[把好的习惯坚持下去]
————————————————————————————————————————————————————————
在现实生活里,我们能够轻而易举的识别人脸,识别语音,阅读,写字,从口袋中取出钥匙,或者根据气味判断苹果是否成熟,这大大掩盖了隐藏在这些貌似简单的识别行为背后的非常复杂的处理机制。模式识别(pattern recognition)----这种输入原始数据并根据其类别采取相应行为的能力----对我们的生存至关重要。为了具有这种能力,在过去的几千万年里面,我们进化出高度复杂的神经和认知系统。
1.绪论
1.1 什么是模式?
广义的说,存在于时间和空间中可观察的物体,如果我们区别它们是否相同或者是否相似,都可以称为模式(pattern)。模式所指的不是事物本身,而是从事物获得的信息,因此,模式往往表现为具有时间和空间分布的信息。模式的直观特性包括:可观察性,可区分性,相似性。
1.2 什么是机器学习?
研究如何构造理论,算法和计算机系统,让机器通过从数据中学习后可以进行如下工作:分类和识别事物,推理决策,预测未来等。(Wiki :Machine learning is a field of computer science that uses statistical techniques to give computer systems the ability to "learn" (e.g., progressively improve performance on a specific task) with data, without being explicitly programmed)
1.3 模式识别与机器学习的研究目的?
利用计算机对物理对象进行分类,在错误概率最小的情况下,使识别的结果尽量与客观物体相符合。Y=F(X)。
其中:X的定义域取自特征集。Y的值域为类别的标号集。F是模式识别的判别方法。
机器学习利用大量的训练数据可以获得更好的预测结果。
1.3.1模式识别系统的目标:
在特征空间和解释空间之间找到一种映射关系,这种关系也称之为”假说“
- 特征空间:从模式得到的对分类有用的度量,属性,或基元构成的空间。
- 解释空间:将c个类别表示为
,其中,Ω为所属类别的集合,称为解释空间。
1.3.2 机器学习的目标:
针对某类任务T,用P衡量性能,根据经验来学习和自我完善,提高性能。
1.3.3 假说的两种获得方法:
监督学习,概念驱动,归纳假说:在特征空间中找到一个与解释空间的结构相对应的假说。在给定模式下假定一个解决方案,任何在训练集合中接近目标的假说也都必须在”未知“的样本上得到近似的结果。特别的:
- 依靠已知所属类别的训练样本集,按它们特征向量的分布来确定假说(通常为一个判别函数),在判别函数确定之后能用它对未知的模式进行分类。
- 对分类的模式要有足够的先验知识,通常需要采集足够数量的具有典型性的样本进行训练。
非监督学习,数据驱动,演绎假说:在解释空间中找到一个与特征空间的结构相对应的假说。这种方法试图找到一种只以特征空间中的相似关系为基础的有效假说。特别的:
- 在没有先验知识的情况下,通常采用聚类分析方法,基于”物以类聚“的观点,用数学分析方法分析各特征向量之间的距离及分散情况。
- 如果特征向量集聚集于若干个群,可按照群间距离远近把他们划分成类。
