
摄影:Chris Lawton on Unsplash
一、说明
平稳性是时间序列问题中的一个关键概念。它是指统计属性(如均值、方差和协方差)随时间变化的稳定性。为了建立有效的预测模型并确定时间序列数据中有意义的模式,了解平稳性的概念以及它与时间序列分析中其他关键概念的关系至关重要。
二、内容和要点
它不是可以孤立地解释和理解的东西。它直接或间接地与太多的主题和概念有关。我认为,为了很好地理解这个主题,有必要彻底理解这些其他相关概念。出于这个原因,我将首先在我的文章中提供有关这些概念的信息。然后我们将继续讨论平稳性问题。
概念
- 外推法
- 随机过程
- 联合分销
- 白噪声
- 季节性
- 周期
- 趋势
- 随机游走
Stationarity
- What
- Why
- Types
Detection of Stationarity
- ADF
- Rolling
- KPSS
- Unit Roots
Transformation
- Differencing
- Decomposition
Conclusion
三、基本概念
3.1 外推法
我们尝试将时间序列作为回归问题来解决。但是,其他回归问题中使用的技术(例如通过查看房屋有多少个房间来估计房屋的价格)不适用于时间序列。在这里,我们需要一种不同的方法。这就是为什么我们使用其他名称为ARIMA和SARIMA的模型来解决时间序列问题的原因。
时间序列问题是外推问题。
假设我们想估计我们的房子将消耗多少天然气(这是当今的热门话题)。
一种方法是,我们可以将以前的消耗值和平均每日温度一起绘制。然后,我们拟合最适合这些数据点的回归线。我们可以通过回归曲线根据当天的温度来估计消耗量。

消耗与温度。图片由作者提供。
我们在这里做的是一个插值。我们在现有数据范围内进行预测。我们的预测是准确的,因为我们在范围内有许多数据可以支持我们的预测。
在外推中,我们的预测超出了范围。我们扩展了适合已知数据点的函数。离已知范围越远,预测的准确性就越低。
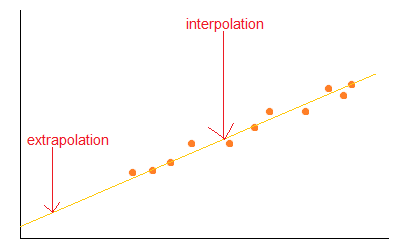
现在,让我们从时间序列的角度来看问题。这一次,我们尝试预测前一天的消耗值的每日天然气消耗量。
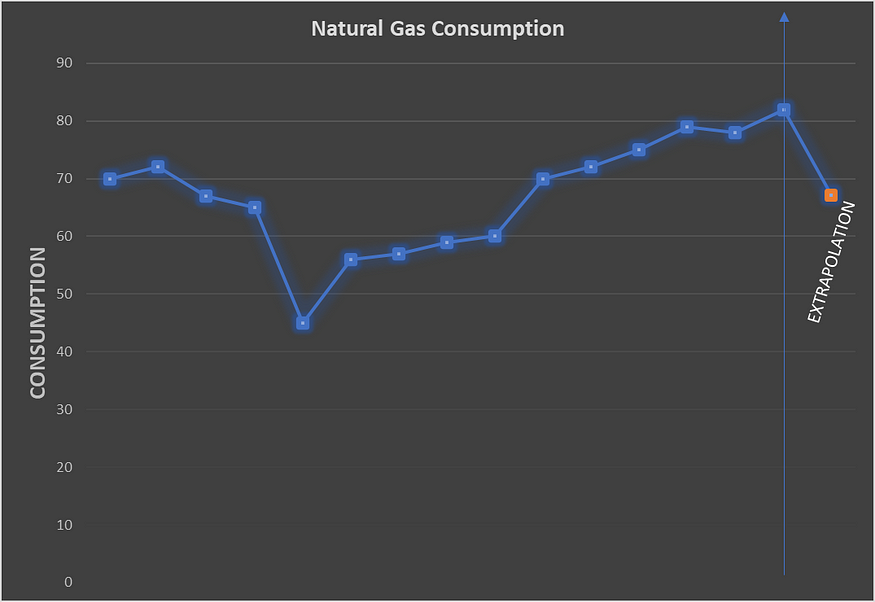
消耗时间序列。图片由作者提供。
在这里,当我们尝试预测第二天的消费量时,我们正在推断,这意味着我们正在估计超出我们当前数据范围的东西。
