Seaborn
seaborn同matplotlib一样,也是Python进行数据可视化分析的重要第三方包。但seaborn是在 matplotlib的基础上进行了更高级的API封装,使得作图更加容易,图形更加漂亮。
我并不认为seaborn可以替代matplotlib。虽然seaborn可以满足大部分情况下的数据分析需求,但是针对一些特殊情况,还是需要用到matplotlib的。换句话说,matplotlib更加灵活,可定制化,而seaborn像是更高级的封装,使用方便快捷。
应该把seaborn视为matplotlib的补充,而不是替代物。
Seaborn学习内容
seaborn的学习内容主要包含以下几个部分:
-
风格管理
- 绘图风格设置
- 颜色风格设置
-
绘图方法
- 数据集的分布可视化
- 分类数据可视化
- 线性关系可视化
-
结构网格
- 数据识别网格绘图
风格管理 - 绘图风格设置
def sinplot(flip=1): x = np.linspace(0,14,100) for i in range(1,7): plt.plot(x,np.sin(x+i*0.5) * (7-i) * flip) plt.show() if __name__ == '__main__': sns.set() # 使用seaborn默认的风格 sinplot() # 直接调用sinplot函数是使用的plt绘图 # 先调用sns.set()之后再调用sinplot,则使用的是seaborn的默认风格绘图。
下面第一个是plt的默认绘图,第二个为使用sns的默认风格绘图
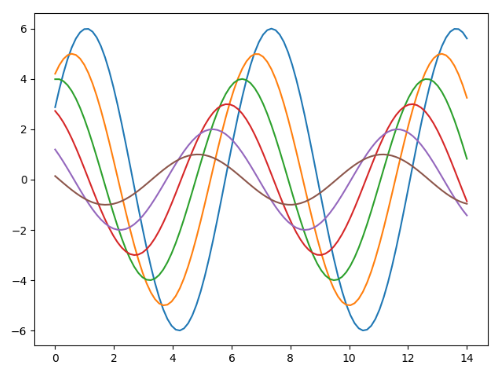

Seaborn 将 matplotlib 的参数划分为两个独立的组合。第一组是设置绘图的外观风格的,第二组主要将绘图的各种元素按比例缩放的,以至可以嵌入到不同的背景环境中。
操控这些参数的接口主要有两对方法:
- 控制风格:
axes_style(),set_style() - 缩放绘图:
plotting_context(),set_context()
每对方法中的第一个方法(axes_style(), plotting_context())会返回一组字典参数,而第二个方法(set_style(), set_context())会设置matplotlib的默认参数。
Seaborn的五种绘图风格
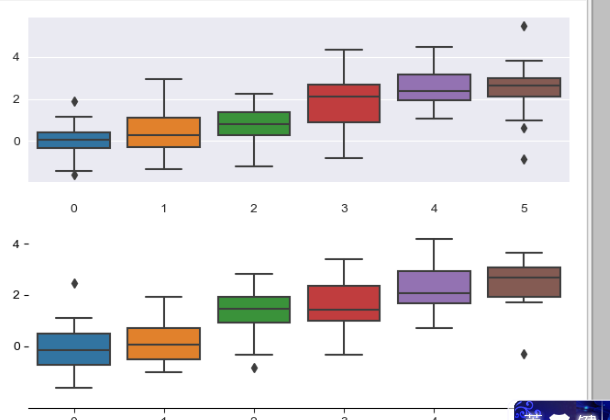
有五种seaborn的风格,它们分别是:darkgrid, whitegrid, dark, white, ticks。它们各自适合不同的应用和个人喜好。默认的主题是darkgrid,分别设置如下:
def sinplot(flip=1):
sns.set_style("whitegrid")
data = np.random.normal(size=(20,6)) + np.arange(6) /2
sns.boxplot(data=data)
plt.show()
sns.set_style("dark")
