KMP算法
参考: http://www.matrix67.com/blog/archives/115 && 具宗万《算法问题实战策略》
1.1 任务
字符串检索问题。确认给定的“草堆”(haystack)字符串 H 中是否包含“缝衣针”(needle)子字符串 N ,如果包含,则找出子字符串N的起始位置。
KMP算法的任务就是实现一种能够在线性复杂度内求出一个串在另个一串的所在匹配位置。
1.2 说明
设“缝衣针”模板串是pattern,令next[i] = max{k | pattern[0…k-1] = pattern[i-k+1…i]}。实际上next[i]数组是pattern的第i个前缀中既是前缀又是后缀的字符串的最大长度。求解next[]可以使用动态规划,即next[i+1]可以由next[i],next[next[i]],……得到,实际上next[]数组的预处理过程就是一个pattern模板串“自我匹配”的过程。
给定pattern中的字符能够匹配的位置是,next[]会计算下一个其实位置,因此next[]数组又称为部分匹配表(partial match table)。
得到next[]数组后,设两个指针i和j,分别指向“草堆”字符串和“缝衣针”字符串,成功匹配则同时移动i和j,否则把j移动到next[j]。当j移动到“缝衣针”末尾时,就说明匹配成功了。
1.3 代码
假定next[]数组已经预处理完毕,下面给出“缝衣针”字符串 N 匹配“草堆字符串” H 的过程:
void KMP(const char M[], const char N[], const int next[])
{
int j = -1, ln = strlen(N);
for(int i = 0; M[i]; i++)
{
while(j >= 0 && N[j + 1] != M[i])
j = next[j];
if(N[j + 1] == M[i]) j = j + 1;
if(j == ln - 1)
{
cout<<"Pattern occurs with shift "<<i - j<<endl;
j = next[j];
}
}
}像section 2中说到的一样,next[]数组的预处理过程就是一个模板串“自我匹配”的过程。所以,生成 模板串 N 的部分匹配表next[]数组的代码和上面的代码神似:
void createNext(const char N[], int next[])
{
next[0] = -1;
int j = -1;
for(int i = 1; N[i]; i++)
{
while(j >= 0 && N[j + 1] != N[i])
j = next[j];
if(N[j + 1] == N[i]) j = j + 1;
next[i] = j;
}
}当然KMP()函数和createNext()函数是没有必要分开写的,完全可以把createNext()函数放在KMP()函数的前面进行合体:
void KMP(const char M[], const char N[], int next[])
{
next[0] = -1;
int j = -1, ln;
for(ln = 1; N[ln]; ln++)
{
while(j >= 0 && N[j + 1] != N[ln])
j = next[j];
if(N[j + 1] == N[ln]) j = j + 1;
next[ln] = j;
}
j = -1;
for(int i = 0; M[i]; i++)
{
while(j >= 0 && N[j + 1] != M[i])
j = next[j];
if(N[j + 1] == M[i]) j = j + 1;
if(j == ln - 1)
{
cout<<"Pattern occurs with shift "<<i - j<<endl;
j = next[j];
}
}
}合体的KMP()函数适合一个“缝衣针”和一个“草堆”的匹配,有些题目要求一个“缝衣针”和多个不同的“草堆”匹配,这个时候分开写createNext()函数和KMP()匹配函数就很有必要了。
拓展KMP算法
参考:http://blog.csdn.net/dyx404514/article/details/41831947 && 《ACM国际大学生程序设计竞赛 - 算法与实现》

2.1 任务
实现一种算法能够在线性时间复杂度内求出一个串对于另一个串的每个后缀的最长公共前缀。
其任务类似与KMP算法,只是此时“缝衣针”字符串由原来的一个串 N 被拆成一组由 N 的前缀组成的包含“N 的长度”个字符串的字符串组——“缝衣针”字符串组。然后问“草堆”字符串的任一位置开始能够匹配到的最长的“缝衣针”字符串是哪一个字符串。
2.2 说明
为了和KMP算法区分开,这里我们用p和s表示两个字符串。要求p与每个s的后缀的最长公共前缀。和KMP一样,首先需要预处理p串 —— 求出p和它自身的每个后缀的最长公共前缀(假设为A)。类似KMP算法的思想,需要利用好已知信息。
假如已经得到了A[1…i-1]的值,现在要计算 p 的第i个字符开头的后缀的A[i]值。我们可以找到这样一个 k(0 <= k < i),使得 k+A[k]-1 最大,即匹配到的范围最大。
- 于是我们有 p[k…k+A[k]-1] = p[0…A[k]-1] ;
- 进一步可推得 p[i…k+A[k]-1] = p[i-k…A[k]-1] ;