我在上面提到,当我们进一步推断时,我们结果的可靠性会降低得更多。例如,我们在这里的第一个预测会有一定的误差。由于我们将根据第一个预测第二天的预测,因此第二个也将受到第一个误差的影响。这样,随着时间的流逝,错误将像滚雪球一样增长。
3.2 随机过程
随机变量是其值不确定或未知的量,由实验结果决定。它是一个将实验结果映射到数值的函数。
随机过程是随机变量的集合,这些变量不断演变并按时间编制索引。例如,可以将公司一段时间内的股票价格建模为随机过程,给定时间股票价格的每个值都表示一个随机变量。随机过程描述了随机变量随时间的变化,可以通过均值、方差和自相关函数来表征。
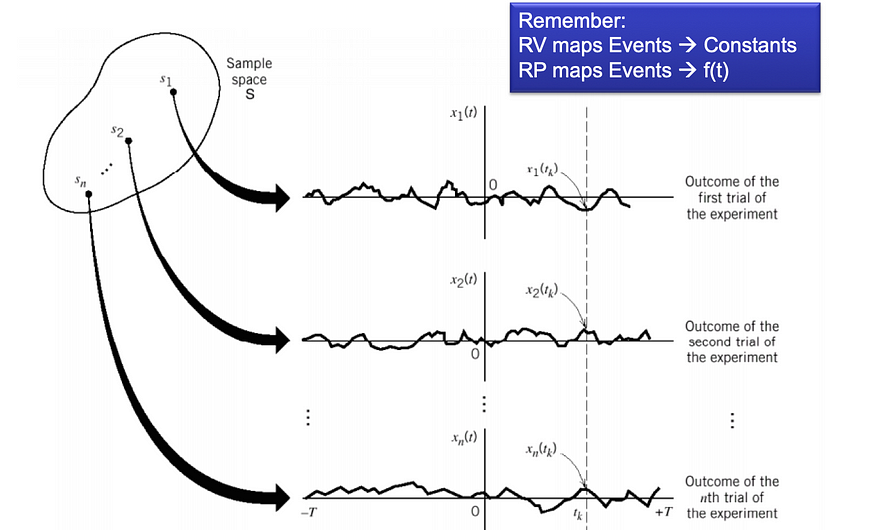
随机过程。源
我们有两个变量;t: 时间和 s: 样本(来自样本空间 S): X(t,s)
我们可以将随机过程分为确定性和非确定性(随机)。
- 随机指标:我们无法从当前值预测未来值。现实生活中的例子:股票价格、交通流量、天气模式、生物系统、电力需求
- 确定性:一旦我们知道它是如何开始的,我们就可以得到未来的值。例如,你有一个信号是 X(t,s) = cos(2πt + s),如果你知道什么是 s,那么你就可以预测未来的值。现实生活中的例子:制造过程、人口增长、太阳能系统、机械系统......
让我们用 Python 编写一个随机过程:
import numpy as np
import matplotlib.pyplot as plt
n_step = 100 # we will measure 100 times
step_size = 0.1 # we will measure every 0.1 seconds
# time steps (x axes)
time = np.arange(0, n_step * step_size, step_size)
# random noise with mean 0 and standard deviation 1
noise = np.random.normal(0, 1, num_steps)
# random process as the cumulative sum of the noise
random_process = np.cumsum(noise) * step_size
# plot
plt.plot(time, random_process)
plt.xlabel('Time')
plt.ylabel('Measurement')
plt.title("Random Process")