data = np.random.normal(size=(20, 6)) + np.arange(6) / 2 sns.boxplot(data=data) plt.show() sns.set_style("white") data = np.random.normal(size=(20, 6)) + np.arange(6) / 2 sns.boxplot(data=data) plt.show() sns.set_style("ticks") data = np.random.normal(size=(20, 6)) + np.arange(6) / 2 sns.boxplot(data=data) # 去掉x和y轴的对面轴线 offset=10 图距离坐标轴的距离 # left =True 隐藏掉左边的轴线 sns.despine(offset=10,left=True)
在子图中设置不同的风格(在with语句里面的是一种风格,在with语句外面的是另外一种风格)
white 和 ticks两个风格都能够移除顶部和右侧的不必要的轴脊柱。通过matplotlib参数是做不到这一点的,但是你可以使用seaborn的despine()方法来移除它们
你也可以在一个with语句中使用axes_style()方法来临时的设置绘图参数。这也允许你用不同风格的轴来绘图,可以在子图中分分别设置不同的绘图风格:
def sinplot(flip=1):
sns.set_style("ticks")
data = np.random.normal(size=(20, 6)) + np.arange(6) / 2
sns.boxplot(data=data)
# 去掉x和y轴的对面轴线 offset=10 图距离坐标轴的距离
# left =True 隐藏掉左边的轴线
sns.despine(offset=10,left=True)
if __name__ == '__main__': with sns.axes_style("darkgrid"): plt.subplot(211) sinplot() plt.subplot(212) sinplot(-1) plt.show()
颜色风格设置
在Seaborn的使用中,是可以针对数据类型而选择合适的颜色,并且使用选择的颜色进行可视化,节省了大量的可视化的颜色调整工作。
对于不连续的外观颜色设置而言,最重要的函数恐怕要属color_palette了。这个函数拥有许多方法,让你可以随心所欲的可以生成各种颜色。并且,它可以被任何有palette参数的函数在内部进行使用(palette的中文意思是 "调色板")。
关于这个函数有几个点需要知道一下:
color_palette函数可以接受任何seaborn或者matplotlib颜色表中颜色名称(除了jet),也可以接受任何有效的matplotlib形式的颜色列表(比如RGB元组,hex颜色代码,或者HTML颜色名称)。- 这个函数的返回值总是一个由RGB元组组成的列表,无参数调用
color_palette函数则会返回当前默认的色环的列表。 - 还有一个相应的函数,是
set_palette,它接受与color_palette一样的参数,并会对所有的绘图的默认色环进行设置。当然,你也可以在with语句中使用color_palette来临时的改变默认颜色。

有三种通用的color palette可以使用,它们分别是:qualitative,sequential,diverging
1. 分类色板(quanlitative)
Qualitative调色板,也可以说成是 类型 调色板,因为它对于分类数据的显示很有帮助。当你想要区别 不连续的且内在没有顺序关系的 数据时,这个方式是最好的。
当导入seaborn时,默认的色环就被改变成一组包含6种颜色的调色板,它使用了标准的matplolib色环,为了让绘图变得更好看一些。
