网络。
- CNN-non-static
同(2),只是训练的时候,Embedding layer跟随整个网络一起训练。
- CNN-multichannel
Embedding layer有两个channel,一个channel为static,一个为non-static。然后整个网络fine-tune时只有一个channel更新参数。两个channel都是使用预训练的word2vec初始化的。
1.2 Convolution Layer
文本卷积与图像卷积的不同之处在于只在文本序列的一个方向(垂直)做卷积,因此使用一维卷积
一维卷积带来的问题是需要设计通过不同 filter_size 的 filter 获取不同宽度的视野。
1.3 Pooling Layer
不同尺寸的卷积核得到的特征(feature map)大小也是不一样的,因此我们对每个feature map使用池化函数,使它们的维度相同。
1.3.1 One-Max Pooling
CNN中采用Max Pooling操作有几个好处:首先,这个操作可以保证特征的位置与旋转不变性,因为不论这个强特征在哪个位置出现,都会不考虑其出现位置而能把它提出来。但是对于NLP来说,这个特性其实并不一定是好事,因为在很多NLP的应用场合,特征的出现位置信息是很重要的,比如主语出现位置一般在句子头,宾语一般出现在句子尾等等。 其次,MaxPooling能减少模型参数数量,有利于减少模型过拟合问题。因为经过Pooling操作后,往往把2D或者1D的数组转换为单一数值,这样对于后续的Convolution层或者全联接隐层来说无疑单个Filter的参数或者隐层神经元个数就减少了。 再者,对于NLP任务来说,可以把变长的输入X整理成固定长度的输入。因为CNN最后往往会接全联接层,而其神经元个数是需要事先定好的,如果输入是不定长的那么很难设计网络结构。
但是,CNN模型采取MaxPooling Over Time也有缺点:首先特征的位置信息在这一步骤完全丢失。在卷积层其实是保留了特征的位置信息的,但是通过取唯一的最大值,现在在Pooling层只知道这个最大值是多少,但是其出现位置信息并没有保留;另外一个明显的缺点是:有时候有些强特征会出现多次,出现次数越多说明这个特征越强,但是因为Max Pooling只保留一个最大值,就是说同一特征的强度信息丢失了。
1.3.2 Average Pooling
1.3.3 K-Max Pooling
取所有特征值中得分在Top –K的值,并(保序拼接)保留这些特征值原始的先后顺序(即多保留一些特征信息供后续阶段使用)

1.3.4 Dynamic Pooling之Chunk-MaxPooling
把某个Filter对应的Convolution层的所有特征向量进行分段,切割成若干段后,在每个分段里面各自取得一个最大特征值,比如将某个Filter的特征向量切成3个Chunk,那么就在每个Chunk里面取一个最大值,于是获得3个特征值。因为是先划分Chunk再分别取Max值的,所以保留了比较粗粒度的模糊的位置信息;当然,如果多次出现强特征,则也可以捕获特征强度。至于这个Chunk怎么划分,可以有不同的做法,比如可以事先设定好段落个数,这是一种静态划分Chunk的思路;也可以根据输入的不同动态地划分Chunk间的边界位置,可以称之为动态Chunk-Max方法。
2 TextRNN
尽管TextCNN能够在很多任务里面能有不错的表现,但CNN有个最大问题是固定 filter_size 的视野,一方面无法建模更长的序列信息,另一方面 filter_size 的超参调节也很繁琐。
3 TextRCNN
首先先解释一下为啥叫做 RCNN:一般的 CNN 网络,都是卷积层 + 池化层。这里是将卷积层换成了双向 RNN,所以结果是,两向 RNN + 池化层。
参考 https://blog.csdn.net/Kaiyuan_sjtu/article/details/84536256
https://zhuanlan.zhihu.com/p/42201550
3.1 模型框架

3.2 框架训练过程
3.2.1 Word Representation Learning
为了更准确地表达单词的意思,作者使用了单词本身和其上下文来表示这个词。在论文中,使用双向循环结构来实现。使用Cl(Wi)来定义词Wi左边的文本,Cr(Wi)来定义词右边文本。这里Cl(Wi)和Cr(Wi)是长度为|c|的稠密向量。从框架结构图中左边一块的箭头指向可以发现Cl(Wi)和Cr(Wi)的计算公式如下:

