一、写在前面
这个系列还有peephole,couple 等
这部分内容应该算是近几年发展中最基础的部分了,但是发现自己忘得差不多了,很多细节记得不是很清楚了,故写这篇博客,也希望能够用更简单清晰的思路来把这部分内容说清楚,以此能够帮助更多的朋友,对于理解错误的地方也希望各位能够留下宝贵的意见,觉得不错别忘了点赞鼓励一下。有条件的童鞋可以看看这篇论文,详细的说明了RNN、LSTM、GRU的计算过程,个人认为如果是要走学术方向的朋友值得细读这篇论文,里面不仅仅涉及到循环神经网络的详细计算过程,而且还实验了很多方法,TF代码实现也是基于这篇论文实现的。
二、循环(递归)神经网络RNN
1、神经网络
在开始RNN之前我们先简单的回顾一下神经网络,下图就是一个简单的神经网络的示例:
-
Input Layer:输入层,输入的( x 1 , x 2 , x n x_1,x_2,x_n x1,x2,xn)是一条样本的向量表示,例如字、词、句子等向量。
-
Hidden Layer:隐层,每一层的圆圈都是神经元,一般都是( x 1 , x 2 , x n x_1,x_2,x_n x1,x2,xn)进行一次线性变换后的结果会在每一个神经元内部再进行一次非线性转换,也就是每个神经元内部都有激活函数对输入的值进行非线性转换。
-
Output Layer:输出层,对隐层的最后结果进行概率计算,在神经网络中一般使用的是softmax分类器,其实质是对隐层提取的特征值进行线性求和之后输出0~1的值,值越大就代表着该条数据属于这个类别的概率越大。
2、循环神经网络
至于为什么会有RNN呢,其实是因为上面提到的神经网络中,每一条样本的特征值在隐层中的计算都是相互独立的,然而其实很多任务每一条样本的特征值之间都是有关联的,所以我们需要去考虑这种相关因素,这种需求主要是在NLP任务中,所以有了RNN来加入‘记忆’的方式来把样本特征值之间的相关信息加入进去。RNN的网络结构示例如下图:
进入正题之前先对输入举个栗子,以免刚接触的朋友产生误解,假设样本数据是:‘我爱你’,然后我们对每一个字进行字向量之后就成了: ( ( x 1 1 , x 1 2 , x 1 3 ) , ( x 2 1 , x 2 2 , x 2 3 ) , ( x 3 1 , x 3 2 , x 3 3 ) ) ((x_1^1,x_1^2,x_1^3),(x_2^1,x_2^2,x_2^3),(x_3^1,x_3^2,x_3^3)) ((x11,x12,x13),(x21,x22,x23),(x31,x32,x33)),分别对应的是我爱你三个字,每个字都是一个三维的向量,上图中的input就是其中一个字的三维向量。在RNN中有多少个三维向量就是代表着有多少个时刻或者step。顺便提一下,实际情况中的输入是一个矩阵,0维度也就是矩阵的行数就是你的字向量维度,1维也就是矩阵的列数就是你的batch_size大小。 -
Input:输入层,就是例子中的一个三维向量,是样本中的一个特征向量,和上面的传统神经网络不同,这里是一个特征向量,上面的是一条样本的向量。
-
Hidden inputs:隐层,和神经网络的隐层是一样的效果。
-
Bias node:偏置项在计算隐层和输出层时加上一个偏置项(也就是高中所学的一元一次函数的截距项)。
-
Output:输出层,同上诉神经网络的输出层。
为了接下来更加清楚的解释RNN前后向传播过程,对以下参数进行详细解释:
- x t x_t xt:时刻t的输入,一个向量。
- h t h_t ht: 时刻t的隐藏状态,也就是上图中Hidden inputs层各个神经元的输出值。
- o t o_t ot :代表时刻t的输出,也就是Output输出的概率值,注意不是标签值。