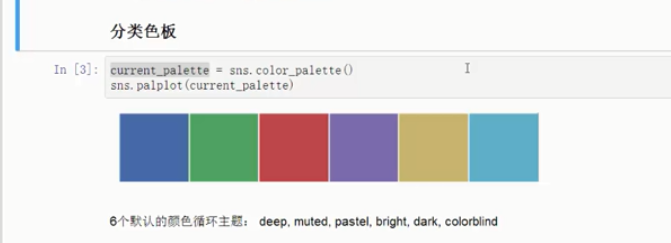
def sinplot(): current_palette = sns.color_palette() sns.palplot(current_palette)
有6种不同的默认主题,它们分别是:deep,muted,pastel,birght,dark,colorblind。
themes = ['deep', 'muted', 'pastel', 'bright', 'dark', 'colorblind'] for theme in themes: current_palette = sns.color_palette(theme) sns.palplot(current_palette)
当你有超过6种类型的数据要区分时,最简单的方法就是 在一个色圈空间内使用均匀分布的颜色。这也是当需要使用更多颜色时大多数seaborn函数的默认方式。
最常用的方法就是使用 hls 色空间,它是一种简单的RGB值的转换。
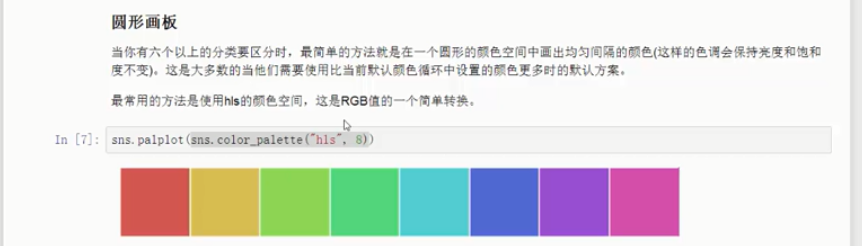
sns.palplot(sns.color_palette("hls",8)) #hls 是一种颜色空间,将划分集中不同的颜色
plt.show() # 会输出8中颜色
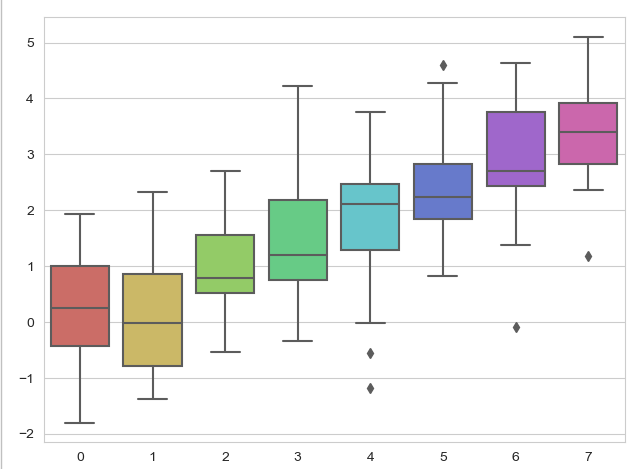
使用hls划分不同的颜色,并给图形上色
def sinplot(flip=1):
sns.set_style("whitegrid")
data = np.random.normal(size=(20,8)) + np.arange(8) /2
# 输出为8个盒图,每一种取一种不同的颜色,颜色使用hls平均截取出来的颜色,根据模块设定颜色个数
sns.boxplot(data=data,palette=sns.color_palette("hls",8))
plt.show()
if __name__ == '__main__':
sinplot()

2. 连续色板(sequential)
调色板的第二大类被成为 "顺序",这种调色板对于有从低(无意义)到高(有意义)范围过度的数据非常适合。尽管有些时候你可能想要在连续色板中使用不连续颜色,但是更通用的情况下是连续色板会作为颜色表在 kdeplot() 或者 corrplot()或是一些 matplotlib 的函数中使用。
对于连续的数据,最好是使用那些在色调上有相对细微变化的调色板,同时在亮度和饱和度上有很大的变化。这种方法将自然地将数据中相对重要的部分成为关注点。
Color Brewer 的字典中就有一组很好的调色板。它们是以在调色板中的主导颜色(或颜色)命名的。
def sinplot(): sns.palplot(sns.color_palette("Blues")) plt.show()

就像在matplotlib中一样,如果您想要翻转渐变,您可以在面板名称中添加一个_r后缀
def sinplot(): sns.palplot(sns.color_palette("Blues_r")) #参数可在函数报错中查看 plt.show()
数据集分布可视化
当处理一个数据集的时候,我们经常会想要先看看特征变量是如何分布的。这会让我们对数据特征有个很好的初始认识,同时也会影响后续数据分析以及特征工程的方法