plt.show()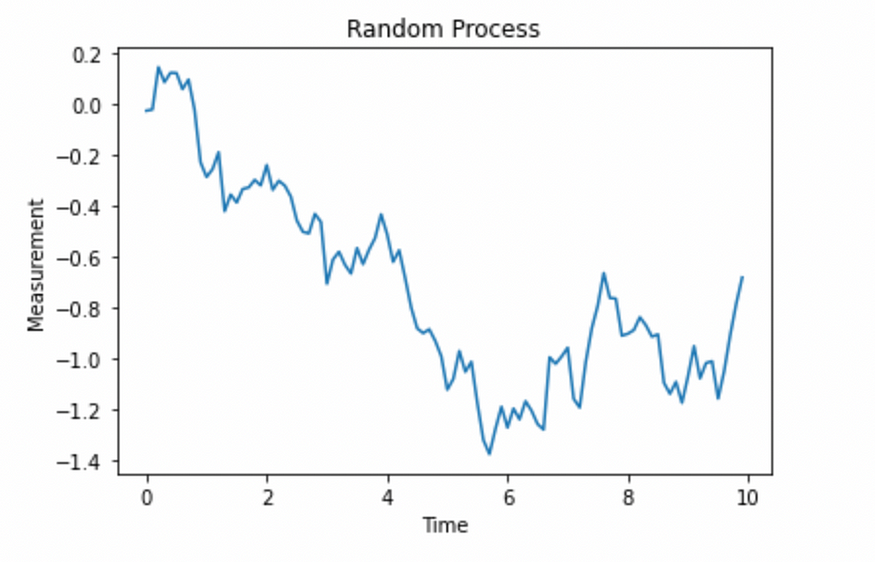
图片由作者提供。
3.3 联合分布
联合分布是一种概率分布,它描述了两个或多个随机变量同时具有特定值的概率。简而言之,它计算两个事件同时发生的可能性。
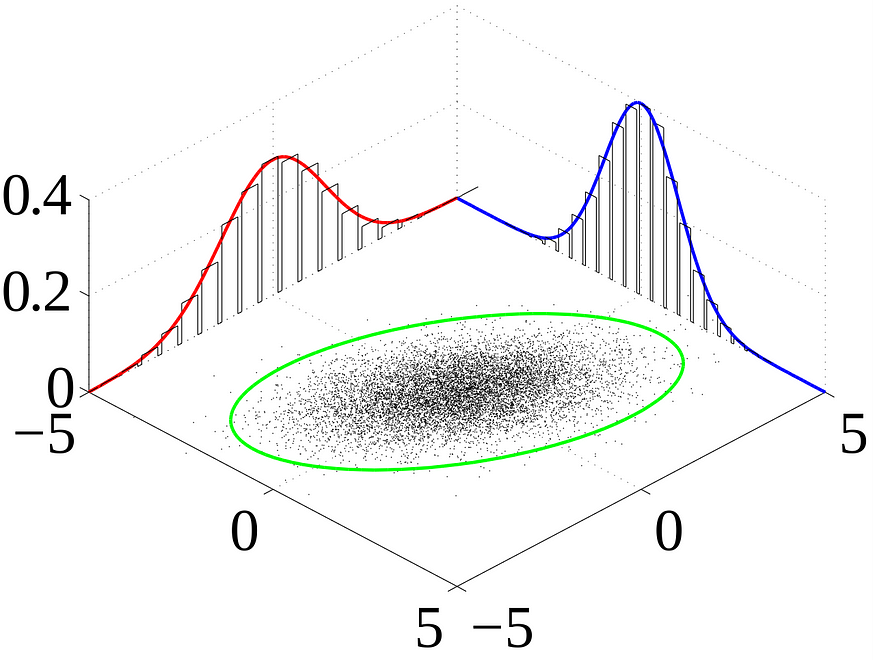
许多样本观测值(黑色)是根据联合概率分布显示的。还显示了边际密度。来源:维基百科
时间序列表示随机过程的一种可能结果,该结果可以通过其完全联合概率分布来完全表征,该概率分布包含随机过程在无限时间段内可以采用的所有可能的值组合。
例如,如果我们有一个代表股票每日收盘价的时间序列,则可能是随机过程的实现,该过程模拟了股票价格随时间的变化行为。这个随机过程的完全联合概率分布将指定每日收盘价的所有可能序列的概率,同时考虑到影响股票价格的所有因素,如经济新闻、市场状况和投资者情绪。
如果时间序列是平稳的,那么它与滞后的联合分布应该是时间不变的。换句话说,分布不应随着时间索引的变化而变化。这可以通过比较时间序列的联合分布及其在不同时间点的滞后来验证。
我们可以计算上述随机过程及其滞后的联合分布,如下所示:
lag = 10
# stack them into 2D arr
joint = np.vstack([random_process[:-lag], random_process[lag:]])
# 2D Density plot
sns.jointplot(joint[0], joint[1], kind="kde")
plt.show()
联合分发。图片由作者提供。
3.4 白噪声
这是一个没有可辨别结构的系列。根据定义,它是不可预测的。白噪声过程有一些标准:
- 平均值为零。
- 标准差随时间变化恒定。
- 滞后之间的相关性为零。
y_t = 信号 + 噪声
我们可以将时间序列视为信号和噪声的组合。我们可以在信号上建立一个模型。另一方面,噪音是完全不可预测的。
当残差 (= y_t — signal_model_outcome) 接近白噪声过程时,这意味着模型在解释观测数据方面做得很好。残差中的任何剩余变异性都可以归因于随机误差或噪声。另一方面,如果残差不接近白噪声过程,则意味着模型不适合数据,并且残差中仍然存在模型未考虑的模式或相关性。
让我们在 Python 中生成一些白噪声:
import numpy as np
mean = 0
std_dev = 1
length = 100
white_noise_signal = np.random.normal(mean, std_dev, length)