- 这种按各类之间的亲疏程度的划分,若事先能知道应划分成几类,则可获得更好的分类结果。
1.4 系统构成:
1.4.1 模式识别的系统构成:
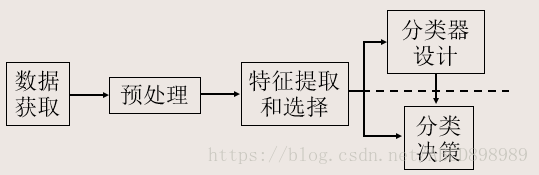
1.4.2 机器学习的系统构成:

1.5 模式识别系统组成单元
- 数据获取:用计算机可以运算的符号来表示所研究的对面。
- 预处理单元:去噪声,提取有用信息,并对输入测量仪器或其他因素所造成的退化现象进行复原。
- 特征提取和选择:对原始数据进行变换,得到最能反映分类本质的特征。
- 测量空间:原始数据组成的空间。
- 特征空间:分类识别赖以进行的空间。
- 模式表示:维数较高的测量空间--->维数较低的特征空间。
4. 分类决策:在特征空间中用模式识别方法把被识别对象归为某一类别。
基本做法:在样本训练集基础上确定某个判别规则,使得按这种规则对被识别对象进行分类所造成的错误识别率最小或者引起的损失最小。
1.6 机器学习系统组成单元
- 环境:是系统的工作对象(包括外界条件),代表信息来源。
---信息水平:相对于执行环节要求而言,由学习环节消除差距。
---信息质量:实例示教是否正确,实例次序是否合理等。
- 知识库:存储学习到的知识
---知识的表示要合理
---推理方法的实现不要太难
---存储的知识是否支持修改(更新)
- 学习环节:是系统的核心模块,是和外部环境的交互接口。
---对环境提供的信息进行整理,分析,归纳或类比,生成新的知识单元,或修改数据库
---接收从执行环节来的反馈信号,通过知识库修改,进一步改善执行环节的行为。
- 执行:根据知识库执行一系列任务
---把执行结果或执行过程中获取的信息反馈给学习环节。
1.7 实例---工厂流水线分拣:
为了显示有关问题的复杂性,我们假设存在这样的一个例子:设想又一个鱼类加工工厂,希望能将传送带上的鱼的品种的分类过程自动进行。首先要做的就是:架设一个摄像机,通过光学感知手段,拍摄若干样品的图像,来区分鲑鱼(salmon)和鲈鱼(sea bass)。注意到这两种鱼确实存在一些物理特性上的差异--比如长度,光泽,宽度,鱼鳍的数目与形状,嘴的位置。我们就利用这些要素作为模式分类的特征(feature)。还注意到图像本身也存在差异,比如光照的不同,鱼在传送带上的位置不同,以及由摄像机电子线路引起的干扰。
如果鲑鱼和鲈鱼两个类别确实存在某种差异,我们称之为具有不同的模型(model)----即可以用数学表达形式的不同特征的描述。模式分类的最终目的和处理方法就是,首先将模式分成几类,然后对感知到的数据进行分类,以滤除干扰(由采样引起而非由模型引起)。然后选择出与感知数据最接近的模型分类。任何模式识别系统不管其设计目标如何,必须首先建立上述概念。
设计执行鱼类分类任务的原型分类系统:首先,摄像机拍摄鱼类的照片。接着,图像信号被预处理,以便方便后续操作,同时不能损失关键信息。特别的,我们应该用分割技术来将不同的鱼分离开来,或者将鱼同背景分离开来。最后,将每条鱼的数据送入特征提取器,其作用是通过测量特定的“特征”或者“属性”来简化原始数据。