- 接下来要分两种情况讨论:
- 如果 i+A[i-k]-1 < k+A[k]-1, 则A[i]的值等于A[i-k];
- 如果 i+A[i-k]-1 >= k+A[k]-1, 则从 p[k+A[k]] 和 p[k+A[k]-i] 开始继续匹配直到 k+A[k]+j >= strlen(p) 或者 p[k+A[k]+j] != p[k+A[k]-i+j] 为止,得到 A[i] = k+A[k]-i+j。(j 为此次匹配循环的次数)
通过以上3个步骤就能计算出p串对应的预处理A数组。
得到A[]数组后,计算p和s的后缀的最长公共前缀也是类似的方法。假如我们已经得到了对应s字符串的extend[0…i-1]的值,现在要计算extend[i]的值。同样我们可以找到一个 k(0 <= k < i)使得 k+A[k]-1最大,即在s串上能匹配到的最远的位置。
- 于是我们有 s[k…k+extend[k]-1] = p[0…extend[k]-1] ;
- 同样可以进一步推得 s[i…k+extend[k]-1] = p[i-k…extend[k]-1] ;
- 接下来仍然分两种情况讨论:
- 如果 i+A[i-k]-1 < k+extend[k]-1, 则 extend[i] = A[i-k] ;
- 如果 i+A[i-k]-1 >= k+extend[k]-1, 则从 s[k+extend[k]] 和 p[k+extend[k]-i] 开始继续匹配,直到 k+extend[k]+j > strlen(s) 或者 s[k+extend[k]+j] != p[k+extend[k]-i+j] 为止, 得到 extend[i] = k+extend[k]-i+j。(j为此次匹配循环的次数)
通过上述两个过程,就能得到p与每个s的后缀的最长公共前缀的长度extend[]数组。
2.3代码
首先预处理p串得到A[]数组:
void getA(const char p[], int A[])
{
int j = 1, lp = strlen(p);
while(p[j] == p[j-1]) j++;
A[0] = lp, A[1] = j - 1;
int k = 1;
for(int i = 2; i < lp; i++)
{
if(i + A[i - k] < k + A[k]) A[i] = A[i - k];
else
{
j = max(k + A[k] - i, 0);
while(p[j] == p[j + i]) j++;
A[i] = j;
k = i;
}
}
}得到 A[] 数组即可运用于拓展KMP算法:
void extendKMP(const char s[], const char p[], int A[], int extend[])
{
int j = 0;
while(s[j] == p[j]) j++;
extend[0] = j;
int k = 0;
for(int i = 1; s[i]; i++)
{
if(i + A[i-k] < k + extend[k]) extend[i] = A[i - k];
else
{
j = max(0, k + extend[k] - i);
while(s[j + i] == p[j]) j++;
extend[i] = j;
k = i;
}
}
}以上即为拓展KMP算法总结的全部,参考例题为HDU4300http://acm.hdu.edu.cn/showproblem.php?pid=4300
串的最小表示
参考 《ACM国际大学生程序设计竞赛 - 算法与实现》
3.1任务
串的最小表示即要求一个字符串 s 经过重组以后能获得的字典序最小的字符串,重组的过程是不断地将字符串 s 最左边的字符拿到最右边。
或者换一种说法,即给定一个环形字符串 s,将 s 从任一处断开得到的字符串字典序最小的那个字符串就是 s 串的最小表示。
3.2说明
首先将字符串复制一遍接在原串上,将环转化为链。
用两个指针 i 和 j 维护最优起始位置和待比较起始位置。
令 k = {最小的 x | s[i+x] != s[j+x] },如果 k >= strlen(s),那么 i 已经是最优起始位置了。否则,当 s[j+k] > s[i+k] 时,将 j向后移动 k+1;若 s[j+k] < s[i+k],令 j = max(j, i+k) 并更新最优位置使 i = j。
重复上面的过程,直到j >= strlen(s)为止。
3.3代码
s 串为需要处理的环形字符串, re 串为s串的最小表示。 re[]应至少有s[]两倍大的空间。
void smallLestRepresation(const char s[], char re[])
{
int i, j, k, n = strlen(s);
strcpy(re, s);
strcat(re, s);
for(i = 0, j = 1; j < n;)
{
for(k = 0; k < n && re[i + k] == re[j + k]; k++);
if(k >= n) break;
if(re[i + k] < re[j + k])
j += k + 1;
else
{
int l = i + k;
i = j;
j = max(l, j) + 1;
}
}
strcpy(re, s + i);
strncat(re, s, i);