print("Mean: ", np.mean(white_noise_signal)) #Mean: -0.1490592783325961
plt.plot(white_noise_signal)
plt.title("White Noise")
plt.xlabel("Time")
plt.ylabel("Amplitude")
plt.show()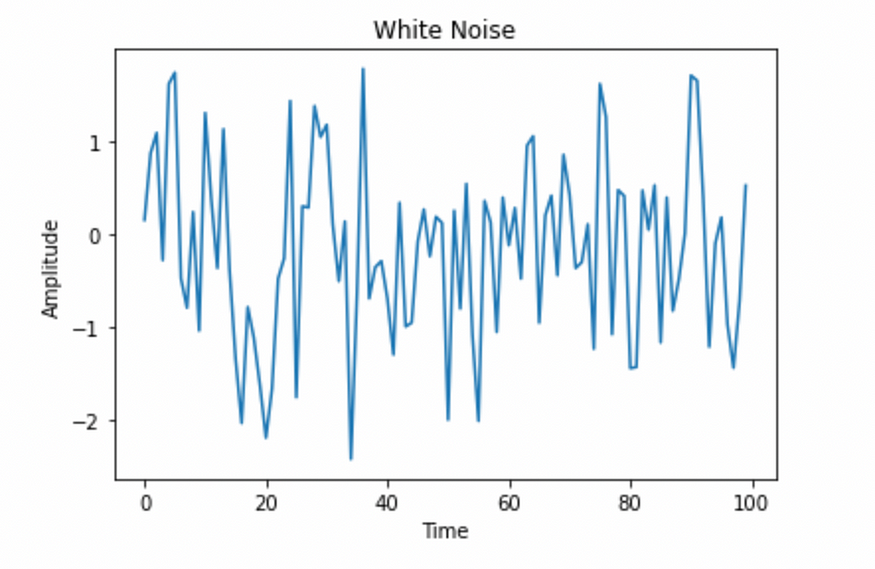
白噪声信号。图片由作者提供。
我们可以使用自相关函数(ACF)工具来测试时间序列是否为白噪声过程。
ACF 测量时间序列与其滞后值之间的相关性。如果是白噪声,则表示其值是独立且不相关的,因此对于所有滞后,ACF 应接近于零。
from statsmodels.graphics.tsaplots import plot_acf
# plotting the autocorrelation function
plot_acf(white_noise_signal, lags=20, alpha=0.05)
plt.show()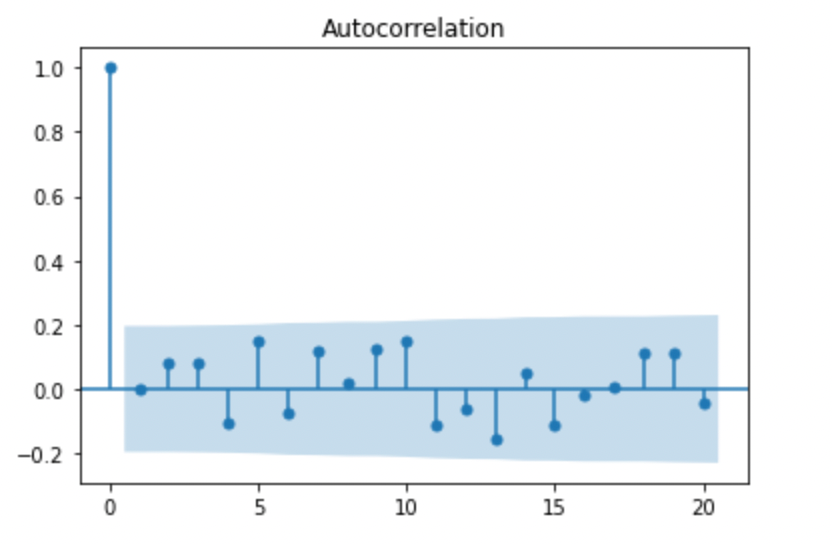
ACF.图片由作者提供。
lags参数指定要包含在图中的滞后数。 是显著性水平(通常取为 0.05 -> 95% 置信水平)。alpha
如果大多数滞后的自相关值接近于零,则表示序列是白噪声过程。
3.5 季节性
季节性是随着时间的推移而重复的规律和可预测的模式。这些模式可以发生在不同的时间尺度上,例如每天、每周、每月或每年。
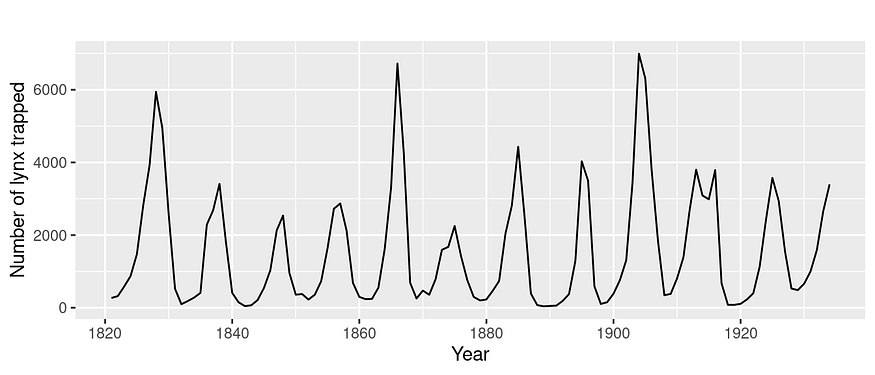
加拿大猞猁数据。源
我们可以在 Python 中生成季节性时间序列数据。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# a time series with a yearly pattern
range_date = pd.date_range(start='1/1/2021', end='12/31/2023', freq='D')
data = pd.Series(range_date, index=range_date)
data = np.sin(2 * np.pi * (data.index.dayofyear / 365))
# plot
plt.plot(ts)
plt.title("Seasonal T.S.")