- U:输入层到隐层之间的权重,它将我们原始的输入进行抽象作为隐层的输入,也就是上图灰色- 虚线的部分。
- V:隐藏层到输出层之间的权重,它将我们在隐层学习到的表示再次抽象,作为最终的输出,也就是上图中红色虚线的部分。
- W:隐层到隐层之间的权重,只要是隐层和隐层之间的权重都用W表示,也就是上图的红色实线部分。
为了方便在阅读以下内容的时候,脑海里能有一个图像,我自己画了简单的图,供大家想象,如下: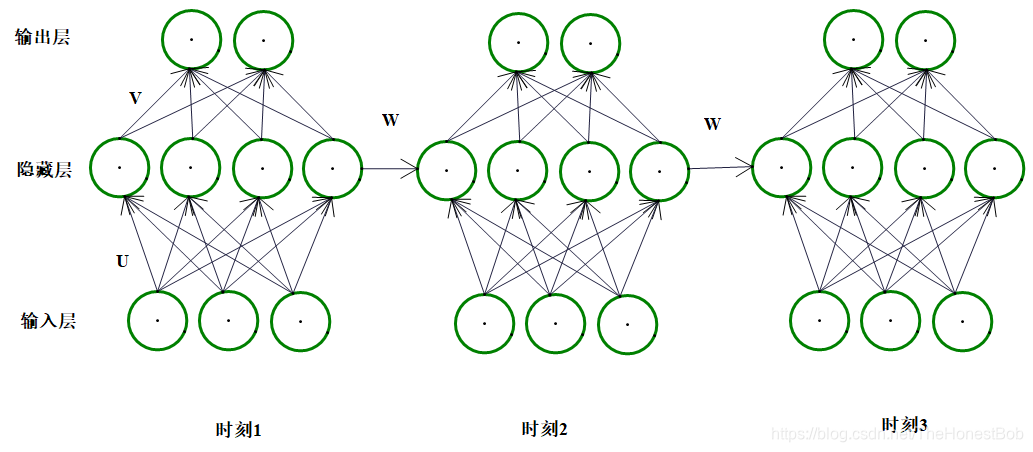
下图是上图的简图,结构是一样的,希望大家不要搞混淆了:
顺便提一下,下图中的圆圈在RNN中我们称之为细胞,也就是整个隐层,这点希望刚接触RNN的朋友一定要记住了。
接下来我们进行前向传播
在t=1时刻,U、V、W都被随机初始化好, h 0 h_0 h0 通常被初始化为0,然后进行如下计算:
- h 1 = f ( U x 1 + W h 0 + b 1 ) h_1=f(Ux_1+Wh_0+b_1) h1=f(Ux1+Wh0+b1)(隐藏层的输出, f f f是激活函数)
- O 1 = g ( V h 1 + b 2 ) O_1=g(Vh_1+b_2) O1=g(Vh1+b2)(最终的输出, g g g是softmax等函数)
在t=2时刻,此时的 h 1 h_1 h1作为时刻1的记忆,将进行接下来的预测,计算如下:
- h 2 = f ( U x 2 + W h 1 + b 1 ) h_2=f(Ux_2+Wh_1+b_1) h2=f(Ux2+Wh1+b1)
- O 2 = g ( V h 2 + b 2 ) O_2=g(Vh_2+b_2) O2=g(Vh2+b2)
以此类推,可得:
- h t = f ( U x t + W h t − 1 + b 1 ) h_t=f(Ux_t+Wh_{t-1}+b1) ht=f(Uxt+Wht−1+b1)
- O t = g ( V h t + b 2 ) O_t=g(Vh_t+b_2) Ot=g(Vht+b2)
顺便提一下,经过查看tensorflow源码得到如下答案,也就是说大多数基础的RNN的记忆信息就是隐层的输出,因为我没有找到最原始的RNN论文,无从考究原始RNN是否如此,而且通过源码发现RNN已经有了很大改进,例如对输入或者隐层神经元的dropout用法,有兴趣的可以去看tensorflow源码。其实RNN部分已经封装的很好了,只要理解原理就可以了。
其中 f f f可以是tanh、relu、logistic等激活函数, g g g通常是softmax也可以是其他,我们说RNN具有记忆能力,而这种能力就是通过W将以往的输入状态进行总结,作为下次的辅助输入,可以这样理解隐藏状态: h = f ( 现 有 的 输 入 + 之 前 的 记 忆 总 结 ) h=f(现有的输入+之前的记忆总结) h=f(现有的输入+之前的记忆总结)
接下来我们进行反向传播(BPTT)
反向传播的用到的方法是,将输出层的误差总和对各个权重的梯度 ∇ U 、 ∇ V 、 ∇ W \nabla U、\nabla V、\nabla W ∇U、∇V、∇W求偏导,然后用梯度下降法更新各个参数,对于梯度下降算法不太了解的童鞋可以参考我之前的一篇博客梯度下降算法原理及其计算过程,对于每一时刻的输出 O t O_t Ot都会产生一定的误差 e t e_t et,误差的损失函数可以是交叉熵损失函数也可以是平方误差等等。那么总的误差为 E = ∑ 1 t e t E=\sum_1^t e_t E=∑1tet。我们最终的目标就是要求取:
- ∇ U = ∂ E ∂ U = ∑ 1 t ∂ e t ∂ U \nabla U=\cfrac{\partial E}{\partial U}=\sum_1^t\cfrac{\partial e_t}{\partial U} ∇U=∂U∂E=∑1t∂U∂et