re[n] = '\0';
}不过如果用C++字符串类string,smallLestRepsation()函数会是这个样子的代码段:
string smallLestRepresation(string s)
{
int i, j, k;
int n = s.length();
s += s;
for(i = 0, j = 1; j < n;)
{
for(k = 0; k < n && s[i + k] == s[j + k]; k++);
if(k >= n) break;
if(s[i + k] < s[j + k])
j += k + 1;
else
{
int l = i + k;
i = j;
j = max(l, j) + 1;
}
}
return s.substr(i, n);
}以上即为串的最小表示的部分。例题为“[NWPU2016]暑假集训第二次组队赛 J:薇薇的命令”。
trie树(字典树)
参考:《算法问题实战策略》 && 《ACM国际大学生程序设计竞赛 - 算法与实现》 && supermaker(缪宇驰)《计算科学中的字符处理 - 基础篇》
4.1 任务
trie树是一种表示字符串集合的树形数据结构。
支持两种操作:插入一个字符串;查询一个字符串是否存在。其中,查询一个字符串是否存在能够在O(m)的时间内完成,m表示要查询的字符串长度。
4.2 说明
trie树是字符串集合中各元素的前缀对应节点相互连接而成的树结构。在一个前缀末端添加字符而得到另一前缀时,这两个节点将以父子关系相互连接,连接两个节点的边对应于增加的字符。trie树的根节点总是对应于长度为0的字符。随着节点深度的增加,每次增加深度,对应的字符串也会增加1个字符。
Trie树的核心思想是:空间换时间。利用字符串的公共前缀来最大限度地减少无谓的字符串比较,进而降低时间复杂度
trie树的重要属性是,从根节点移动到某个子节点的过程中,将遇到的所有字符累加起来就能得到该节点的前缀。
trie树的基本性质包括:
- 根节点不包含字符,除根节点之外的每条边对应一个字符
- 从根节点到某一个节点,将边上的字符连起来,会得到该节点对应的前缀
- 每个节点对应的前缀都不相同
4.3代码
trie树的动态实现会很耗时间,所以这里只介绍其静态实现方法。为了更具体,这里设定一个情景:
- 插入的字符串只包含大写字母;
- 插入的字符串的长度不超过10,最多有10 000个字符串。
第一个条件确定指针目录的大小,第二个条件确定了节点个数最多 100 000个。
const maxl(26); //指针目录大小,这里表示大写字母的数量
const maxn(100005); //trie树中的节点个数
struct node{
node *child[maxl];
bool terminal; //表示这个节点是否是终止节点
}trie[maxn];
node *root;
int num; //num表示已经使用的节点个数
void init() //初始化trie树为空,只有一个节点:根节点
{
memset(trie, 0, sizeof(trie));
root = trie;
num = 1;
}
void insert(const char *s) //向trie树中插入一个字符串 s
{
node *p = root;
for(int i = 0; s[i]; i++)
{
int loc = s[i] - 'A';
if(p->child[loc] == NULL)
p->child[loc] = trie + num++;
p = p->child[loc];
}
p->terminal = true;
}
bool find(const char *s) //查找一个字符串 s 是否在trie树中
{
node *p = root;
for(int i = 0; s[i]; i++)
{
node *q = p->child[s[i] - 'A'];
if(q == NULL)
return false;
p = q;
}
return p->terminal;
}将代码中的terminal成员变量从bool类型变成其他类型,就能将字典树用作字典数据结构。例如,将terminal变换成整数,就会变成字符串与整数相互对应的字典数据结构,也就能替代map
//CHARSET 为字符集大小
//BASE 为字符集ASCII最小字符
//MAX_NODE 为最大点数
const int CHARSET(26), BASE('A'), MAX_NODE(100005);
struct Trie
{
int tot, root, child[MAX_NODE][CHARSET];
bool flag[MAX_NODE];
Trie()
{
memset(child[0], 0, sizeof(child[0]));
flag[1] = false;
root = tot = 1;
}
void insert(const char *s)
{
int *cur = &root;
for(const char *p = s; *p; p++)
{
cur = &child[*cur][*p - BASE];
if(*cur == 0)
{
*cur = ++tot;
memset(child[tot], 0, sizeof(child[tot]));
flag[tot] = false;
}
}
flag[*cur] = true;