plt.xlabel("Day")
plt.ylabel("Val")
plt.show()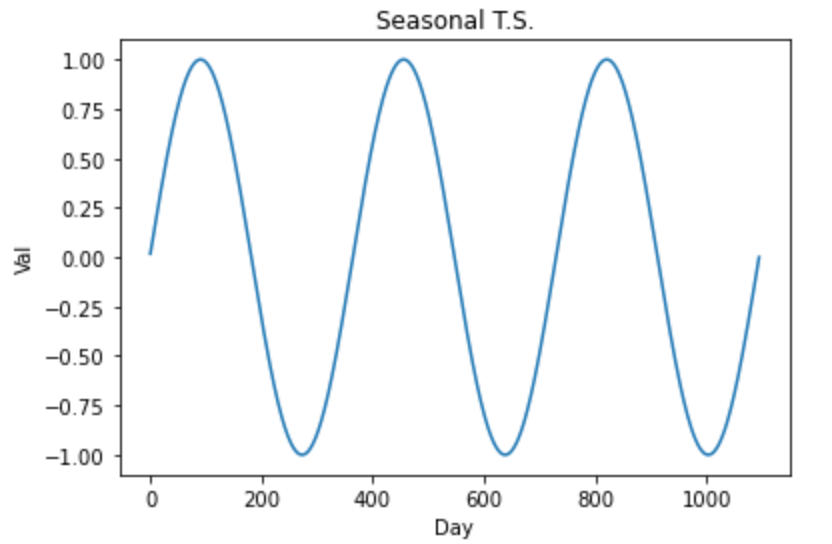
虚拟季节性时间序列图。图片由作者提供。
如果时间序列具有季节性分量,则将其视为非平稳的。这使得它不适合使用自回归模型进行分析。为了克服这一点,有必要识别并消除时间序列中的季节性成分。通过这样做,我们将获得一个没有季节性并且可以与自回归模型一起使用的新系列。
有几种方法可以识别和消除季节性成分。我们将在帖子后面检查它们。让我们继续回顾这些概念。
3.6 周期
周期与季节性一样,是一种时间序列模式。主要区别在于重复模式的长度。周期具有较长的时间间隔,例如年。比如一个企业多年来的增长和收缩周期,或者一个地区农产品收成的丰收或干旱。
3.7 趋势
趋势是时间序列中的长期模式或运动。它可以是向上、向下或平坦的。它提供有关数据随时间变化的方向和幅度的信息。
import pandas as pd
import matplotlib.pyplot as plt
# a dummy trend data
dates = pd.date_range(start='2022-01-01', end='2023-12-31', freq='D')
df = pd.DataFrame(data=range(0,len(dates)), index=dates, columns=['Value'])
# this will add a drop at the beginning of the next year
df['Value'] = df['Value'] + 1000 * df.index.dayofyear / 365
# plot
df.plot(figsize=(12, 5))
plt.title("Trend Data")
plt.ylabel("Value")
plt.show()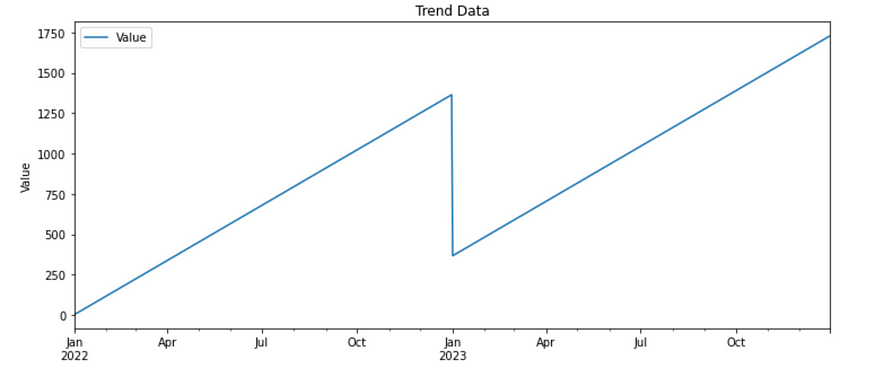
在 Python 中生成的虚拟趋势数据。图片由作者提供。
从年初到年底有一个非常强劲的上升趋势。新年的第一天有一个急剧的下降(这可能是由任何事情引起的),然后又回到了上升趋势中。
3.8 随机游走过程
随机游走过程是一种特殊类型的随机过程,其中当前值等于前一个值加上随机误差项(即白噪声)。
Yt = Yt-1 + wt 和 wt 是白噪声。
随机游走过程中没有模式。时间序列是纯随机的,变量的行为随时间变化。这意味着时间的变化是一个随机变量。
随机游走通常用于对金融时间序列(如股票价格或汇率)进行建模,其中价格会因新闻事件、经济状况和投资者情绪等潜在因素的组合而随时间变化。
随机游走。源
对 Y 在下一个周期中最准确的预测是其当前值。均值是恒定的,但方差不是。因此,随机游走过程不是静止的。
四、平稳性
4.1 平稳性什么?
平稳时间序列的统计行为随时间推移保持不变。这并不意味着它们不会改变,它们会改变,但变化本身是随机的。时间序列必须具有一些统计属性才能保持平稳:
- 常量平均值:随着时间的推移没有趋势。
- 常量方差、协方差:数据尺度不变,观测值之间的关系一致。