预处理器必须能自动调整平均光照度,或者进行阀值化处理,以去除传送带等背景成分。我们先暂时不管鱼的图像如何被分割以及特征提取器和模式分类器如何设计的问题,而是想像一下:假设有人告诉我们“鲈鱼一般要比鲑鱼长”。于是,这就提供了一种可尝试的模型:“鲈鱼有某种典型的长度,鲑鱼也有某种典型的长度,而且鲈鱼的典型长度要比鲑鱼的大”。因此,”长度“就是一个明显的可用于分类的特征。我们可以仅仅通过看一条鱼的长度”L“是否超过某个临界值”L“来判别鱼的种类。为确定恰当的”L",必须先获得不同类别的鱼的若干样本(称为“设计样本”或者“训练样本”),进行长度测量并检查结果。
假设,我们已经完成了上面的工作,并将长度的直方图绘制如下:(”L*“是一个最佳的阀值)
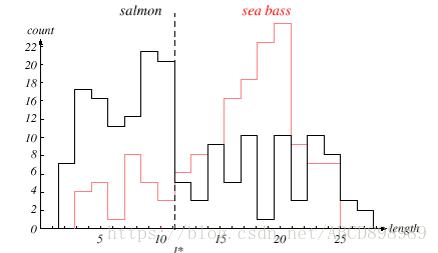
这幅图验证了在平均意义上,“鲈鱼要比鲑鱼的长度长”的结论。不过,这个直方图也清晰并且令人失望的表明了:单一的特征判断是不足以完美分类的。也就是说,无论怎样确定临界值“L",都无法仅仅凭借长度就能区分出两种分类。
虽然遇到了上述的问题,但是未必就此灰心。我们继续尝试使用其他特征,比如鱼的平均光泽度(lightness)。我们小心的消除外界照明光亮度的差异,(因为这会影响模型本身),并降低分类器的性能。最终获得如下图所示。这个结果就比较令人满意,因为两种鱼的分离性更好。(”x*“是一个最佳的阀值)
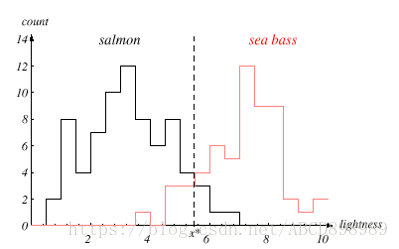
上述考虑导致我们期望有一个分类的”总体代价“的函数。我们真正的任务是要确定一种决策(decision),使得该代价最小。这是决策理论的中心任务,而模式分类可能是其最重要的一个子领域。
即使我们已经有了一个总体代价,并且据此获得了一个最优的决策点”x*“,其分类性能也许仍然不能令人满意。这时,我们第一个想到的是寻求其他的更有利于分类的特征。不过,让我们首先假设:已经没有比光泽度更好的图像特征了。于是我们转而去求助于组合运用多种特征的方法
值得强调的是,在寻求其他特征的努力中,我们发现鲈鱼通常情况下比鲑鱼更宽。这样就有了两个特征----光泽度X1和宽度X2。暂时先不考虑如何在实践中测量这些特征,总之特征提取器已经把整条鱼的数据精简为一个二维特征向量,或者二维特征空间中的一个点:x=【X1,X2】^-1.
现在,我们的问题是把特征空间分成两个区域,使得落在其中一个区域的数据点(鱼)被分类为鲈鱼,而落在另一个区域的数据点被分类为鲑鱼。假定已经对样本特征向量做了测量。并绘制了散布图如下:
(中间斜线是分界线。很明显,这里的总体分类错误,比上图中的最小误差率要小,但是仍然存在)

这个图显示出可以根据如下的准则来区分两种鱼:如果特征向量落在判别边界(decision boundary)的上方,则是鲈鱼,否则是鲑鱼。
看起来这条规则在这个例子中运用的很好,这也提示我们或许有必要嵌入更多的特征(以使得它的分类性能更好)。除了光泽和宽度之外,我们也许想到更多的形状参数,比如背鳍的顶角,眼睛的位置(用鱼嘴到鱼尾的长度比例表示)等等。然而,怎样才能事先知道其中哪个特征对分类性能最重要呢?因为其中某些特征很可能是冗余的。比如,如果鱼眼睛的颜色与宽度完全相关,那么分类器的性能将不因增加了鱼眼睛颜色这一特征而有任何改善。即便不考虑获得更多特征时所需的额外的计算量,我们是否真的有必要采用非常多的特性呢?这样作是否会给将来在非常高维的空间中进行分类操作埋下”祸根“?