}
bool query(const char *s)
{
int *cur = &root;
for(const char *p = s; *p && *cur; p++)
cur = &child[*cur][*p - BASE];
return (*cur && flag[*cur]);
}
};以上为标准的trie树建立过程,还有一种trie树的建立则是以链为基础构建的,即把节点的孩子节点放入一个链中,把此链的头结点存入该节点,通过遍历链的方法找到对应的孩子节点。
在trie树中,孩子指针的个数总是和字符集大小相同,但孩子节点的个数往往忽大忽小,并不总是会用到所有的child指针。
这种方法以“时间换空间”的方式摆脱了字符集大小的限制,却是以增加查询时间为代价。这种构建树的方法就是俗称的 “我把你当兄弟你却把我当爸爸”。
虽然这种方法违背了trie树建立的初心,但仍然作为一种建树的经验而存在。
AC自动机
参考:supermaker(缪宇驰)《计算科学中的字符处理 - 基础篇》 && 《算法问题实战策略》 && 《ACM国际大学生程序设计竞赛 - 算法与实现》
5.1任务
AC自动机(Aho-Corasick Automation)是一种经典的多模式匹配算法,基于Trie树和KMP算法构建的,是一种DFA(确定性有限状态自动机)的实现。实际上AC自动机就是KMP算法的多模式串扩展。
AC自动机主要用于在较长文档中同时找出多个字符串是使用的搜索引擎。在一个“草堆”和多个“缝衣针”的检索问题中,可以一次性地从“草堆”中找出所有“缝衣针”字符串。
给定 n 个模式串P1, P2, …, Pn,由这些模式串构成yik棵trie树,树的每一个节点就是一个状态。初始状态就是根节点。对于给定的状态 S 以及字符 ch, 完成状态转移函数 f(S, ch),它等于 满足 str(S) + ch 的后缀的一个最深的节点 v。其中 str(S) 代表状态 S 表示的字符串。
5.2说明
仿照KMP算法中的next数组,这里对于树中的每个节点建立一个前缀指针。这里节点A的前缀指针所指向的节点满足:指向节点A表示的前缀中出现最长后缀的节点。
构建方法:根据树的深度一一求出每个节点的前缀指针,对于当前节点B,设它的父节点A和它的边上的字符为ch,如果它的父节点的前缀指针所指向的节点C中有通过ch连接的孩子节点D,则当前节点的前缀指针指向该孩子节点D;否则通过当前节点的父节点的前缀指针所指向的节点的前缀指针继续向上查找,直到到达root为止。
边界条件:与root相连的节点的前缀指针指向root
实现的方式:树的层次遍历(BFS)
多模式匹配的步骤: 从root出发,按照当前串的下一个字符ch来进行在树上的移动。若当前A节点不存在通过ch连接的孩子节点,则考虑A的前缀指针所指向的节点B,若节点B也无法找到通过ch连接的孩子节点,则再考虑B的前缀指针…,直到找的通过ch连接的孩子节点,接着向下遍历;或者是沿着前缀指针走到root,将文本串指针向后移动一位(因为此时不存在可能匹配的情况)。如果遍历过程中经过了某个终止节点,则说明文本串包含该终止节点所代表的前缀
5.3代码
代码以HDU2222的题目要求完成,但不失一般性,如下:
//CHARSET 为字符集大小
//BASE 为字符集ASCII最小字符
//maxl 是每个串的最大长度, maxn表示字典里有多少个串
const int CHARSET(26), BASE('a'), maxl(52), maxn(10005);
const int MAX_NODE(maxn * maxl);
struct node{
node *child[CHARSET];
node *pre; //前缀指针
int terminal; //以当前节点结尾的字符串在字典中的个数
}tree[MAX_NODE];
node *root;
int nodeNum;
void init() //初始化字典
{
memset(tree, 0, sizeof(tree));
root = tree;
root->pre = root;
nodeNum = 1;
}
void insert(const char *s) //向trie树里插入一个字符串 s
{
if(!s[0]) return ;
node *p = root;
for(const char *cp = s; *cp; cp++)
{
node *&loc = p->child[*cp - BASE];
if(loc == NULL)
loc = tree + nodeNum++;
p = loc;
}
p->terminal++;
}
node *qu[MAX_NODE];
int head, tail;
void buildPre() //构造trie树的前缀指针
{
for(int i = 0; i < CHARSET; i++)
if(root->child[i])
{
qu[head++] = root->child[i];
root->child[i]->pre = root;
}
while(tail < head)
{
node *fa = qu[tail++];
node **ch =fa->child;
for(int i = 0; i < CHARSET; i++)
{
if(!ch[i]) continue;
node *p = fa->pre;
while(p != root && !p->child[i])