- 无季节性:季节性数据的统计属性定期变化。因此,均值存在变化模式。
让我们违反常数均值原则:
import numpy as np
import matplotlib.pyplot as plt
# linear trend data
x = np.arange(0, 100, 1)
y = x + np.random.normal(0, 10, 100)
plt.plot(x, y)
plt.xlabel("Time Step")
plt.ylabel("Value")
plt.title("Violating Constant Mean")
plt.show()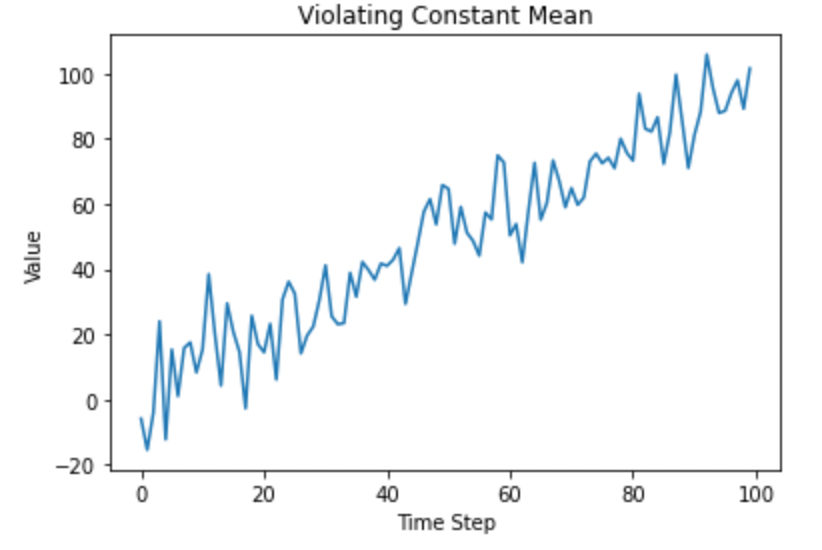
平均值不是恒定的。图片由作者提供。
让我们违反常数方差原则:
import numpy as np
import matplotlib.pyplot as plt
# an increasing variance dummy data
x = np.arange(0, 500, 1)
y = np.sin(x / 5) * np.exp(0.01 * x) + np.random.normal(0, 10, 500)
plt.plot(x, y)
plt.xlabel("Time Step")
plt.ylabel("Value")
plt.title("Violating Constant Variance")
plt.show()
方差不是恒定的。图片由作者提供。
季节性数据不能是静止的:
import numpy as np
import matplotlib.pyplot as plt
# dummy seasonal data
x = np.arange(0, 500, 1)
y = np.cos(x / 10) + np.random.normal(0, 1, 500)
# Plot the time series
plt.plot(x, y)
plt.xlabel("Time Step")
plt.ylabel("Value")
plt.title("Violating No Seasonality")
plt.show()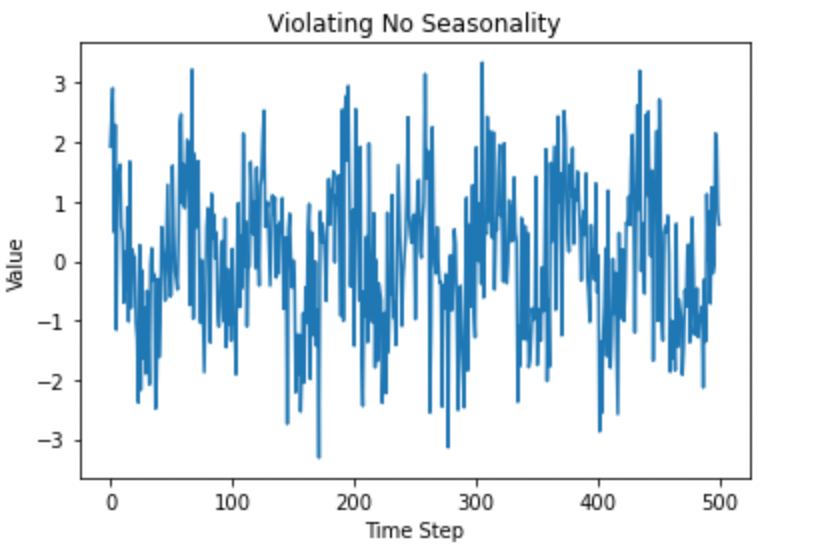
季节性。图片由作者提供。
现在,让我们生成平稳的时间序列数据并检查每个条件:
import numpy as np
import matplotlib.pyplot as plt
m = 10 #mean
stddev = 2 #standard deviation
# generate dummy data
x = np.arange(0, 200, 1)
y = np.random.normal(m, stddev, 200)
plt.plot(x, y)
plt.xlabel("Time Step")
plt.ylabel("Value")
plt.title("Stationary Time Series")
plt.show()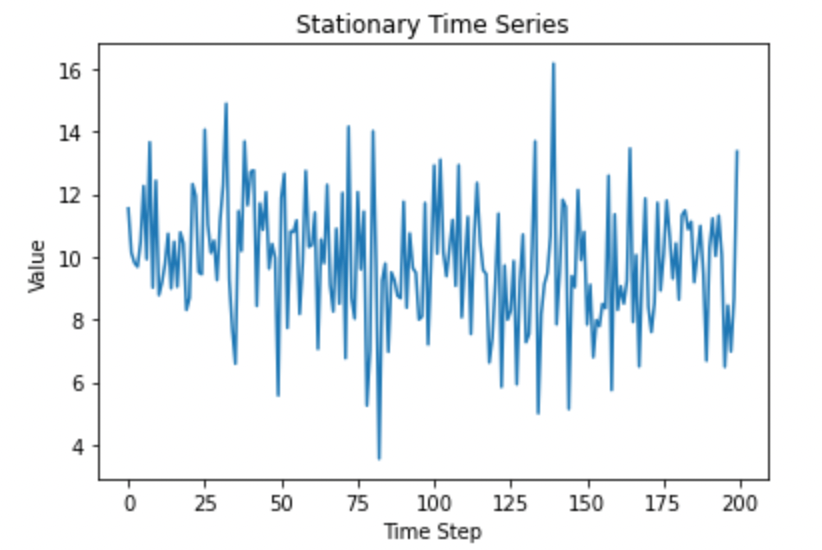