再假设,在上述任务中,其他的特征要么太难以测量,要么对分类器毫无用处(甚至起反作用)。这样,我们将只有两个特征好用。如果分类的判决模型非常复杂,分界面也十分复杂(而不像是上图中一条简单的直线),所有的训练样本可以被完美的正确的分类,如下图:
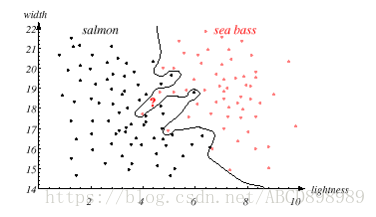
虽然如此,这样的结果也依然不令人满意。这是因为设计分类器的中心目标是能够对新样本(如,之前从未出现过的某一条鱼)做出正确的反应。这就是”推广能力“(generalizaion)的概念。上图那种复杂的判别边界过分”调谐“(tunc)到某些特定的训练样本上了,而不是类别的共同特征,或者说是待分类的全部鲈鱼(或者鲑鱼)的总体模型。
自然的,我们想采集更多的训练样本,以获得特征向量的更好估计。例如,可以使用类别样本的概率分布。可是,在某些模式识别问题中,能够比较容易获得的样本数据毕竟十分有限。即使在连续的特征空间中已经有大量的样本点,可是如果按照上图的思路,分类器将给出极其复杂的判决边界,而且将不太可能很好的处理全新的样本模式。
所以,我们宁可去寻求某种”简化“分类器的方案。其背后的理念是:分类器所需的模型或判别边界将不需要像上图那样复杂。事实上,如果已经能够更好的分类新的测试样本,那么即使它对训练样本集的分类性能不够好,也应该接受这种分类器设计。但是,假如在设计”复杂“的分类器时其推广能力可能不是很好,那么,我们又将如何精确和定量的设计相对”简单“一些的分类器呢?系统怎样才能自动得出下图的那种相对简单的分界线,以使其性能比前面两幅图中的分界曲线更加优越?假如我们能够做到”推广能力“和”复杂度“的折中,又将如何预测系统对新模型的推广能力如何?这些都是统计模式识别中要研究的中心问题。
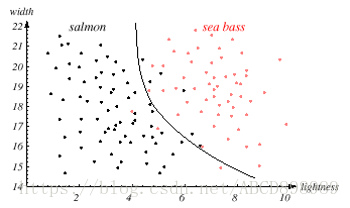
(图中标示出的判别曲线是对训练样本的分类性能和分界面复杂度的一个最优折中。因而对将来的新模式的分类性能也很好)
对相同的输入模式,我们或许需要完成截然不同的任务或者使用完全不同的代价函数。这将导致很不同的结果。例如,假如我们的目的是销售鱼子酱的话,我们很可能试图按照鱼的性别进行分类,把雄性和雌性分开。或者,我们想把受损的鱼筛选出来(其他用途)等等。不同的判决任务将需要不同的特征,其判别边界也与最先的鱼分类问题很不同。
因此,从根本上来说,分类判决任务必然是面向特定任务或特定代价的。因而建造一个通用的,能够精确地执行各种各样的分类任务的人工模式分类机器将是一个极其困难的任务。这使得我们对人类在各种模式分类任务间迅速和灵活的切换更增加了几分赞美和钦佩之心。
从根本上来说,分类的目的在于重建我们所感知到的模式的内在模型。不同的分类技术,很大的依赖于候选模型自身。在设计模式识别系统中,我们关注的是模式的统计特性(一般用概率的观点来表达)。在这里,模式的类型可能是某一特定的特征集合,虽然其中某些预先知道的模式已被某种类型的随机噪声污染。偶尔有人认为”神经模式识别“(或者”神经网络模式分类“)应该确立自己的学科,因为他们的确具有自己特定的学术起源,但我们认为”神经网络“至少应算作是”统计模式识别“(statistical pattern recognition)的一个近亲分支,其中原因后面我们后续很快就会知道。如果模型是由若干逻辑规则集组成,那么就可以应用”句法模式识别“(synatactic pattern recognition)技术。其中采用规则或文法来表达模式类别和判别条件。例如,我们很可能想把英文句子分类为符合语法的,或者反之。在这里,适合采用的是文法规则,而非词频统计或者词语相关性等统计特性。