p = p->pre;
ch[i]->pre = p->child[i] ? p->child[i] : root;
qu[head++] = ch[i];
}
}
}
int query(const char *s) //传入一个字符串 s,返回包含在字典里的字符串的个数
{
node *p = root;
int cnt = 0;
for(const char *cp = s; *cp; cp++)
{
int loc = *cp - BASE;
while(p != root && !p->child[loc])
p = p->pre;
if(!p->child[loc]) continue;
p = p->child[loc];
node *q = p;
while(q != root && q->terminal >= 0)
{
if(q->terminal)
{
cnt += q->terminal;
q->terminal = -1;
}
q = q->pre;
}
}
return cnt;
}后缀数组(suffix array)
参考:罗穗骞《后缀数组——处理字符串的有力工具》 && 具宗万《算法问题实战策略》 && 《ACM国际大学生程序设计竞赛 - 算法与实现》
6.1 任务
后缀数组又称“字符串中的瑞士军刀”。常用于诸多字符串问题的求解。
它的任务是给定一个字符串 S,长度为 n, 设 S(i)表示 S长度为 i 的后缀,给所有 S(i) 排序。严格地说, 求一个0到n-1的排列 P, 使得 S(P[0]) < S(P[1]) < S(p[2]) < … < S(P[n-1])。 P就是 S 的后缀数组。
6.2 说明
后缀数组的生成算法主要有倍增算法和DC3算法,时间复杂度分别为O(nlogn) 和 O(n),但是DC3的时间常数较倍增算法要大,而且DC3算法的源程序实现起来比倍增算法更复杂。这里只介绍倍增算法求suffix array。了解DC3算法以及后缀数组的其他拓展可参考2009年国家集训队论文——罗穗骞《后缀数组——处理字符串的有力工具》。
倍增算法主要用于求取对每个字符开始的长度为 2k 的子字符串排序的排名,这里用带下标2k的Rank2k[] 数组表示。
这里我们首先令t = 2k,并且已经求出了即 Rankt[i], 即S[i…i+t]的排名(0 <= i < n)。有了这个Rankt[]数组就能在常数时间里判断出以2t为长度的子字符串的排名,即Rank2t[]值。怎么做呢? 给出S[i…i+2t]和S[j…j+2t],首先比较前t个字符,如果这几个字符不相同,那么Rankt[i] != Rankt[j],则Rank2t[i]和Rank2t[j]的大小关系与Rankt[i]和Rankt[j]的大小关系相同;如果前t个字符相同, 即Rankt[i] == Rankt[j],那么就只需要比较S[i+t…i+2t]和S[j+t…j+2t]的大小关系即可确定Rank2t[i]和Rank2t[j]的大小关系。
可以很明显地发现,这里Rankt[i]和Rankt[i+t]就像是pair类型排序的第一关键字和第二关键字一样。代码部分会对这里进行利用和说明.
在对后缀目录进行排序时,第一次为后缀的第一个字符为标准,即 t = 1;第二次为前两个字符为标准,即 t = 2;第三次为前4个字符为标准,即 t = 4。按照这样的方式进行lgn次排序,就能得到最终排序好的Rankn[]数组,通过Rankn[]数组就能反推后缀数组SA,即SA[Rankn[i]] = i。
这里,排序的方法如果用sort()复杂度会增加至O(nlg2n)。由于所有的Rank值都不大于n,这里采用基数排序的方法才能将复杂度降至O(nlgn)。
6.3 代码
为了便于理解倍增算法,下面的代码不使用基数排序而改用C++标准函数库中的sort()函数简化整个求取后缀数组的算法:
typedef pair<int, int> Pii;
typedef pair<Pii, int> Ppi;
//需要求取suffix array的s字符数组和suffix array的存放位置SA[]
void getSuffixArray(const char *s, int SA[])
{
//n为字符串长度,Rank[]数组存储上文提到的rank值
int n = strlen(s), Rank[maxn];
memset(Rank, 0, sizeof(Rank));
//findRank[]数组用于排序,first用于存储第一和第二关键字,second存储当前关键字的排名
Ppi findRank[maxn];
//t = 1时只需要大小关系所以初始化时只要直接存入每个后缀第一个字符即可
int t = 1;
for(int i = 0; i < n; i++)
Rank[i] = s[i];
while(t < n)
{
for(int i = 0; i < n; i++)
findRank[i] = make_pair(make_pair(Rank[i], Rank[i + t]), i);
sort(findRank, n, 0);
sort(findRank, n, 1);
//排名最小值设定为 1而不是 0,是为了防止i + t >= n的情况下排名出现错误
int j = 1;
Rank[findRank[0].second] = j;