静止时间序列。图片由作者提供。
让我们将整个数据分为 4 部分,并计算每个部分的均值和方差:
subset_size = len(y) // 4
subsets = [y[i:i+subset_size] for i in range(0, len(y), subset_size)]
for i, subset in enumerate(subsets):
mean = np.mean(subset)
variance = np.var(subset)
print(f"Mean of subset {i + 1}: {round(mean,2)}")
print(f"Variance of subset {i + 1}: {round(variance,2)}")
"""
Mean of subset 1: 10.51
Variance of subset 1: 3.31
Mean of subset 2: 9.67
Variance of subset 2: 4.4
Mean of subset 3: 9.7
Variance of subset 3: 4.83
Mean of subset 4: 9.49
Variance of subset 4: 3.24
"""我将在下面提到分解,但现在让我们简单地检查季节性。
import numpy as np
import pandas as pd
from statsmodels.tsa.seasonal import seasonal_decompose
# convert the data into time series
date_rng = pd.date_range(start='1/1/2020', end='7/18/2020', freq='D')
y = pd.Series(y, date_rng)
# seasonal decomposition
result = seasonal_decompose(y, model='multiplicative')
result.plot()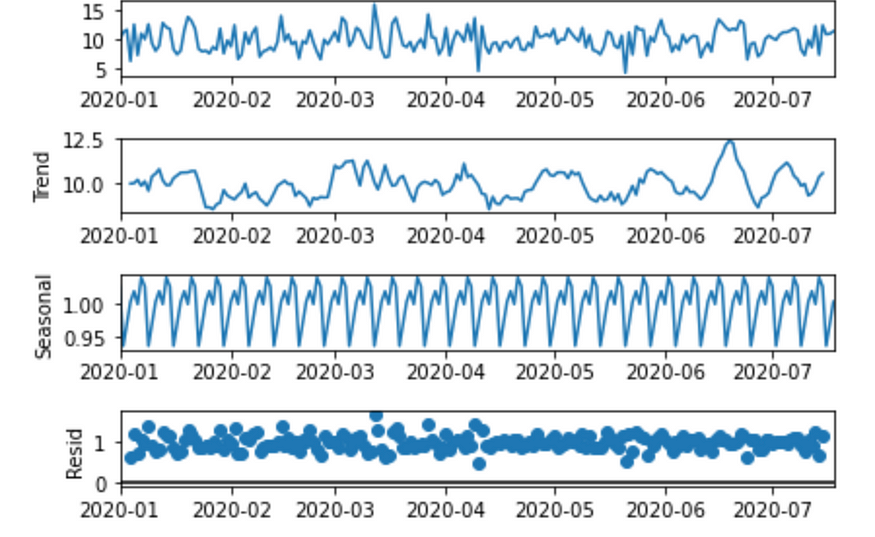
组件。图片由作者提供。
mean_seasonal = result.seasonal.mean()
std_seasonal = result.seasonal.std()
print(f'Mean of seasonal component: {round(mean_seasonal,2)}')
print(f'Standard deviation of seasonal component: {round(std_seasonal,2)}')
"""
Mean of seasonal component: 1.0
Standard deviation of seasonal component: 0.03
"""
非平稳行为。源
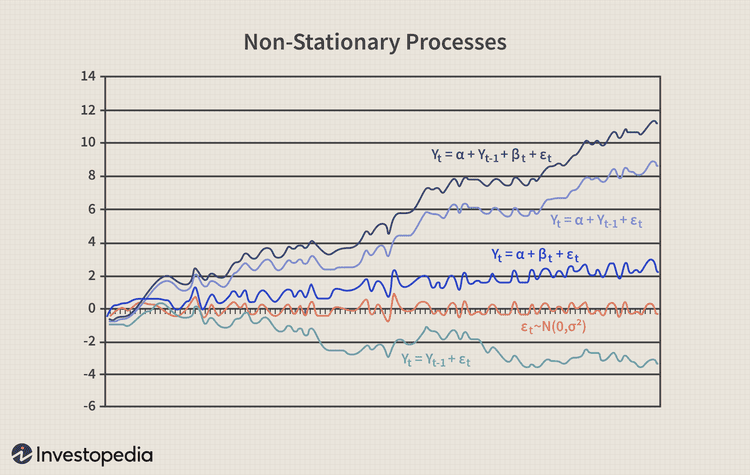
非平稳过程。源
4.2 为什么
我们为什么要费心在时间序列中寻找平稳性?