- ∇ V = ∂ E ∂ V = ∑ 1 t ∂ e t ∂ V \nabla V=\cfrac{\partial E}{\partial V}=\sum_1^t\cfrac{\partial e_t}{\partial V} ∇V=∂V∂E=∑1t∂V∂et
- ∇ W = ∂ E ∂ W = ∑ 1 t ∂ e t ∂ W \nabla W=\cfrac{\partial E}{\partial W}=\sum_1^t\cfrac{\partial e_t}{\partial W} ∇W=∂W∂E=∑1t∂W∂et
为了容易理解,这里损失函数使用平方损失函数: L ( θ ) = 1 2 ( y ^ − y ) 2 L(\theta)=\cfrac12(\hat y -y)^2 L(θ)=21(y^−y)2。
可能看到公式脑袋就大,但是我接下来的公式过程,可能是有史以来最简单的过程了,只要链式求导法则和梯度下降算法搞明白了,小学生都能看懂,欢迎大家指正。链式求导法则在此举个例子: f ( x ) = 2 x + 1 , g ( u ) = u 2 f(x)=2x+1,g(u)=u^2 f(x)=2x+1,g(u)=u2,那么对于复合函数 g ( f ( x ) ) = ( 2 x + 1 ) 2 g(f(x))=(2x+1)^2 g(f(x))=(2x+1)2求导过程如下: ∂ g ∂ x = ∂ g ∂ u ⋅ ∂ u ∂ x = 2 u ⋅ 2 = 4 u = 8 x + 4 \cfrac{\partial g}{\partial x}=\cfrac{\partial g}{\partial u}\cdot\cfrac{\partial u}{\partial x}=2u\cdot2=4u=8x+4 ∂x∂g=∂u∂g⋅∂x∂u=2u⋅2=4u=8x+4,好了我们开始BPTT。
首先我们把公式全部归纳一下:
s t = u x t + w h t − 1 + b 1 s_t=ux_t+wh_{t-1}+b_1 st=uxt+wht−1+b1:这里是为了我后面写公式方便把 h 1 = f ( U x 1 + W h 0 + b 1 ) h_1=f(Ux_1+Wh_0+b_1) h1=f(Ux1+Wh0+b1)拆分了。
h t = f ( s t ) h_t=f(s_t) ht=f(st): f f f为激活函数。
o t = g ( v h t + b 2 ) o_t=g(vh_t+b_2) ot=g(vht+b2)
e t = 1 2 ( o t − y ) 2 e_t=\cfrac12(o_t-y)^2 et=21(ot−y)2:这是每一时刻的误差。
E = ∑ 1 t e t E=\sum_1^te_t E=∑1tet:这是总的误差。
根据梯度下降进行参数更新,印象不深的可以再回顾一下梯度下降算法。
因为RNN的参数是共享的,虽然说分了好多个时刻,但是参数只有 U 、 V 、 W 、 b 1 、 b 2 U、V、W、b_1、b_2 U、V、W、b1、b2五个参数,要将误差反向传播来更新参数,最重要的就是要求我们的损失函数 E = ∑ 1 t e t E=\sum_1^te_t E=∑1tet的梯度,我们令梯度为 Δ \Delta Δ,则有:
Δ = < ∂ E ∂ U , ∂ E ∂ V , ∂ E ∂ W , ∂ E ∂ b 1 , ∂ E ∂ b 2 > \Delta=<\frac{\partial E}{\partial U},\frac{\partial E}{\partial V},\frac{\partial E}{\partial W},\frac{\partial E}{\partial b_1},\frac{\partial E}{\partial b_2}> Δ=<∂U∂E,∂V∂E,∂W∂E,∂b1∂E,∂b2∂E>