for(int i = 1; i < n; i++)
Rank[findRank[i].second] =
findRank[i].first == findRank[i - 1].first ? j : ++j;
if(j >= n) break;
t <<= 1;
}
//因为排名是从 1 开始的,这里要减一才能得到正确的位置
for(int i = 0; i < n; i++)
SA[Rank[i] - 1] = i;
}
下面我们再来覆写sort()函数,将其改用基数排序的方法降低复杂度:
//s 表示基数排序的pair类型数组,对应getSuffixArray()函数中的findRank[]数组,n表示
//s数组的大小,keyF表示是否按照第一关键字排序
void sort(Ppi *s, int n, int keyF)
{
struct node1{Ppi data;node1 *next;} a[maxn];
struct node2{node1 * pre, *next;} head[maxn];
memset(head, 0, sizeof(head));
for(int i = 0; i < n; i++)
{
Pii &temp = s[i].first;
node1 *it = a + i;
it->data = s[i], it->next = NULL;
//keyF为真,则按第一关键字排序;keyF为假,则按第二关键字排序
node2 *p = head + (keyF ? temp.first : temp.second);
if(!p->next)
(p++)->next = it;
else
(++p)->pre->next = it;
p->pre = it;
}
int num = 0;
for(node2 *p = head; num < n; p++) //找到n个值就退出
{
if(!p->next) continue;
node1 *t = p->next;
while(t)
{
s[num++] = t->data;
t = t->next;
}
}
}下面来解释一下这个基数排序:
结构体node1 和 node2。这两个结构体是为了基数排序当中建立一个“链接彩虹”的需要。如下:
黑色节点表示node2类型的head[]数组,表示彩虹的所在地,蓝色节点表示node1类型的a[]数组中的点,将原来的Ppi类型的数组s[]中的内容取出以后,存至a[]数组的data中,找到对应的彩虹所在地,再链接起来。将所有的数据存储完毕以后,遍历head[]数组,如果某个节点head[i].next != NULL ,则说明有彩虹存在,遍历彩虹,顺序取出node1节点中的data数据就完成了排序。- bool类型参数keyF。 表示是否按照第一关键字排序。keyF如果是真,则按照第一关键字寻找彩虹所在地,最后排序也会按照第一关键字排序;如果keyF为假,则按照第二关键字排序,最后排好序的s数组也是按照第二关键字排序的。
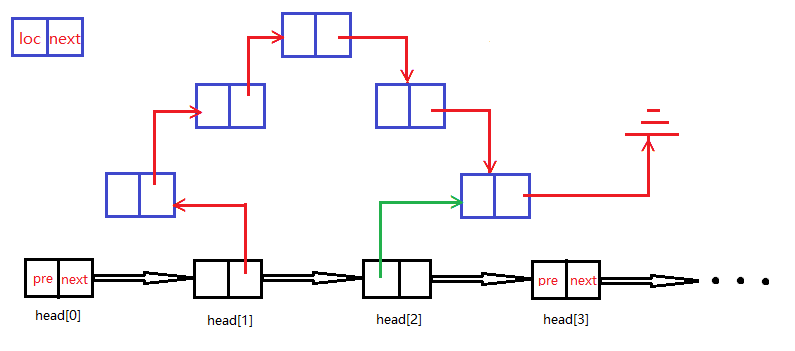
PS:需要说明的是,这个基数排序实际上只是一个关键字的桶排序。要完整地排好getSuffixArray()函数中的findRank[]数组,就需要在getSuffixArray()函数中调用两次该sort()函数。分别是
sort(findRank, n, 0);
sort(findRank, n, 1);
根据基数排序的定义,应当从最低有效关键字进行排序。所以两个语句的顺序不能随意调换,先调用keyF = 0的语句排序第二关键字,再调用keyF = 1的语句排序第一关键字。
当然,这篇文档仅限于理解后缀数组的倍增算法,正式比赛当中当然还是25行的倍增算法模板或者40行的DC3算法模板更快更有效,两篇标准代码在罗穗骞《后缀数组——处理字符串的有力工具》中都有详细的介绍与模板。这里就不再赘述。
6.4应用
后缀数组的一个重要应用就是快速地求出两个后缀的最长公共前缀(LCP Longest Common Prefix)。其做法如下:
首先定义rank[]数组 —— rank[i]表示后缀S[i……]在所有后缀当中的字典序排名。它和后缀数组SA[]满足这样的关系:SA[rank[i]] = i ; rank[SA[i]] = i 。显然这里的rank[]数组就是前面提到的Rankn[]数组。
其次我们定义height[]数组 —— height[i]表示按照字典序排序以后第i大的后缀和第i-1大的后缀的最长公共前缀长度。即S[SA[i]……]和S[SA[i-1]……]的最长公共前缀长度。 那么S[i……]和S[j……]的最长公共前缀值就是height[i]和height[j]闭区间内的最小值。
于是,对于第i大的后缀S[SA[i]……]和第i-1大的后缀S[SA[i-1]……]它们的前height[i]个字符相同。如果去掉第一个相同的字符,也就是公共前缀的首字符,那么剩下的height[i]-1个字符仍然构成一个公共前缀。而这个公共前缀属于S[SA[i]+1……]和S[SA[i-1]+1……]。也就是说S[SA[i]+1]与其他后缀的最长公共前缀至少是height[i]-1, 即height[rank[SA[i]+1]] >= height[i] - 1 。
令rank[SA[i]+1] = j, 则有height[j] >= height[rank[SA[j] - 1]] - 1.