在鱼分类的例子当中,仔细选择特征是十分必要的。藉此,方能获得一个合理的有利于分类器成功实现的模式表达方式(如上图)。获得一个好的模式表达,是几乎所有的模式识别系统的一个中心任务。这不仅能清楚且自然的揭示组成模式的各部件之间的结构关系。还能有效的表达出未知模式的相应模型。在一些情况下,模式常被表达为实数向量的形式,而另外的情况,可能以有序的属性列表方式来表达。也可能是子部件及其关系的描述等等。我们试图寻找这样的表达,使能够导致同样行为的模式样本之间的距离尽可能近,而使将要导致不同行为的样本之间的距离尽可能远。如果构造或学习一个恰当的表达,以及如何定量刻画”接近“或”远离“的能力将决定一个分类器的成败。我们十分倾向于运用比较少的特征,因为这会导致
(a)更简单的分类区域
(b)更易训练的分类器。
我们也倾向于选择更鲁棒的特征,即对噪声或者其他干扰均不敏感。在实际应用中,我们希望分类器应该快速相应,只需很少的电子部件,内存容量或处理步骤。
当训练样本不足时,一个核心的技术思路是嵌入特定问题领域的背景知识。确实,训练样本越少,背景知识起的作用越大,例如,那些表明测试模式是怎样被产生出来的知识。上述思路的一个极端情况是所谓的”基于综合的分析技术“(analysis by synthesis)。该技术假定事先已经知道产生各个模式的理想模型。考虑语音识别的情况,我们可以假定所有的发生差异均源自各种偶然事件,比如讲话者的性别,年龄,音高等等。在更深的层面上讲,用”物理学“或者”生理学“模型(或者所谓的”运动模型“)对表达发音过程是恰当的。如果我们能从某段声音中判断出它的发生模型(当然,仅仅是如果),那么也就能根据发音过程而知道它的类别。换句话说,产生该模型的过程(或者机制)的表达,也就是模式分类器最好的模型。模式识别系统会根据输入模式是怎样被合成的信息来分析此模式。自然,其技巧在于从感知模式恢复其生成参数。
设想在设计一个根据图像来识别各种类型的椅子的模式分类系统时将遇到的困难。我们知道有标准的办公椅,摩登的卧室椅等等。考虑到椅子的巨大差异,无论椅子腿的数量,用的材料,几何形状等等都可能很不相同,很快你就会感到非常挫折和失败,因为你甚至找不到一个恰当的模式表达能够描述所有的椅子这类东西。也许椅子之间唯一的共性的东西在于其功能:一个稳固的人工制品,用于支撑坐着的人,并且有一个靠背。这样我们试图从图像中看看是否可以推理出相应的功能。其中,”支撑坐着的人“的特性大概可以同一个最大的面的表面朝向有关,虽然关系并不直接,然而上述断言必须能应付”懒人椅子“这种异形的椅子所造成的困难。当然,还包括图像中各种特性的推理理解过程。因而很自然的,与其说问题是”模式识别“的研究内容,还不如说属于”计算机视觉“(computer vision)更为恰当。
虽然还不至于这么极端,但是现实生活中的很多模式识别系统都力求嵌入至少必要的有关模式的产生方法或其功能用途的知识,以期获得很好的表达。当然,表达的目的仍是为了更好的识别,而不是为了重新产生该模式。举个例子来说,光学字符识别系统假设手写字符按照笔画顺序完成,因此,可首先从感知图像中恢复各个笔画的表达,然后再根据辨识出的各笔画,通过推理识别出文字。
2. 如何设计一个模式识别系统
通常涉及如下几个不同步骤的重复:数据采集(collect data),特征选择(choose features),模型选择(choose model),训练和评估(train classifier and evaluate classifier )。接下来我们看看整个设计过程,并考录常见的问题。
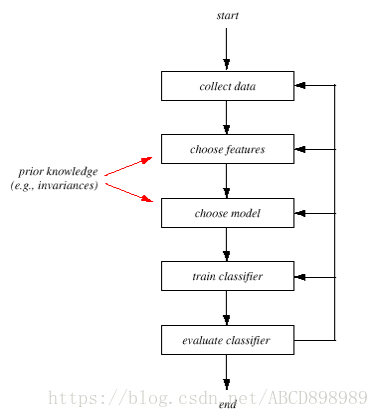
(设计模式识别系统包含这里的一个设计循环。用于训练和测试的数据必须首先被采集。数据的特性描述影响后续的特征选择和模型选择。然后分类器要被训练以确定系统的参数。评价过程常常导致前面处理的多次重复,以得到满意的结果)
2.1 数据采集:
在开发一个模式识别系统总的费用当中,数据采集部分占到令人吃惊的大比重。当然,采用较小的”典型“样本集对问题的可行性进行初步研究也是可以的,但为了确保现场工作时良好的性能,必须要采集和利用多得多的样本数据。可是,怎样才能知道自己已经采集到足够多有代表性的供训练和性能测试试用的数据了呢?