根据链式求导法则我们来求一下各自的偏导数
∂ E ∂ U = ∑ 1 t ∂ e t ∂ U = ∑ 1 t ∂ e t ∂ ( o t − y ) ⋅ ∂ ( o t − y ) ∂ o t ⋅ ∂ o t ∂ ( v h t + b 2 ) ⋅ ∂ ( v h t + b 2 ) ∂ h t ⋅ ∂ h t ∂ s t ⋅ ∂ s t ∂ U = ∑ 1 t ( o t − y ) ⋅ 1 ⋅ g ′ ( v h t + b 2 ) ⋅ v ⋅ f ′ ( s t ) ⋅ x t \frac{\partial E}{\partial U}=\sum_1^t\frac{\partial e_t}{\partial U}=\sum_1^t\frac{\partial e_t}{\partial {(o_t-y)}}\cdot \frac{\partial (o_t-y)}{\partial o_t}\cdot \frac{\partial o_t}{\partial (vh_t+b_2)}\cdot \frac{\partial (vh_t+b_2)}{\partial h_t}\cdot \frac{\partial h_t}{\partial s_t}\cdot\frac{\partial s_t}{\partial U}=\sum_1^t(o_t-y)\cdot1\cdot g'(vh_t+b_2)\cdot v\cdot f'(s_t)\cdot x_t ∂U∂E=∑1t∂U∂et=∑1t∂(ot−y)∂et⋅∂ot∂(ot−y)⋅∂(vht+b2)∂ot⋅∂ht∂(vht+b2)⋅∂st∂ht⋅∂U∂st=∑1t(ot−y)⋅1⋅g′(vht+b2)⋅v⋅f′(st)⋅xt
剩下的部分交给勤奋的你来进行推导了, 以此类推就可以把 Δ \Delta Δ的值求出来了,求出来我们就可以反向传播不断更新参数让我们的损失最小化了,其实实际上都是矩阵的运算,比较烧脑了,感兴趣的可以再深入一点,实际上BP算法是非常重要的,不过呢代码实现的时候都已经封装好了,不需要我们自己设计BP算法的实现过程。
掌握了链式求导法则和梯度下降算法之后,不仅仅掌握了BPTT,其实我们也不难发现,梯度爆炸和消失的根本原因,因为我们的参数更新是在给定的学习率的情况下沿着梯度的负方向进行更新的,如果我们的梯度在不断的连乘小于1的数或者很大的数,那么就会出现梯度消失和爆炸的情况,LSTM和GRU为了解决梯度消失,而梯度爆炸则是梯度给定一个阈值C,大于C或者小于-C的值都设置为了C或者-C,梯度爆炸或者消失这部分看以后有需要了单开一篇博客吧。接下来我们进入LSTM的大门。
我觉得还是再多说几句,为什么RNN的BP过程称之为BPTT呢,全称是Backpropagation Through Time,区别在于BPTT每一步的输出不仅仅依赖当前步的网络,并且还需要钱若干步的网络状态,所以称之为BPTT。
三、LSTM原理详解
可能对LSTM有了解的朋友,知道LSTM的出现就是为了缓解RNN的一个最大的缺点,长时依赖的问题,随着序列长度的增加,会出现之前的信息丢失的问题,那么我们首先来看一下,为什么说RNN会有这个问题。 我们通过下面的计算过程来看看问题出在哪里了。为了书写简单,偏置项暂时不考虑。
h 0 = 0 h_0=0 h0=0
h 1 = f ( u x 1 + w h 0 ) h_1=f(ux_1+wh_0) h1=f(ux1+wh0)
h 2 = f ( u x 2 + w h 1 ) h_2=f(ux_2+wh_1) h2=f(ux2+wh1)
