版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/lll1528238733/article/details/76034286
序列分解
1、非季节性时间序列分解
移动平均MA(Moving Average)
①SAM(Simple Moving Average)
简单移动平均,将时间序列上前n个数值做简单的算术平均。
SMAn=(x1+x2+…xn)/n
②WMA(Weighted Moving Average)
加权移动平均。基本思想,提升近期的数据、减弱远期数据对当前预测值的影响,使平滑值更贴近最近的变化趋势。
用Wi来表示每一期的权重,加权移动平均的计算:
WMAn=w1x1+w2x2+…+wnxn
R中用于移动平均的API
install.packages(“TTR”)
SAM(ts,n=10)
- ts 时间序列数据
- n 平移的时间间隔,默认值为10
WMA(ts,n=10,wts=1:n)
- wts 权重的数组,默认为1:n
#install.packages('TTR')
library(TTR)
data <- read.csv("data1.csv", fileEncoding="UTF8")
plot(data$公司A, type='l')
data$SMA <- SMA(data$公司A, n=3)
lines(data$SMA)
plot(data$公司A, type='l')
data$WMA <- WMA(data$公司A, n=3, wts=1:3)
lines(data$WMA)
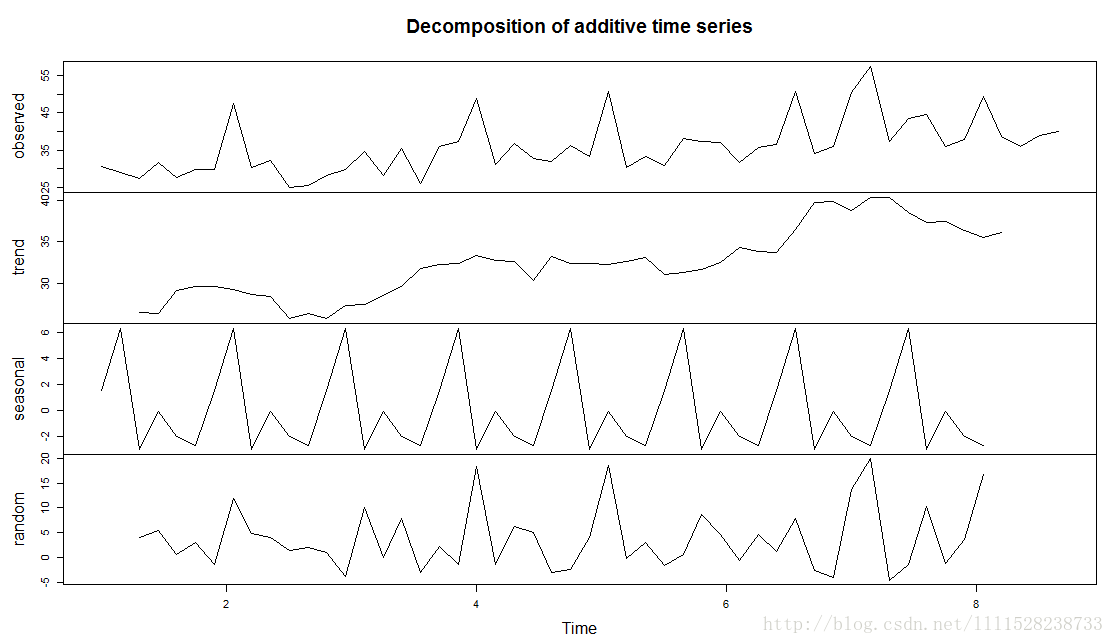
2、季节性时间序列分解
在一个时间序列中,若经过n个时间间隔后呈现出相似性,就说该序列具有以n为周期的周期性特征。
分解为三个部分:
①趋势部分
②季节性部分
③不规则部分
R中用于季节性时间序列分解的API
序列数据周期确定
- freg<-spec.pgram(ts,taper=0, log=’no’, plot=FALSE)
- start<-which(freq
spec==max(freq spec))周期开始位置 - frequency<-1/freq
freq[which(freq spec==max(freq$spec))]周期长度
序列数据分解
decompose(ts)
data <- read.csv("data2.csv", fileEncoding = "UTF8")
freq <- spec.pgram(data$总销量, taper=0, log='no', plot=FALSE);
start <- which(freq$spec==max(freq$spec))
frequency <- 1/freq$freq[which(freq$spec==max(freq$spec))]
data$均值 <- data$总销量/data$分店数
freq <- spec.pgram(data$均值, taper=0, log='no', plot=FALSE);
start <- which(freq$spec==max(freq$spec))
frequency <- 1/freq$freq[which(freq$spec==max(freq$spec))]
plot(data$均值, type='l')
meanTS <- ts(
data$均值[start:length(data$均值)],
frequency=frequency
)
ts.plot(meanTS)
meanTSdecompose <- decompose(meanTS)
plot(meanTSdecompose)
#趋势分解
meanTSdecompose$trend
#季节性分解数据
meanTSdecompose$seasonal
#随机部分
meanTSdecompose$random