2.2 特征选择:
根据特定的问题领域的性质,选择有明显区分意义的特征,是设计过程中非常关键的一步。实实在在的拿到样本数据,比如传送带上的鱼的照片,诚然有利于选择特征。但是,先验知识同样有重要的作用。
在假想的鱼分类问题中,有关不同鱼种的光泽度的先验知识对于确定可行的合理的特征及设计分类器大有帮助。当然,嵌入知识的过程可以更微妙或更复杂。在一些应用中,知识实际上是从生成模型的信息导出的,比如我们看到的”基于综合的分析“技术。其他一些应用中,知识或许来源于被考察的模式的形态,它的特定属性。比如人脸是有两只眼睛和一个鼻子组成的等等。
在选择或设计特征的过程中,很显然,我们希望发现那些容易提取,对不相关变形保持不变,对噪声不敏感,以及对区分不同类型的模式很有效的特征集。但是,要怎么做才能把先验知识和实验数据有机结合起来,以发现有用的和有效的特征呢?
2.3 模型选择
我们对首次的做出鱼分类器的性能不满意,因而想尝试一下完全不同的类别模型。例如,想利用鱼鳍的位置和数目,眼睛的颜色,重量,嘴的形状等构成特征实现分类函数。我们怎样才能知道设定的类别模型与真实世界的模型存在明显差异,因而需要更换新的模型呢?简而言之,我们怎样知道应该拒绝一类模型而去尝试另一个呢?作为设计者,难道我们从来也不知道怎样才能得到预期的性能改善,而只有一味的重复单调的随机尝试来进行模型选择?或者也可能存在某些原则性的方法,能够指导我们何时应该放弃一个而采纳另一个模型?
2.4 训练
大体的说,利用样本数据来确定分类器的过程成为训练分类器。后续我们会用很大的篇幅来讨论各种各样不同的训练和选择模型的算法。
我们已经看到设计模式识别系统中所会遇到的多种问题。没有一个通用方法可以解决所有的问题。然而过去25年来的反复实验和经验表明”基于样本的学习“的方法是设计分类器最有效的方法。之后所有内容,我们将一再看到”基于样本的学习“的方法如何成为模式识别的中心问题,以及它们在模式识别系统的实践中的本质地位。其中涉及的几个概念:
- 训练集:是一个已知样本集,在监督学习方法中,用来开发出模式分类器。
- 测试集:在设计识别和分类系统时没有用过的独立样本集。
- 系统评价原则:为了更好地对模式识别系统性能进行评价,必须使用一组独立于训练集的测试集对系统进行测试。
2.5 评价
在鱼分类问题当中,当我们从单一特征切换到两个特征时,所依据的理由是,单一特征的分类误差率的评价(evaluation) 不够好,并且完全有可能做得更好。当用”直线分界面“处理那种复杂模型时,同样存在一个评价认为完全有可能做得更好。评价对于评测系统的性能以及决定是否有必要改进其组成部件时,起着重要的作用。
尽管一个过分复杂的系统单纯对训练样本集能够获得完美的表现,但对于新样本则可能不令人满意。这种观察到的现象称为”过拟合“(overfitting)。统计模式识别中最重要的研究领域之一就是确定如何这种调整模型的复杂程度:既不能太简单以至于不足以描述模式类间的差异,又不能太复杂而对新样本的分类能力很差。是否存在原则性的方法能确定一个分类器具有的最佳的(中等程度的)复杂度?