h 3 = f ( u x 3 + w h 2 ) h_3=f(ux_3+wh_2) h3=f(ux3+wh2)
⋅ \cdot ⋅
⋅ \cdot ⋅
⋅ \cdot ⋅
h t = f ( u x t + w h t − 1 ) h_t=f(ux_t+wh_{t-1}) ht=f(uxt+wht−1)
其实我们可以从这个简单的过程可以看到,记忆信息的传递依赖的 w w w参数 ,但是随着时刻的增多,当 w w w不断的连乘, w w w值过小会导致之前的信息丢失, w w w过大会导致之前的信息权重比当前时刻的输入大,基于这种情况,LSTM对传统的RNN进行了改进,主要是加入了一个细胞状态的机制,对于最终的输出,先前记忆中重要的继续传递下去,不重要的就截断了。接下来我们来分析一下LSTM的结构。 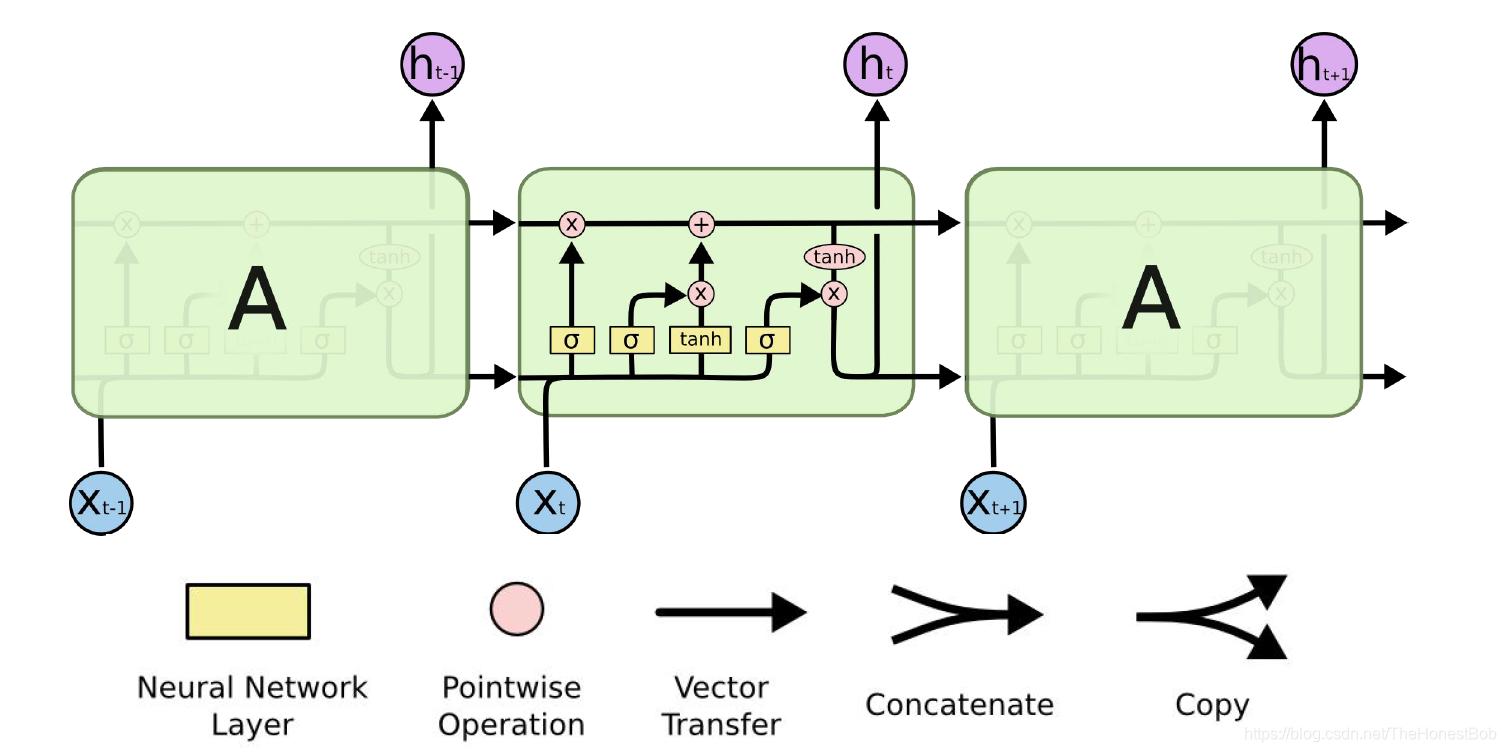
其实呢这张图网上都有,虽然很多人说这个图其实对新学者很不友好,但是我还不知道什么工具可以画这个图,不知道有没有大佬可以告诉我的,我会把这张图的每一个细节和容易产生误区的地方都会说的很详细,以弥补没有自己原创图的缺失。
3.1 LSTM结构详解
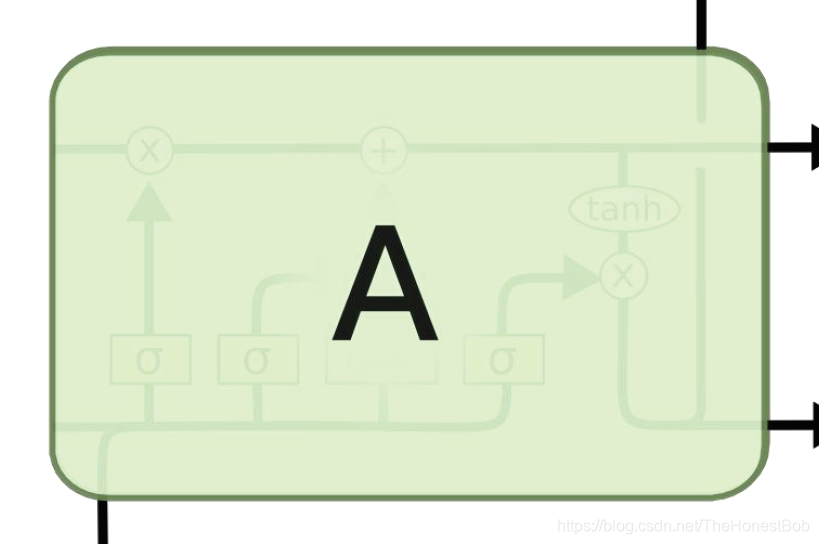
这就是RNN中的一整个隐藏层,切记!是整个隐藏层,很多刚接触的朋友以为他是神经元。
从左到右分别是:
1.神经网络层,相当于一个全连接层,包含了很多神经单元,也就是LSTM代码里面的units参数。
2.矩阵的运算法则,乘法或者加法,当然这个乘法是普通的乘法,对应数字相乘。
3.向量的转移方向,指明数据下一步的去向。
4.concat,按列拼接,也就是两个矩阵按列拼接。
5.复制,也就是这两个去向的数据是一样的。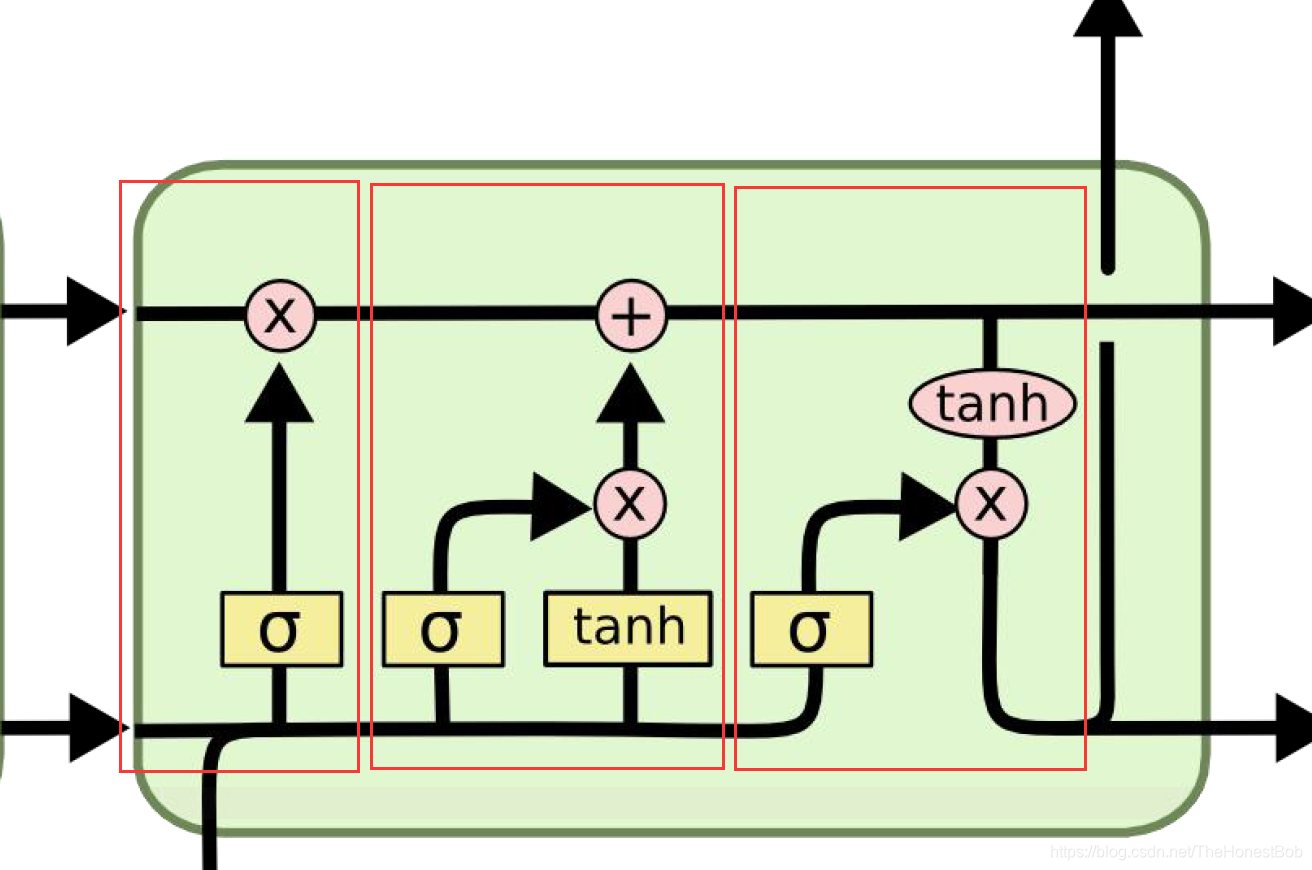
上图中框起来三个部分就是耳熟能详的门,也是很多刚接触LSTM的朋友容易搞不清楚的门,我们接下来对这三个门的工作原理进行剖析,深入理解原理。首先对于有个概念大家可以这样理解,在LSTM中可以认为 h t h_t ht是当前时刻的记忆信息, C t C_t Ct是当前时刻以及之前的记忆信息总和,这也是为什么大家叫它为长短时记忆网络的原因。从左往右分别是: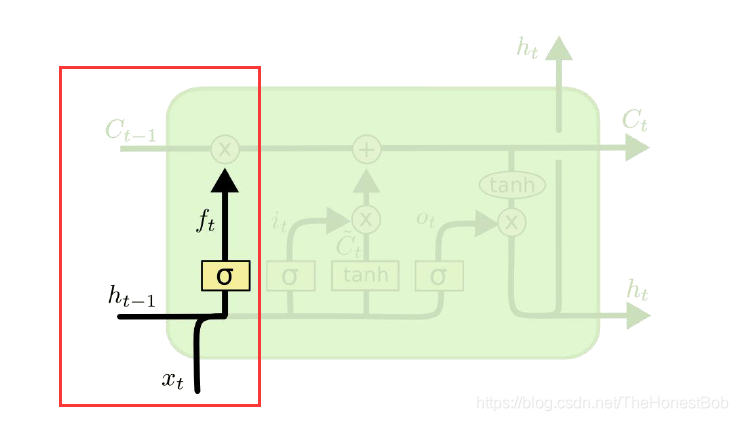
1.遗忘门:
首先解释一下第一个框的数据流向,首先是上一时刻的隐层输出 h t − 1 h_{t-1} ht−1和当前时刻 x t x_t xt进行concat,也就是拼接然后输入到黄色的 σ \sigma σ神经网络层进行全连接后sigmoid激活,输出0到1的概率值 f t f_t ft, f t = σ ( W f ⋅ [ h t − 1 , x t ] + b f ) f_t=\sigma(W_f\cdot[h_{t-1},x_t]+b_f) ft=σ(Wf⋅[ht−1,xt]+bf),用来描述每个部分多少量可以通过,0不允许通过,1全部通过。然后输出的值和上一时刻的细胞状态 C t − 1 C_{t-1} Ct−1进行乘法操作,然后往右传递进入下一个框框。好了语言描述到此结束,我想认真思考的朋友应该能够很明白了,接下来我们来举个具体的例子,看看数据在这个过程中的计算过程,这样就能够确保大家完全理解遗忘门了。
说明:为了书写方便和理解简单,下面计算过程的数据是矩阵的形状,设输入维度为10,数据批次大小为1,也就是每次只输入一个序列。units=20,也就是全连接层的神经元个数为20。则各个数据的形状如下:
x t = 10 × 1 x_t=10\times1 xt=10×1:形状取决于你的词向量维度
h t − 1 = 20 × 1 h_{t-1}=20\times1 ht−1=20×1:形状取决于你的隐层神经元个数
[ x 1 , h 0 ] = 30 × 1 [x_1,h_0]=30\times1 [x1,h0]=30×1
W f ⋅ [ h t − 1 , x t ] = 20 × 30 ⋅ 30 × 1 = 20 × 1 W_f\cdot[h_{t-1},x_t]=20\times30\cdot30\times1=20\times1 Wf⋅[ht−1,xt]=20×30⋅30×1=20×1
W f ⋅ [ h t − 1 , x t ] + b f = 20 × 1 + 20 × 1 = 20 × 1 W_f\cdot[h_{t-1},x_t]+b_f=20\times1+20\times1=20\times1 Wf⋅[ht−1,xt]+bf=20×1+20×1=20×1
σ ( W f ⋅ [ h t − 1 , x t ] + b f ) = 20 × 1 \sigma(W_f\cdot[h_{t-1},x_t]+b_f)=20\times1 σ(Wf⋅[ht−1,xt]+bf)=20×1
f t × C t − 1 = 20 × 1 × 20 × 1 = 20 × 1 f_t\times C_{t-1}=20\times1\times20\times1=20\times1 ft×Ct−1=20×1×20×1=20×1
在此提醒一下,在TF代码实现的时候, h t − 1 h_{t-1} ht−1和 x t x_t xt各自的权重是分开的,采用了不同的初始化和正则化方法,此文更多的是对原理过程的描述,可能与实际代码实现有出入,感兴趣的朋友可以直接查看源码。
到这里我相信大家都能完全理解遗忘门的计算过程了,那么我们来思考一下,为什么细胞状态C能够实现该记住哪些记忆,又改忘记哪些记忆呢,举个简单的例子,假设:
C t − 1 = [ 0.8 , 1.2 , 3.2 ] C_{t-1}=[0.8,1.2,3.2] Ct−1=[0.8,1.2,3.2]
f t = [ 0 , 0.5 , 1 ] f_t=[0,0.5,1] ft=[0,0.5,1]
那么 f t × C t − 1 = [ 0 , 0.6 , 3.2 ] f_t\times C_{t-1}=[0,0.6,3.2] ft×Ct−1=[0,0.6,3.2]是不是相当于 f t f_t ft为0的位置的信息被丢弃了,0.5的位置只保留了一半,而1的地方我全部保留并往下传递了。总结起来说,通过这个门,我们就能够决定丢弃细胞状态C中的哪些信息。所以称之为遗忘门或者忘记门。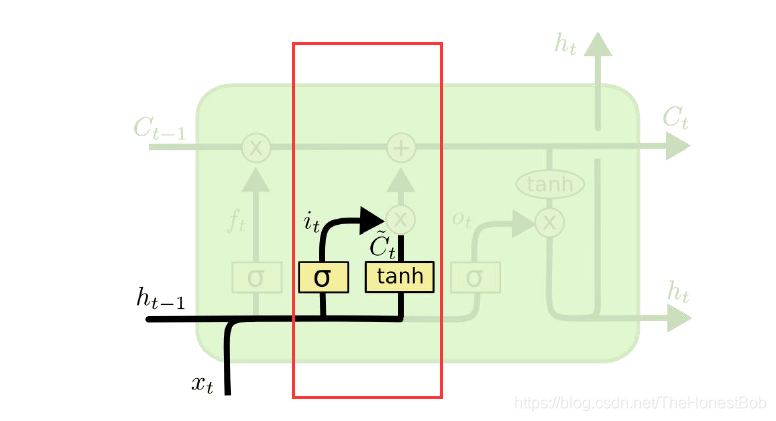
2.信息增加门:
有了之前遗忘门的基础,自然可以很好的理解信息增加门,顾名思义通过遗忘门模型知道了该丢弃哪些信息,那么还需要通过信息增加门在确定,需要增加哪些新的信息到细胞状态C中去,这也是增加门的作用。
公式如下:
i t = σ ( W i ⋅ [ h t − 1 , x t ] + b i ) i_t=\sigma(W_i\cdot[h{t-1},x_t]+b_i) it=σ(Wi⋅[ht−1,xt]+bi)
C ~ t = t a n h ( W c ⋅ [ h t − 1 , x t ] + b c ) \tilde C_t=tanh(W_c\cdot[h_{t-1},x_t]+b_c) C~t=tanh(Wc⋅[ht−1,xt]+bc)
C t = f t ⋅ C t − 1 + i t ⋅ C ~ t C_t=f_t\cdot C_{t-1}+i_t\cdot\tilde C_t Ct=ft⋅Ct−1+it⋅C~t:由此可以看出C的取值范围是比较大的。