以“A sunset stroll along the South Bank affords an array of stunning vantage points” 这句话为例分析,结合上图,Cl(W7)表示了“Bank”这个词左侧的上下文语义信息(即“stroll along the South ”),同理,Cr(W7)表示了“Bank”这个词右侧的上下文语义信息(即“ affords an array ...”)。据此,我们就可以定义单词Wi的向量表示:
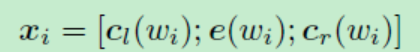
循环结构可以在文本的向前扫描时获取所有的Cl,在反向扫描时获取所有的Cr。时间复杂度为O(n)。当我们获得了单词Wi的表示Xi后,我们将一个线性变换与tanh激活函数一起应用到Xi,并将结果传递到下一层。

y是一个潜在的语义向量,每一个语义因素都将被分析,以确定代表文本的最有用的因素。
3.2.2 Text Representation Learning
上面部分是单词的表示,那么怎么来提取文本的特征表示呢?作者在这里使用了CNN,当前面所有的单词表示y都计算出来以后,接上一个max-pooling层
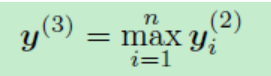
这里的max函数是一个按元素max的函数,也就是说,前一步单词表达得到的y是一个n维向量,这一步y的第k个元素是上一步y的所有向量的第k个元素的最大值。池化层将不同长度的文本转换为固定长度的向量。通过使用池化层,我们可以在整个文本中捕获信息。还有其他类型的池层,比如平均池层(Collobert et al. 2011)。我们这里不使用平均池,因为这里只有几个单词和它们的组合对于捕获文档的含义非常有用。在文档中,最大池化层试图找到最重要的潜在语义因素。
模型的最后一部分是输出层:
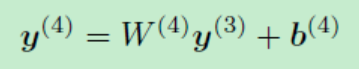
最后对y应用softmax得到概率:

3 LSTM
LSTM结构(图右)和普通RNN的主要输入输出区别如下所示。


3.1 Forget Gate遗忘门
在我们 LSTM 中的第一步是决定我们会从细胞状态中丢弃什么信息。这个决定通过一个称为忘记门层完成。该门会读取和
,输出一个在 0到 1之间的数值给每个在细胞状态
中的数字。1 表示“完全保留”,0 表示“完全舍弃”。
让我们回到语言模型的例子中来基于已经看到的预测下一个词。在这个问题中,细胞状态可能包含当前主语的性别,因此正确的代词可以被选择出来。当我们看到新的主语,我们希望忘记旧的主语。

其中表示的是上一个cell的输出,
表示的是当前细胞的输入。
表示sigmod函数。
3.2 Input Gate输入门
下一步是决定让多少新的信息加入到 cell 状态 中来。实现这个需要包括两个步骤:首先,一个叫做“input gate layer ”的 sigmoid 层决定哪些信息需要更新;一个 tanh 层生成一个向量,也就是备选的用来更新的内容。在下一步,我们把这两部分联合起来,对 cell 的状态进行一个更新。

现在是更新旧细胞状态的时间了, 更新为
。前面的步骤已经决定了将会做什么,我们现在就是实际去完成。
我们把旧状态与相乘,丢弃掉我们确定需要丢弃的信息。接着加上
。这就是新的候选值,根据我们决定更新每个状态的程度进行变化。
在语言模型的例子中,这就是我们实际根据前面确定的目标,丢弃旧代词的性别信息并添加新的信息的地方。

3.3 Output Gate输出门
最终,我们需要确定输出什么值。这个输出将会基于我们的细胞状态,但是也是一个过滤后的版本。首先,我们运行一个 sigmoid 层来确定细胞状态的哪个部分将输出出去。接着,我们把细胞状态通过 tanh 进行处理(得到一个在 -1 到 1 之间的值)并将它和 sigmoid 门的输出相乘,最终我们仅仅会输出我们确定输出的那部分。
在语言模型的例子中,因为他就看到了一个 代词,可能需要输出与一个 动词 相关的信息。例如,可能输出是否代词是单数还是负数,这样如果是动词的话,我们也知道动词需要进行的词形变化。

4 BiLSTM
前向的LSTM与后向的LSTM结合成BiLSTM。
5 GRU(Gated Recurrent Unit )
https://zhuanlan.zhihu.com/p/32481747
在LSTM中引入了三个门函数:输入门、遗忘门和输出门来控制输入值、记忆值和输出值。而在GRU模型中只有两个门:分别是更新门和重置门。具体结构如下图所示:

图中的和
分别表示更新门和重置门。更新门用于控制前一时刻的状态信息被带入到当前状态中的程度,更新门的值越大说明前一时刻的状态信息带入越多。重置门控制前一状态有多少信息被写入到当前的候选集
上,重置门越小,前一状态的信息被写入的越少。
关于LSTM和GRU的反向传播可以参考这篇文章:
