1.1 环境
使用deepin系统、Hadoop3.1.3和Java环境jdk-8u162-linux-x64.tar.gz。
https://pan.baidu.com/s/1K1U1dypbgJeFvjHIGPcMqQ
提取码: 2vsi
1.2 准备
1.创建用户hadoop,按ctrl+alt+t打开终端,输入如下命令,并使用/bin/bash作为shell。
$ sudo useradd -m hadoop -s /bin/bash
2.设置用户密码。
$ sudo passwd hadoop
3.为用户增加管理员权限。
$ sudo adduser hadoop sudo
创建完用户后,切换到hadoop用户。
4.更新apt,需要使用apt安转软件。
$ sudo apt-get update
5.安装vim,便于后面使用
$ sudo apt-get install vim
1.3 安装SSH、配置SSH无密码登录
1.集群、单节点模式都需要要用到SSH登录。
$ sudo apt-get install openssh-server
2.安装后,可以使用如下命令有密码(yes)登录
$ ssh localhost
3.配置无密码登录,后可以使用上述命令无密登录。
$ exit # 退出刚才的 ssh localhost
$ cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
$ ssh-keygen -t rsa # 会有提示,都按回车就可以
$ cat ./id_rsa.pub >> ./authorized_keys # 加入授权
1.4 安转Java环境
1.登录到hadoop用户,创建安装环境的文件夹
$ cd /usr/lib
$ sudo mkdir jvm
2.通过cd命令进入Hadoop3.1.3和Java环境jdk-8u162-linux-x64.tar.gz所在文件夹Personal File(根据每个人的实际位置)。解压Java环境
$ sudo tar -zxvf ./jdk-8u162-linux-x64.tar.gz -C /usr/lib/jvm #把JDK文件解压到/usr/lib/jvm目录下
3.可以看到/usr/lib/jvm下具有一个jdk1.8.0_162目录。下面通过vim进行环境配置。
$ cd ~
$ vim ~/.bashrc
4.按i键,进入vim的输入模式,在文件开头添加如下语句。
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_162
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
5.按Esc,然后输入:wq 保存退出。通过如下命令让配置生效。
$ source ~/.bashrc
6.查看是否安转成功。
$ java -version

出现如上信息表示安装成功。
1.5 安装hadoop
1.通过cd命令进入hadoop3.1.3的所在目录文件夹Personal File(根据每个人的实际位置)。
$ sudo tar -zxf ./hadoop-3.1.3.tar.gz -C /usr/local #解压到/usr/local中
2.进入安装目录更改文件夹名称为hadoop。
$ cd /usr/local/
$ sudo mv ./hadoop-3.1.3/ ./hadoop
$ sudo chown -R hadoop ./hadoop #修改文件权限
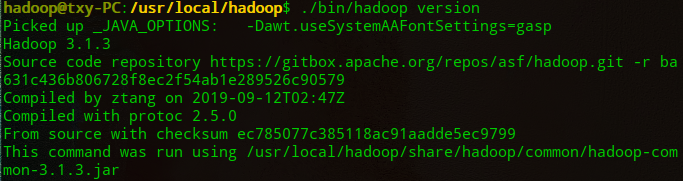
3.检查hadoop安装是否可用,显示hadoop版本信息则可用。
$ cd /usr/local/hadoop
./bin/hadoop version
1.6 Hadoop单机配置(非分布式)
1.hadoop默认模式为分布式模式,可以直接运行如下命令,可以看到Hadoop自带的例子,包括wordcount、terasort、join、grep 等。
$ ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar
2.我们运行grep例子,将input文件中的所有文件作为输入,筛选符合表达式dfs[a-z.]+的单词并统计出现的次数,输出到output文件夹。
$ cd /usr/local/hadoop
$ mkdir ./input
$ cp ./etc/hadoop/*.xml ./input # 将配置文件作为输入文件
$ ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep ./input ./output 'dfs[a-z.]+'
$ cat ./output/* # 查看运行结果

3.下次运行需要删除./output文件,Hadoop不会默认覆盖结果文件。
$ rm -r ./output
源文档
http://dblab.xmu.edu.cn/blog/2441-2/#more-2441
常识和常用技能:
1.终端复制粘贴快捷键:ctrl+shift+V。
2.在linux中,~代表的使用户主文件夹,即“/home/用户名”这个目录。
3. 相对路径和绝对路径:相对路径:./bin/… 、./etc/… ,包含./的路径为相对路径,它会将当前路径替换./组合成完整的路径( 绝对路径)来执行。因此需要时刻注意自己的路径是否正确。
4.linux的主目录如下:home下包含所有的用户,每个用户有自己的所属文件。