Sigmoid层决定什么值需要更新;Tanh层创建一个新的候选向量 C ~ t \tilde C_t C~t;然后通过计算 i t × C ~ t i_t\times\tilde C_t it×C~t就可以计算出当前时刻需要增加哪些信息,然后与 f t ⋅ C t − 1 f_t\cdot C_{t-1} ft⋅Ct−1相加就可以得到 C t C_t Ct。
总结起来就是经过这两个门后,就可以确定传递信息的删除和增加,即进行细胞状态的更新。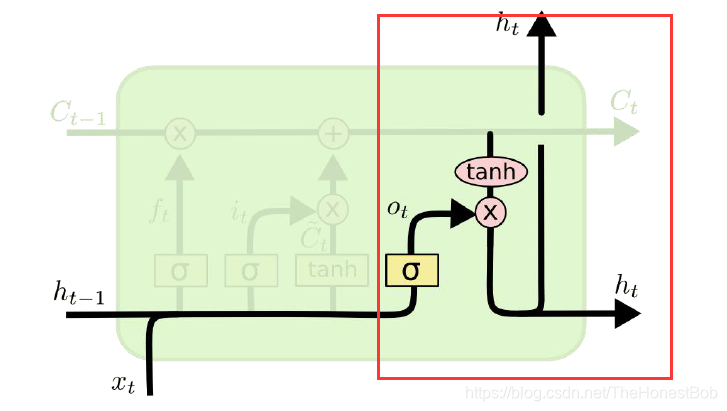
3.输出门
这部分就是根据细胞状态得到输出。
公式如下:
o t = σ ( W o ⋅ [ h t − 1 , x t ] + b o ) o_t=\sigma(W_o\cdot[h_{t-1},x_t]+b_o) ot=σ(Wo⋅[ht−1,xt]+bo)
h t = o t × t a n h ( C t ) h_t=o_t\times tanh(C_t) ht=ot×tanh(Ct)
首先通过一个sigmoid层来确定细胞状态的哪个部分将输出,然后使用tanh函数处理细胞状态得到-1到1的值,在和sigmoid输出相乘,输出当前时刻的输出 h t h_t ht。至此LSTM的结构解释就告一段落了,接下来我们来看看LSTM的前后向传播过程。
3.2 LSTM的BPTT
说明:其实了解了LSTM的结构之后其实对于BPTT过程掌握与否个人认为并不是太重要,毕竟现在各种框架都已经封装好了,不需要我们自己去实现,此处也是为了此文的完整故对LSTM的BPTT进行相关描述,以此有助于大家理解LSTM的结构原理,LSTM的BPTT和RNN的类似,也不复杂。下面我们进行BPTT过程的推导,过程并不复杂,一点都不烧脑。
1.前向传播
前向传播比较简单,就是我们上面几个门的公式的合并:
f t = σ ( W f ⋅ [ h t − 1 , x t ] + b f ) f_t=\sigma(W_f\cdot[h_{t-1},x_t]+b_f) ft=σ(Wf⋅[ht−1,xt]+bf)
i t = σ ( W i ⋅ [ h t − 1 , x t ] + b i ) i_t=\sigma(W_i\cdot[h{t-1},x_t]+b_i) it=σ(Wi⋅[ht−1,xt]+bi)
C ~ t = t a n h ( W c ⋅ [ h t − 1 , x t ] + b c ) \tilde C_t=tanh(W_c\cdot[h_{t-1},x_t]+b_c) C~t=tanh(Wc⋅[ht−1,xt]+bc)
o t = σ ( W o ⋅ [ h t − 1 , x t ] + b o ) o_t=\sigma(W_o\cdot[h_{t-1},x_t]+b_o) ot=σ(Wo⋅[ht−1,xt]+bo)
C t = f t ⋅ C t − 1 + i t ⋅ C ~ t C_t=f_t\cdot C_{t-1}+i_t\cdot\tilde C_t Ct=ft⋅Ct−1+it⋅C~t
h t = o t × t a n h ( C t ) h_t=o_t\times tanh(C_t) ht=ot×tanh(Ct)
y ^ t = S ( W y ⋅ h t + b y ) \widehat{y}_t=S(W_y\cdot h_t+b_y) y
t=S(Wy⋅ht+by):这部分就是每一个时刻的输出的概率值,S为分类器,如softmax。
e t = 1 2 ( o t − y ) 2 e_t=\cfrac12(o_t-y)^2 et=21(ot−y)2
E = ∑ 1 t e t E=\sum_1^te_t E=∑1tet
2.反向传播
