Basic classification[edit]
The various algorithms can be classified by the number of patterns each uses.
Single pattern algorithms[edit]
Let m be the length of the pattern and let n be the length of the searchable text.
| 0 (no preprocessing) | Θ((n−m) m) |
| Θ(m) | average Θ(n+m), worst Θ((n−m) m) |
| Θ(m |Σ|) | Θ(n) |
| Θ(m) | Θ(n) |
| Θ(m + |Σ|) | Ω(n/m), O(nm) |
| Θ(m + |Σ|) | O(mn) |
1Asymptotic times are expressed using O, Ω, and Θ notation
The Boyer–Moore string search algorithm has been the standard benchmark for the practical string search literature.[1]
Algorithms using a finite set of patterns[edit]
Algorithms using an infinite number of patterns[edit]
Naturally, the patterns can not be enumerated in this case. They are represented usually by a regular grammar or regular expression.
Other classification[edit]
|
|
This section does not cite any references or sources. (July 2013) |
Other classification approaches are possible. One of the most common uses preprocessing as main criteria.
[2]| Elementary algorithms | Index methods |
| Constructed search engines | Signature methods |
Naïve string search[edit]
A simple but inefficient way to see where one string occurs inside another is to check each place it could be, one by one, to see if it's there. So first we see if there's a copy of the needle in the first character of the haystack; if not, we look to see if there's a copy of the needle starting at the second character of the haystack; if not, we look starting at the third character, and so forth. In the normal case, we only have to look at one or two characters for each wrong position to see that it is a wrong position, so in the average case, this takes O(n + m) steps, where n is the length of the haystack and m is the length of the needle; but in the worst case, searching for a string like "aaaab" in a string like "aaaaaaaaab", it takes O(nm)
Finite state automaton based search[edit]

In this approach, we avoid backtracking by constructing a deterministic finite automaton (DFA) that recognizes stored search string. These are expensive to construct—they are usually created using the powerset construction—but are very quick to use. For example, the DFA shown to the right recognizes the word "MOMMY". This approach is frequently generalized in practice to search for arbitrary regular expressions.
Stubs[edit]
Knuth–Morris–Pratt computes a DFA that recognizes inputs with the string to search for as a suffix, Boyer–Moore starts searching from the end of the needle, so it can usually jump ahead a whole needle-length at each step. Baeza–Yates keeps track of whether the previous j characters were a prefix of the search string, and is therefore adaptable to fuzzy string searching. The bitap algorithm is an application of Baeza–Yates' approach.
Index methods[edit]
Faster search algorithms are based on preprocessing of the text. After building a substring index, for example a suffix tree orsuffix array, the occurrences of a pattern can be found quickly. As an example, a suffix tree can be built in 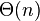 time, and all
time, and all 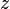 occurrences of a pattern can be found in
occurrences of a pattern can be found in  time under the assumption that the alphabet has a constant size and all inner nodes in the suffix tree know what leaves are underneath them. The latter can be accomplished by running a DFS algorithm from the root of the suffix tree.
time under the assumption that the alphabet has a constant size and all inner nodes in the suffix tree know what leaves are underneath them. The latter can be accomplished by running a DFS algorithm from the root of the suffix tree.
Other variants[edit]
Some search methods, for instance trigram search, are intended to find a "closeness" score between the search string and the text rather than a "match/non-match". These are sometimes called "fuzzy" searches.
看了看这篇文章http://en.wikipedia.org/wiki/String_searching_algorithm,里面讲的比较清楚。罗里吧嗦的写了这么多,没有研究清楚String search,反倒是更迷糊了。希望有人能给我讲讲,针对我的实验情况。总归有些收获的,KMP现在印在脑子里了,虽然对其性能没啥信心。最后还要把用到的Stringsearch的下载地址附上,毕竟是别人的结果。
Stringsearch:http://johannburkard.de/software/stringsearch/。
另外关于BMH算法,可以看http://en.wikipedia.org/wiki/Boyer%E2%80%93Moore_string_search_algorithm。
P.S. 有个补充的东西,在rope实现的过程中,如果令cycles变为20000,有兴趣的可以试试结果。难不成我发现了些什么?如果令cycles不是3,而是以2的倍数指数的改变呢?
http://mabusyao.iteye.com/blog/652989
http://www.cnblogs.com/whyandinside/archive/2012/06/03/2532651.html
http://blog.csdn.net/chengyingzhilian/article/details/8197987
http://www.blogjava.net/changedi/archive/2010/09/28/333252.html
https://en.wikipedia.org/wiki/String_searching_algorithm