1 机器学习的形式

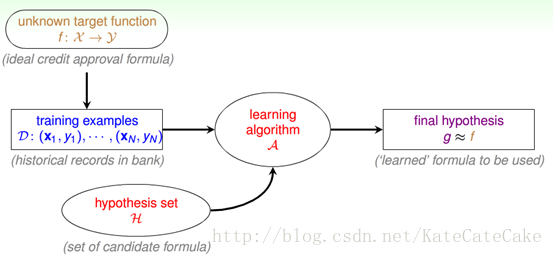
这两个流程图有一些不同,ML机器学习算法一般用A表示。H是值假设空间、或假设集合,包含各种好的或者坏的假设,A的作用就是从H中挑选出最好的假设作为g,去逼近f。
x是条件、属性,y是结果
注:1.输入包括训练样本集和假设空间H
2. 机器学习模型也不仅仅是算法A,还包括假设空间H。
3. 要求得g来近似于未知函数f。
4. 给出了机器学习的一个更准确点的定义,就是通过数据来计算得到一个假设g使它接近未知目标函数。
机器学习的种类(Types)
根据不同种的y空间分类。
1.二元分类(binary classification)
example:
- 信用卡申请 同意/拒绝
- 电子邮件 垃圾邮件/非垃圾邮件
- 患者 生病/治愈
- 广告 盈利/非盈利
- 答案 正确/不正确(KDDCup 2010???)
2.多元分类问题(Multiclass Classification)
硬币识别问题
数字识别问题
水果识别
邮件分类
3.回归问题(Regression)
病人康复预测问题
病人的各种特征=>预测多少天病人可以康复
公司数据=>股票价格
气候数据=>气温
4.结构化学习(structured learning)
序列标签问题
句子=>结构(每个单词的分类,比如名次、动词、代词)
语音数据=>语音解析树
蛋白质数据=>蛋白质折叠
总结

核心方式:二元分类和回归
根据不同的yn标签分类
1.有监督学习(supervised learning)
硬币分类:每个Xn都有对应的yn
label,yn的分类已知。
2.无监督学习,又叫聚类
yn的分类未知。
其他聚类问题举例:
文章=> 主题
消费者档案=>消费群体
存在多种不同的性能目标?
3.半监督学习(semi-supervised)
硬币识别,一部分数据是有yn的。
其他半监督学习举例:
1.一部分有标签labeled的人脸图像=>人脸分分类
2.一部分有标签的药剂数据=>药效预测
利用未标记的数据来避免 昂贵的标签
上语句有些不通顺,大概意思可能是,有些样本进行打标的时候会有比较昂贵的成本,可以通过半监督学习来减少这部分成本。
强化学习(reinforcement learning)
一种非常不同但是自然的学习方式。
eg:训练狗坐下,重复的说sit down
核心:监督学习
根据不同f函数分类
1.批量学习(batch learning)
硬币分类、垃圾邮件分类
2.在线学习(online learning)
垃圾邮件过滤器改善版
1.观察邮件xt。
2.根据现有的gt(xt)预测垃圾邮件状态。
3.从用户那里获取到‘希望的标签’yt,然后根据(xt,yt)更新gt。
注:感知器算法和强化学习经常会用到在线学习‘’。
通过顺序接受数据实例来提升假设空间H,得到更好的g函数。
3.主动学习
定义1:主动学习是半监督机器学习的一个特例,在主动学习中,一个学习算法可以交互式的询问用户(或其他信息源)来获得在新的数据点所期望的输出。
或者,定义2:在某些情况下,没有类标签的数据相当丰富而有类标签的数据相当稀少,并且人工对数据进行标记的成本又相当高昂。在这种情况下,我们可以让学习算法主动地提出要对哪些数据进行标注,之后我们要将这些数据送到砖家那里让他们进行标注,再将这些数据加入到训练样本集中对算法进行训练。这一过程叫做主动学习。
特点:由于是学习算法自己对样本提出要求,那么用来训练的样本数量一般是远远低于普通的学习方法的。
根据输入X空间来分
1.有具体的特征(concrete features)
x的每一个唯独都具有复杂的物理意义。
举例:
1硬币分类:硬币的尺寸质量
2.原始特征(raw features)
eg:手写数字识别。
一个典型的有监督多分类问题。
如果用concrete的话,根据对称(symmetry)和密度(density);
如果用raw的话,16x16灰度图像,简单的物理意义,导致比concrete更加困难。
经常需要人工或机器去将其穿华为concrete特征。
3.抽象特征
eg:评级预测问题
特征没有实际的物理意义,造成了很大的困难。
eg:家教系统中的student Id。
同样需要进行特征转化。