其实在RNN部分我们已经推导过一次了,原理都是一样,因为在LSTM中总共有 W f W i W c W o b f b i b c b o b y W_fW_iW_cW_ob_fb_ib_cb_ob_y WfWiWcWobfbibcboby总共9个参数,在此说明一下,可能有些文章中会说总共8组参数,其实在前文中我也提到了,在代码实现的时候,对于 x t x_t xt和 h t − 1 h_{t-1} ht−1的W权重是分开的,公式如下图: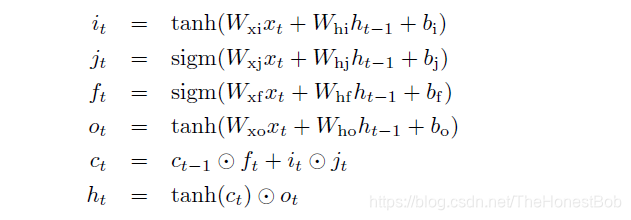
我的部分只是多加了一个每个时刻的输出部分,在代码过程中你可以设置相关参数,是否获取每一个时刻的输出。
反向传播就是根据损失函数E求取梯度值,然后根据梯度下降更新参数。过程很简单,写的有点累了,只要大家认真看到这里,掌握链式求导法则和梯度下降算法的完全可以无压力的进行简单的推导。交给有需要的你们自己动手推导啦。接下来我们进入另外一个比较重要的RNN变种GRU。
四、GRU结构原理
开始GRU之前先说明一下,其实根据LSTM的结构,我们可以根据自己的业务实际情况作出一些更改,所以实际上变种是非常的多的,下面我们列举三个有名的变种,并对其中的一种,也就是GRU进行描述。
第一种: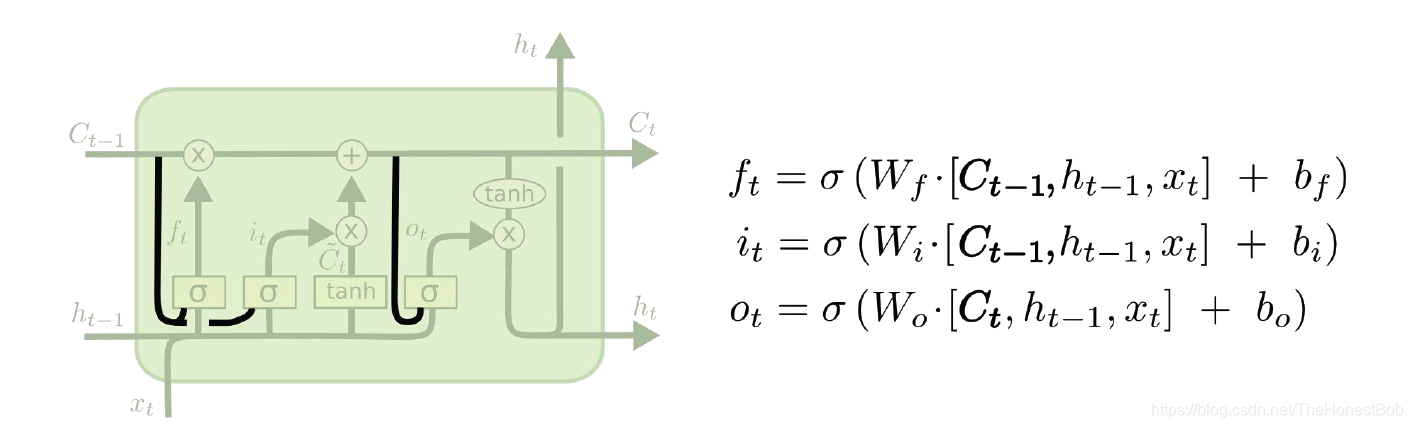
此种结构增加了一个peephole connections层,让每一个门也接收细胞状态C的输入。
第二种: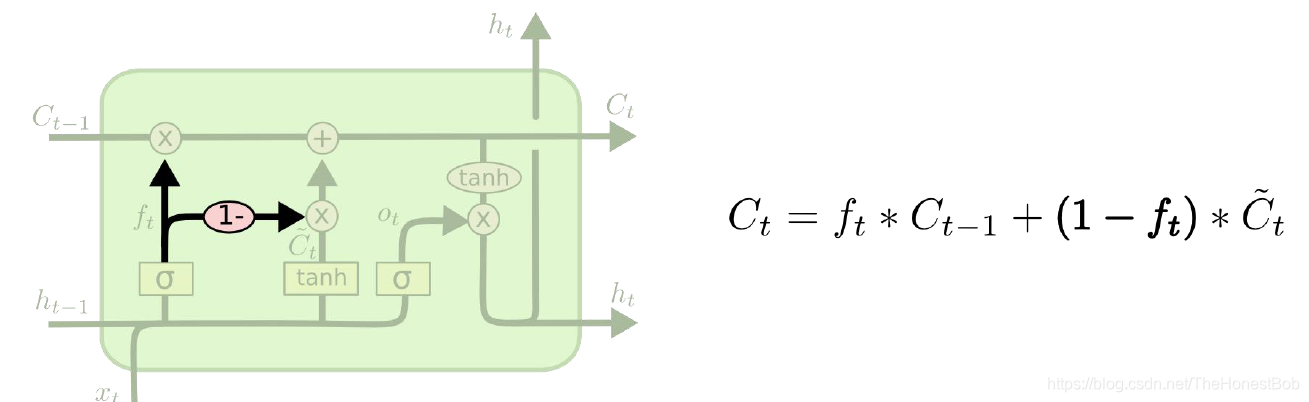
通过耦合遗忘门和信息增加门(第一个和第二个门);也就是不再单独的考虑忘记什么、增
加什么信息,而是一起进行考虑。至于为什么可以这样做的原因是第一个门控制哪些信息遗忘,第二门是决定哪些信息增加,刚好两者作用相反,所以可以把二者进行合并。
第三种:Gated Recurrent Unit(GRU)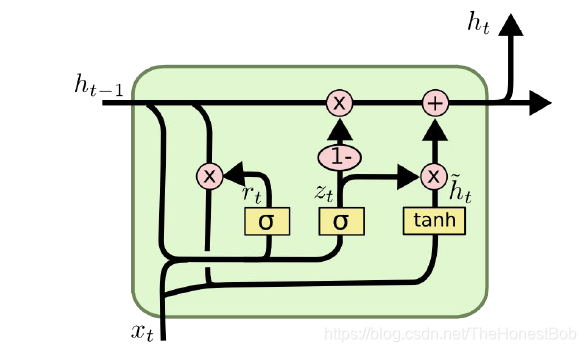
这种结构是2014年提出的,其实也算是对前两种的合并,没有了LSTM中的细胞状态的概念,把遗忘门和信息增加门进行合并为更新门,同时合并了数据单元状态和隐状态,比LSTM结构更加简单。
公式如下:
r t = σ ( W r ⋅ [ h t − 1 , x t ] ) r_t=\sigma(W_r\cdot[h_{t-1},x_t]) rt=σ(Wr⋅[ht−1,xt])
z t = σ ( W z ⋅ [ h t − 1 , x t ] ) z_t=\sigma(W_z\cdot[h_{t-1},x_t]) zt=σ(Wz⋅[ht−1,xt])
h ^ t = t a n h ( W ⋅ [ r t ∗ h t − 1 , x t ] ) \hat h_t=tanh(W\cdot[r_t*h_{t-1},x_t]) h^t=tanh(W⋅[rt∗ht−1,xt])
h t = ( 1 − z t ) ∗ h t − 1 + z t ∗ h ^ t h_t=(1-z_t)*h_{t-1}+z_t*\hat h_t ht=(1−zt)∗ht−1+zt∗h^t
通过了前面的理解之后,再来理解GRU就很简单了,任凭它们千变万化,也逃不出我们的火眼金睛,一眼便让他们原形毕露,哈哈哈,基于此我们也是可以设计我们自己的网络结构的,以更加的切合我们的实际业务场景,得到奇效。
五、写在最后
关于RNN部分的内容就到这里了,写出来也是为了记录自己所学,以此来帮助更多刚接触的朋友,也是希望能和更多的人交流,知道自己理解不准确的地方,如果觉得写得不错的话,记得点赞哟。顺便再贴出一篇谷歌的论文,这篇论文中的LSTM和我们所常见的结构有所不同,有条件的童鞋也可以看看,论文地址。