要计算第height[j],只需要从S[SA[j]……]和S[SA[j-1]……]的第height[rank[SA[j]-1]]个字符开始比较即可。
以上即为求height[]数组的主要思想。在实现算法时,为了最大化使用已经扫过的字符,应当按照字符串从左到右的顺序扫描,将每次求取height[i]改为每次求取height[rank[k]], 其中k == SA[j],则原式又变成:height[rank[k]] >= height[rank[k-1]] - 1。 代码如下:
//s 为字符数组,SA[]为字符串 s 的后缀数组,
//要计算的height值放入height[]数组,n表示字符串长度即 n == strlen(s)
void get_height(const char *s, int SA[], int height[], int n)
{
memset(height, 0, sizeof(height));
int rank[maxn];
for(int i = 0; i < n; i++)
rank[SA[i]] = i;
for(int k = 0; k < n; k++)
{
//height[0]无定义
if(!rank[k]) continue;
int h = height[rank[k - 1]] - 1;
while(s[rank[k] + h] == s[SA[rank[k] - 1] + h]) h++;
height[rank[k]] = h;
}
}为了说明后缀数组SA[],排名数组rank[], 和相邻最长重复前缀长度数组height[]的关系,这里以字符串“mississipi”作一个例子:
| 后缀 | SA[] | rank[] | height[] |
|---|---|---|---|
| i | 9 | 0 | 0 |
| ipi | 7 | 1 | 1 |
| issipi | 4 | 2 | 1 |
| ississipi | 1 | 3 | 4 |
| mississipi | 0 | 4 | 0 |
| pi | 8 | 5 | 0 |
| sipi | 6 | 6 | 0 |
| sissipi | 3 | 7 | 2 |
| ssipi | 5 | 8 | 1 |
| ssissipi | 2 | 9 | 3 |
关于后缀数组的例题是POJ3261,给定一个字符串,求至少出现 k 次的最长重复子串,这 k 个子串可以重叠。
最长重复字串
参考: 《ACM国际大学生程序设计竞赛 - 算法与实现》
7.1 任务
给定一个字符串S,计算:
- 最长的S的字串,满足它在S中至少出现了两次;
- 最长的S的字串,满足它在S中出现至少两次,且不会相重叠。
7.2 说明
对于第一种,利用上一节的后缀数组就能很容易求出来。依据height[]数组的定义,只要比较出最大的height值即可。
对于第二种,利用二分法。二分最长重复字串的长度,找到符合mid值的两个子字符串,判断是否重叠即可。
7.3 代码
首先要求出后缀数组SA[]和排名表rank[]数组,利用上一节的get_height()函数求出height[]数组,利用“说明”中提到的方法计算即可。
首先是第一种:
//s 为待求字符串, 返回两个值
//char*指最长重复子串的起始位置, int是最长重复字串的长度
pair<char*, int> duplicate_substr1(char *s)
{
int SA[maxn], height[maxn];
int n = strlen(s);
getSuffixArray(s, SA);
get_height(s, SA, height, n);
int ans = 0;
char *ss = NULL;
for(int i = 1; i < n; i++)
{
if(ans < height[i]) ans = height[i], ss = s + SA[i];
}
return make_pair(ss, ans);
}然后是第二种:
//s 为待求字符串, 返回两个值
//char*指最长重复子串的起始位置, int是最长重复字串的长度
pair<char *, int> duplicate_substr2(char *s)
{
int n = strlen(s), SA[maxn], height[maxn];
getSuffixArray(s, SA);
get_height(s, SA, height, n);
int lo = 1, hi = n, ans = -1;
char *subS = NULL;
while(lo <= hi)
{
int mid = (lo + hi) >> 1, i = 0;
while(++i < n)
{
int low_pos = SA[i - 1], up_pos = SA[i - 1];
for( ; i < n && height[i] >= mid; i++)
{
low_pos = min(low_pos, SA[i]);
up_pos = max(up_pos, SA[i]);
}
if(up_pos - low_pos >= mid)
{
subS = s + low_pos;
ans = mid;
break;
}
}
if(ans == mid) lo = mid + 1;
else hi = mid - 1;
}
return make_pair(subS, ans);
}如果深刻了解了后缀数组的含义,这两份代码是不难理解的。另外,如果明白了扫一遍就能知道最长重复子串,二分得到不叠加的最长重复子串的,自己写出一份这样的代码是完全没有问题的。
最长公共字串
参考 : 《ACM国际大学生程序设计竞赛 - 算法与实现》
8.1任务
给定两个字符串S1和S2,求它们的最长公共字串。
8.2说明
这个问题有两种解法。
动态规划。dp[i][j]表示S1的前i个字符和S2的前j个字符的最长公共后缀的长度。则应该有状态转移方程:
dp[i][j] = S1[i-1] == S2[j-1] ? dp[i - 1][j - 1] + 1 : 0;。维护dp数组的同时维护ans值表示最长公共子串的长度,最后得出ans就是答案了。复杂度是O(m * n)的。后缀数组。将S1和S2连接成一个字符串。中间用一个小于在S1和S2中出现的字符隔开(为什么请自己思考),求出新串的的后缀数组。如果两个相邻后缀分别属于S1和S2,那么它们的最长公共前缀就是一个公共子串。在所有公共字串中取最大值即可。