这里的数据集是随机产生的分布数据,由 numpy 生成,数据类型是ndarray。当然,pandas 的 Series 数据类型也是可以使用的,比如我们经常需要从 DataFrame 表中提取某一特征(某一列)来查看分布情况。
绘制单变量分布
在 seaborn 中,快速观察单变量分布的最方便的方法就是使用 distplot() 函数。默认会使用柱状图(histogram)来绘制,并提供一个适配的核密度估计(KDE)。
def sinplot(flip=1):
x = np.random.normal(size=100)
sns.distplot(x,kde=True ,bins=20) # 可以设置kde为True或者False来启用或者禁用柱状图的曲线
plt.show()
if __name__ == '__main__':
sinplot()

直方图(histograms
直方图是比较常见的,并且在 matplotlib 中已经存在了 hist 函数。直方图在横坐标的数据值范围内均等分的形成一定数量的数据段(bins),并在每个数据段内用矩形条(bars)显示y轴观察数量的方式,完成了对的数据分布的可视化展示。
为了说明这个,我们可以移除 kde plot,然后添加 rug plot(在每个观察点上的垂直小标签)。当然,你也可以使用 rug plot 自带的 rugplot() 函数,但是也同样可以在 distplot 中实现:
def sinplot(flip=1): x = np.random.normal(size=100) sns.distplot(x,kde=False,bins=20,rug=True) plt.show()

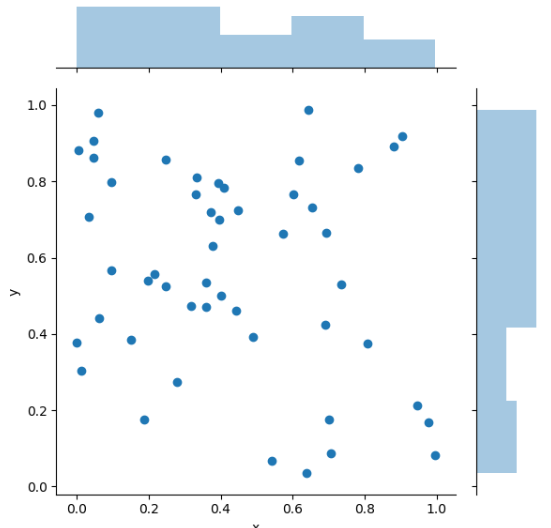
绘制双变量分布
对于双变量分布的可视化也是非常有用的。在 seaborn 中最简单的方法就是使用 joinplot() 函数,它能够创建一个多面板图形来展示两个变量之间的联合关系,以及每个轴上单变量的分布情况。
Scatterplots
双变量分布最熟悉的可视化方法无疑是散点图了,在散点图中每个观察结果以x轴和y轴值所对应的点展示。你可以用 matplotlib 的 plt.scatter 函数来绘制一个散点图,它也是jointplot()函数显示的默认方式。
def sinplot(flip=1):
data = np.random.random(100).reshape(50,2)
df = pd.DataFrame(data,columns=['x','y'])
sns.jointplot(x="x",y="y",data=df) # 画出两个变量之间的关系,并且画出单变量的直方图
plt.show()
if __name__ == '__main__':
sinplot()
Hexbin plots
直方图 histogram 的双变量类似图被称为 “hexbin” 图,因为它展示了落在六角形箱内的观测量。这种绘图对于相对大的数据集效果最好。它可以通过 matplotlib 的 plt.hexbin 函数使用,也可以作为 jointplot 的一种类型参数使用。它使用白色背景的时候视觉效果最好。
当某一块数据密度很大的时候,加深其颜色(一般当数据量较大的时候使用)
def sinplot(flip=1):
data = np.random.random(1000).reshape(500,2)
df = pd.DataFrame(data,columns=['x','y'])
