一、CSDN csdn中文翻译
原文 https://people.xiph.org/~jm/demo/rnnoise/
搜索深度学习语音去噪
中文翻译:
GitHub: https://github.com/as472780551/rnnoise
好吧,这一切都很好,但是它听起来是怎样的呢?下面是一些RNNoise在工作中的例子,消除了三种不同类型的噪声。训练中既没有使用噪音,也没有使用干净的语言。
抑制算法
噪声级(SNR)
声音的强弱用分贝(dB)表示。0dB是人能听到最弱音;30dB~40dB是较为理想的安静环境。为保护听力,声音不能超过90dB;为保证工作和学习,声音不能超过70dB;要保证休息和睡眠,声音不能超过50dB。
dB是表示倍数的,10lg(倍数),就是以dB为单位表示的倍数。
0dB说明倍数是1。
噪声种类

Where from here?
If you'd like to know more about the technical details of RNNoise, see this paper (not yet submitted). The code is still under active development (with no frozen API), but is already usable in applications. It is currently targeted at VoIP/videoconferencing applications, but with a few tweaks, it can probably be applied to many other tasks. An obvious target is automatic speech recognition (ASR), and while we can just denoise the noisy speech and send the output to the ASR, this is sub-optimal because it discards useful information about the inherent uncertainty of the process. It's a lot more useful when the ASR knows not only the most likely clean speech, but also how much it can rely on that estimate. Another possible "retargeting" for RNNoise is making a much smarter noise gate for electric musical instruments. All it should take is good training data and a few changes to the code to turn a Raspberry Pi into a really good guitar noise gate. Any takers? There are probably many other potential applications we haven't considered yet.
If you would like to comment on this demo, you can do so on here.
—Jean-Marc Valin ([email protected]) September 27, 2017
虽然它被用作库,但提供了一个简单的命令行工具作为示例。它操作的原始16位(机器端)单PCM文件采样在48千赫.它可用于:
二、深度学习在语音增强方面的最新进展是什么?
https://www.zhihu.com/question/273665262
三、基于RNN的音频降噪算法 (附完整C代码)
https://blog.csdn.net/QFire/article/details/79886543
四、
什么是PCM音频数据
PCM(Pulse Code Modulation)也被称为脉冲编码调制。PCM音频数据是未经压缩的音频采样数据裸流,它是由模拟信号经过采样、量化、编码转换成的标准的数字音频数据。
2.PCM音频数据是如何存储的
如果是单声道的音频文件,采样数据按时间的先后顺序依次存入(有的时候也会采用LRLRLR方式存储,只是另一个声道的数据为0),如果是双声道的话就按照LRLRLR的方式存储,存储的时候还和机器的大小端有关。大端模式如下图所示:
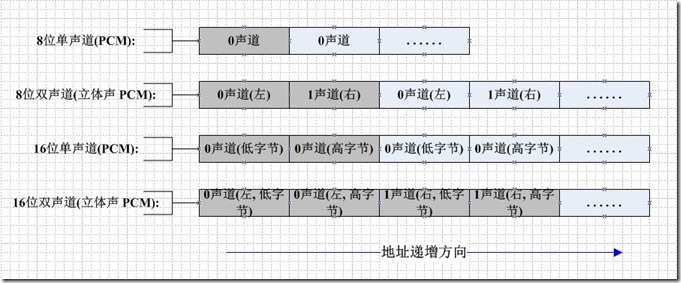
3.PCM音频数据中常用的专业术语
一般我们描述PCM音频数据的参数的时候有如下描述方式
44100HZ 16bit stereo: 每秒钟有 44100 次采样, 采样数据用 16 位(2字节)记录, 双声道(立体声);
22050HZ 8bit mono: 每秒钟有 22050 次采样, 采样数据用 8 位(1字节)记录, 单声道;44100Hz指的是采样率,它的意思是每秒取样44100次。采样率越大,存储数字音频所占的空间就越大。
16bit指的是采样精度,意思是原始模拟信号被采样后,每一个采样点在计算机中用16位(两个字节)来表示。采样精度越高越能精细地表示模拟信号的差异。
一般来说PCM数据中的波形幅值越大,代表音量越大。
4.PCM音频数据的处理
4.1.分离PCM音频数据左右声道的数据
因为PCM音频数据是按照LRLRLR的方式来存储左右声道的音频数据的,所以我们可以通过将它们交叉的读出来的方式来分离左右声道的数据
4.2.降低某个声道的音量
因为对于PCM音频数据而言,它的幅值(即该采样点采样值的大小)代表音量的大小,所以我们可以通过减小某个声道的数据的值来实现降低某个声道的音量
4.3.将PCM音频数据转换成WAV格式
WAV为微软公司(Microsoft)开发的一种声音文件格式,它符合RIFF(Resource Interchange File Format)文件规范,用于保存Windows平台的音频信息资源,被Windows平台及其应用程序所广泛支持。WAVE文件通常只是一个具有单个“WAVE”块的RIFF文件,该块由两个子块(”fmt”子数据块和”data”子数据块),它的格式如下图所示
视音频数据处理入门:PCM音频采样数据处理
https://blog.csdn.net/leixiaohua1020/article/details/50534316
用文本编辑器,比如说UltraEdit,打开该WAV歌曲文件,然后选中文件头的44个字节并剪切(因为退格键不管用),将这44个字节删掉,保存后更名并把后缀改成pcm即可,如下图所示。
最常见的WAV格式文是在PCM裸流的基础上加上44字节的文件头构成的,此时PCM的采样率是8KHz,量化位数是16位,当采用8位的量化位数时,文件头的长度可以达到58位。比如说Windows下自带的那个录音机录下的WAV,文件头有58个字节。
所以,比较好的办法是,首先读取n个长度的一段字符,例如60个,然后从中查找关键字“data”,“data”之后的一个DWORD是实际音频数据的长度,得到这个长度length,再从这DWORD后开始读取length个字节,就可以读到文件尾。如下图所示,用UltraEdit打开一个WAV文件,可以看到关键字data,data之后红框中的四个字节就是length。