2.6 计算复杂度
有些模式识别问题确定可用某种算法”解决",虽然很不切合实际。(比如,计算资源消耗和计算复杂度远远超过允许的条件)。用更正规的术语,我们可能会问某个算法的“计算复杂度”(computational complexity)是所采用的特征维数,或者模式的数目,或者类别数的什么函数?在计算简便性和分类性能上存在什么样的折中?对于这些问题,我们知道在不考虑工程上的约束的前提下,确实能够设计一个性能非常优秀的识别器。但是如果存在工程上的约束,该如何优化设计方案?相比识别算法而言,我们通常对于学习算法的复杂度考虑的更少,因为前者是在实验室里完成的(通常的看法是:慢一点没关系),而后者要在现场环境工作。尽管计算复杂度常常与设定的模型的复杂度有关联,但二者在概念上是完全不同的。
3. 学习和适应
最广义的讲,任何设计分类器时所用的方法,只要它利用了训练样本的信息,都可以认为运用了学习(算法)。实践中和有意义的模式识别系统都是如此困难的,以至于根本无法事先猜测出一个最佳的分类判决。因此,我们大部分的时间都用于研究学习问题。建造分类器的过程要涉及:给定一般的模型或分类器的形式,利用训练样本区学习或估计模型的未知参数。这里的学习是指用某种算法来降低训练样本的分类误差。一大类基于梯度下降的算法,能够调节分类器的参数,使他朝着能够降低误差的方向前进,目前已成为统计模式识别领域的主流学习算法。
3.1 数据聚类
目标:用某种相似性度量的方法将原始数据组织成有意义的和有用的各种数据集。
是一种非监督学习的方法,解决方案是数据驱动的。
3.2 统计分类:
基于概率统计模型得到各类别的特征向量的分布,以获取分类的方法。特征向量分布的获得是基于一个类别已知的训练样本集。
是一种监督学习的方法,分类器是概念驱动的。
3.3 结构模式识别
该方法通过考虑识别对象的各部分之间的联系来达成识别分类的目的。
识别采用结构匹配的形式,通过计算一个匹配程度值(matching score)来评估一个未知的对象或未知对象某些部分与某种典型模式的关系如何
当成功地制定出了一组可以描述对象部分之间关系的规则后,可以应用一种特殊的结构模式识别方法--句法模式识别,来检查一个模式基元的序列是否遵循某种规则,即句法规则或语法。
3.4 神经网络
神经网络是受人脑组织的的生理学启发而创立的。由一系列相互联系的,相同的单元(神经元)组成。相互之间的联系可以在不同的神经元之间传递增强或抑制信号。增强或者抑制是通过调整神经元相互之间联系的权重系数(weight)来实现的。
神经网络可以实现监督和非监督学习条件下的分类。
3.5 监督学习
监督学习是从由标记的训练数据来推断或者建立一个模型,并依此模型推断新的实例。训练数据包括一套训练实例。在监督学习中,每个实例都是由一个输入对象(通常称为矢量)和一个期望的输出值(称为监督信号)组成。
一个最佳的模型将能够正确地决定那些看不见的实例的标签。常常用于分类和回归。
3.6 无监督学习
无监督学习是我们不告诉计算机怎么做,而是让它自己去学习怎样做一些事情。
无监督学习与监督学习的不同之处在于:事先没有任何训练样本,需要直接对数据进行建模,寻找数据的内在结构及规律,如类别和聚类。常用于聚类,概率密度估计。
3.7 增强学习
增强学习要解决的一个问题:一个能够感知环境的自治机器人,怎样通过学习选择能达到其目标的最优动作。
机器人选择一个动作作用于环境,环境接受该动作后状态发生变化,同时产生一个强化信号(奖或者惩)反馈回来。
机器人根据强化信号和环境当前状态再选择下一个动作的原则是使受到正强化(奖)的概率增大。
3.8 半监督学习
Semi-supervised Learning 是模式识别和机器学习研究领域的重点问题,是监督学习与无监督学习相结合的一种学习方法。它主要考虑如何利用少量的标注样本和大量的未标注样本进行训练和分类的问题。
半监督学习的主要算法有5类:基于概率的算法;在现有监督算法基础上改进的方法;直接依赖于聚类假设的方法;基于多视图的方法;基于图的方法。
至此,我们绪论的部分总结完毕。也许各位和我一样已经被上面这些模式识别与机器学习的内容弄的晕头转向。但是,相信通过后面深入的学习,会逐渐地将各个问题串联起来,融会贯通。
————————————————————————————————————————————————————————
最后,特别说明的是:上述所有的内容虽然不是本人原创作品。但是请各位在转载时注明出处。
参考资料:
《模式分类》 第二版 Richard O. Duda,Peter E.Hart,David G.Stark著