with sns.axes_style("white"):
sns.jointplot(x="x",y="y",kind="hex",data=df,color='k') #kind="hex" 可以设置数据密度较大是,此处的颜色较深
plt.show()
if __name__ == '__main__': sinplot()

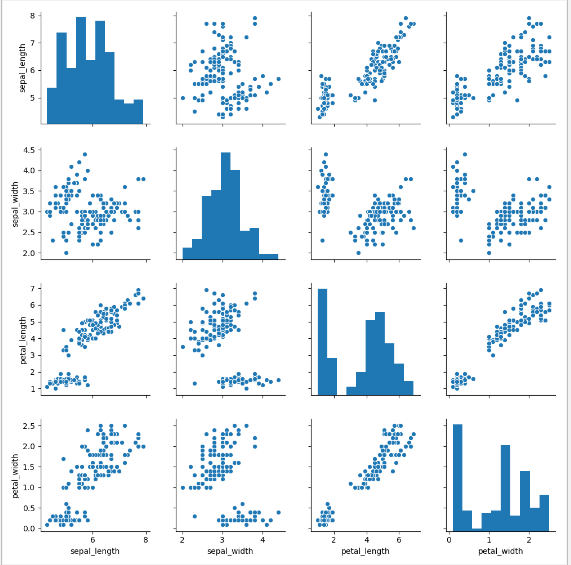
可视化数据集成对关系
为了绘制数据集中多个成对的双变量,你可以使用 pairplot() 函数。这创建了一个轴矩阵,并展示了在一个 DataFrame 中每对列的关系。默认情况下,它也绘制每个变量在对角轴上的单变量。
多个变量之间分析每两个变量之间的关系
def sinplot(flip=1):
iris = sns.load_dataset("iris") # iris为seaborn的内置数据集,数据有四个特征
# pairplot 会绘制数据集中的每一种变量之间的关系图
# 对角线上是每个变量,其他的图为每个变量和另外一个变量的关系散点图
sns.pairplot(iris)
plt.show()
if __name__ == '__main__':
sinplot()
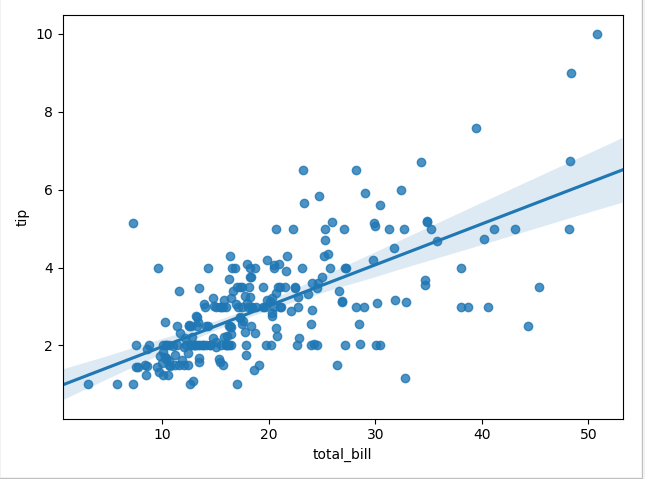
绘制回归图形
regplot()和implot()都可以绘制回归关系,推荐使用regplot() 查看基金的增长关系回归分析
def sinplot():
tips = sns.load_dataset("tips") # 内置数据集,数据集为df类型
#使用regplot绘制回归分析图,拟合出一条最能反映特点的直线
#x_jitter 在原始数据集的基础上增加或者减少一个小范围值,可以更好的绘制出回归模型
sns.regplot(x="total_bill",y="tip",data=tips,x_jitter=0.05)
plt.show()
if __name__ == '__main__':
sinplot()
对有重叠数据分析时,可以将数据稍作偏移,可以更好的观察结果
def sinplot():
tips = sns.load_dataset("tips") # 内置数据集,数据集为df类型
#在数据分析时,有时候可能有大量重复数据,可使用jetter进行些许偏移数据,可以有更好的效果
# 分析星期和消费之间的关系,星期有大量重复值,使用jitter=True可以将数据稍作偏移,以便更好的观察效果
sns.stripplot(x="day",y="total_bill",data=tips,jitter=True)
plt.show()
if __name__ == '__main__':
sinplot()

def sinplot():
tips = sns.load_dataset("tips") # 内置数据集,数据集为df类型
#在数据分析时,有时候可能有大量重复数据,可使用jetter进行些许偏移数据,可以有更好的效果
sns.stripplot(x="day",y="total_bill",data=tips,jitter=True)
sns.swarmplot(x="day",y="total_bill",data=tips)
plt.show()
if __name__ == '__main__':
sinplot()