8.3代码
动态规划的代码比较简单,初始化将dp[i][0]和dp[0][j]都设为,按照说明中的转移方程计算即可。这里的代码主要针对后缀数组,还是一样,只要理解了后缀数组的含义,这一份代码自己写出来也是完全没有问题的,这里只做参考:
//S1, S2分别是待求字符串,返回最长重复字串在S1中的起始位置及长度
pair<char*, int> commonStr(char *S1, char *S2)
{
//将S1和S2连接在s字符数组中并用‘#’分开
const int dmaxn = maxn* 2;
char s[dmaxn];
strcpy(s, S1); strcat(s, "#"); strcat(s, S2);
int n = strlen(s), n1 = strlen(S1);
int SA[dmaxn], height[dmaxn];
getSuffixArray(s, SA);
get_height(s, SA, height, n);
int ans = 0;
char *res = NULL;
//s[SA[0]……]一定是“#”+S2,不必处理,height[1]一定是0,因为不可能和‘#’匹配
//故直接从i = 2开始
for(int i = 2; i < n; i++)
if((SA[i] < n1) != (SA[i - 1] < n1) && height[i] > ans)
ans = height[i], res = S1 + min(SA[i], SA[i - 1]);
return make_pair(res, ans);
}最长回文子串
参考: 《ACM国际大学生程序设计竞赛 - 算法与实现》
9.1任务
给定一个字符串S,求出S的最长回文子串。
9.2说明
这里介绍一种名叫manacher的求最长回文串的算法。求解最长回文串的过程类似于拓展KMP中extend数组的求法。
假设对字符数组s[]求取最长回文串。取数组len[],len[i]表示以字符s[i]为中心的最长回文串的长度。现在要计算len[i],且len[0]到len[i-1]都已经计算出来了。令 r = max{j + len[j]/2 | 0 <= j <= i - 1} 。类似于拓展KMP,这里也要分两种情况:
- i >= r 时,要依次匹配s[i]左右的字符进行判断;
- i + len[j - (i - j)] / 2 < r. 则由于对称性,len[i] = len[j - (i - j)] ;
- i + len[j - (i - j)] / 2 >= r. 这时,如果 i 本身就大于等于 r ,则以 i 为中心,向两边拓展计算len[i];如果 i 小于 r, 则根据对称性,len[i] / 2 (即以s[i]为中心的回文串半径)一定 大于等于 (r - i),接下来只需要判断s[r + j] 和 s[i - (r - i) + j](j = 1,2,3,……)是否匹配即可。
其实回文串有奇偶两种情况,而上面所述的方法只处理了奇回文串这一种情况。对于偶回文串,只要在最中间加上一个不出现在字符串中的字符,就将偶回文串变成了奇回文串。在manacher算法中,可以假想每两个字符之间都有一个相同的 不出现在原字符串中的字符,然后按照上面的方法只处理奇回文串的情况就可以了。
9.3 代码
//s为待求字符串,返回最长回文字串的起始位置和长度
pair<char *, int> mannacher(char *s)
{
//ns[]为填充了'#'的新字符串
char ns[maxn << 1];
//lne[i]表示以第i个字符为中心,回文串的半径长度
int n = strlen(s), len[maxn << 1];
pair<char *, int> ans = make_pair(s + n, -1);
n = (n << 1) + 1;
for(int i = 0; i <= n; i++)
ns[i] = (i & 1) ? s[i >> 1] : '#';
int j = 0;
for(int i = 1; i < n; i++)
{
int r = j + len[j];
//第一种情况, 依次匹配
if(i >= r)
{
int &li = len[i] = 1;
while(i - li >= 0 && i + li < n && ns[i - li] == ns[i + li])
li++;
li--, j = i;
}
//第二种情况, 直接赋值
else if(i + len[j - (i - j)] < r)
len[i] = len[j - (i - j)];
//第三种情况,赋值一部分, 匹配超出的一部分
else
{
int &li = len[i] = r - i + 1;
while(i - li >= 0 && i + li < n && ns[i - li] == ns[i + li])
li++;
li--, j = i;
}
if(len[i] > ans.second)
ans = make_pair(s + ((i - len[i]) >> 1), len[i]);
}
return ans;
}在《ACM国际大学生程序设计竞赛 - 算法与实现》中有更简便的,不用加’#’的方法,但思想是类似的,如下:
//len[p + q]表示以 p 和 q 为中心的回文子串长度(p 可以等于 q)
void mannacher(char *s, int len[], int n)
{
len[0] = 1;
for(int i =1, j = 0; i < (n << 1) - 1; i++)
{
int p = i >> 1, q = i - p, r = ((j + 1) >> 1) + len[j] - 1;
//初始判断len[i] 已经匹配了多少个字符
len[i] = r < q ? 0 : min(r - q + 1, len[(j << 1) - i]);
//开始匹配
while(p > len[i] - 1 && q + len[i] < n && s[p - len[i]] == s[q + len[i]])
len[i]++;
if(q + len[i] - 1 > r) j = i;
}
}以上即为求取回文子串的manacher算法,例题为hdu3068和hdu3294.
The End ~
by 林维 8/5/2016 1:58:55 PM