- 它们易于解释和建模。它们具有恒定的统计属性。因此,更容易对数据中的基础模式进行建模。
- 我在上面提到了外推。在外推中,预测更加困难。平稳时间序列更易于推断,并提供更有效的结果。
- 许多时间序列模型可以使用平稳时间序列(ARIMA 和其他线性时间序列模型)。
4.3 类型
我们有两种类型的平稳性:严格和弱。
弱(二阶)平稳性是我上面描述的。
另一方面,严格平稳性是指在不同时间序列的值在任何时间段内联合分布相同的时间序列。因此,该过程不依赖于任何时候的时间。所有时刻、期望值、方差、订单和其他统计属性在一段时间内都是恒定的。这是对平稳性的高度严格的定义,在实时时不太期望。
五、平稳性检测
有几种方法可以检测平稳性。最常见的是
- 澳大利亚国防军
- 轧制
- 金伯利坚
5.1 增强迪基-富勒测试 (ADF)
用于识别时间序列中平稳性的最常见统计检验。它是一种统计检验,通过检验时间序列为非平稳的原假设来检查平稳性。
He:非固定式; Ha:固定式
import pandas as pd
import matplotlib.pyplot as plt
n = 200 # data points
m = 10 # mean
var = 2 # variance
x = pd.date_range(start='2023-01-01', periods=n, freq='D')
y = np.random.normal(m,stddev, n)
# a stationary time series
ts_stationary = pd.Series(data=y, index=x)
# a non-stationary time series
y_non = np.array(range(n)) + y
ts_non = pd.Series(data=y_non, index=x)
平稳时间序列。图片由作者提供。
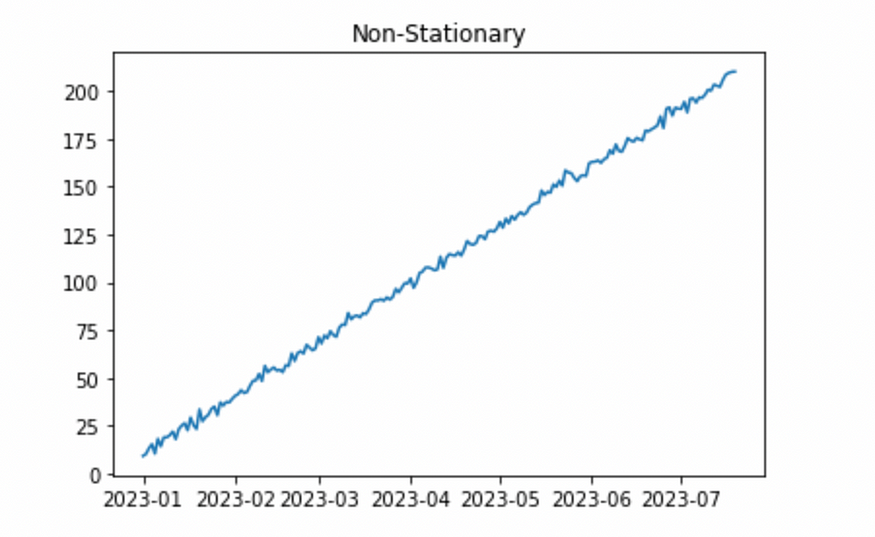
非平稳时间序列。图片由作者提供。
from statsmodels.tsa.stattools import adfuller
result = adfuller(ts_stationary)
print(result)
# (-6.741179365234232, 3.115993445779861e-09, 3, 196, {'1%': -3.464161278384219, '5%': -2.876401960790147, '10%': -2.5746921001665974}, 796.3640126365929)
print('ADF Statistic: %f' % result[0]) #-6.741179
print('p-value: %f' % result[1]) #0.000000
# Since the p-value is lower than 0.05 significance level,
# we can reject the null hypothesis and,
# this is stationary
result = adfuller(ts_non)
print('ADF Statistic: %f' % result[0]) #0.375390
print('p-value: %f' % result[1]) #0.980551
# Since the p-value is very high than 0.05
# we can accept the null hypothesis and
# this is not stationary.5.2 roll滚动
我们计算滚动统计数据并检查它们是否随时间发生显着变化。首先,我们定义一个窗口大小,然后计算平均值和方差,并检查它们是否随时间变化为常量(或接近常量)。
让我们滚动序列并绘制滚动均值和方差:
# rolling mean and variance
rolling_mean_s = ts_stationary.rolling(window=5).mean()
rolling_var_s = ts_stationary.rolling(window=5).var()
plt.plot(rolling_mean_s, label="Rolling Mean")
plt.plot(rolling_var_s, label="Rolling Variance")
plt.legend(loc="best")
plt.title("Rollings Stationary")
plt.show()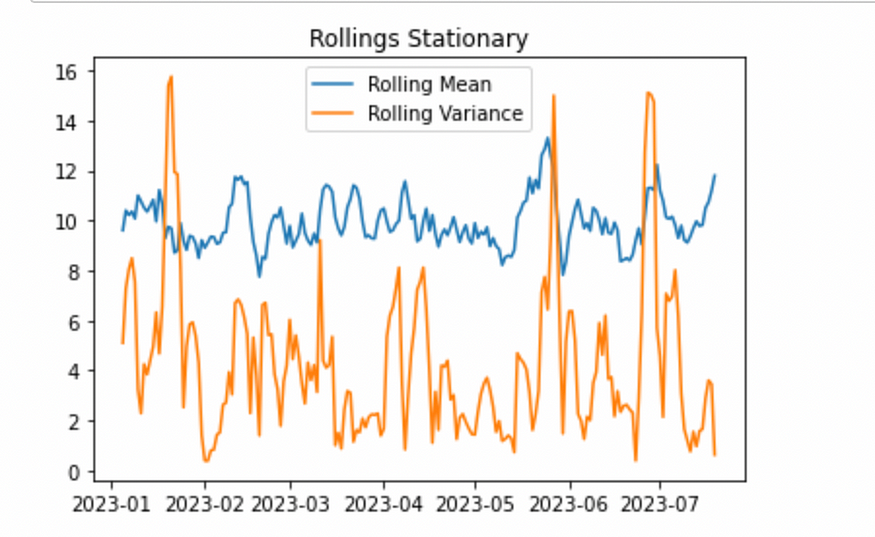
静止的滚动统计信息。图片由作者提供。

非平稳的滚动统计信息。图片由作者提供。
5.3 Kwiatkowski-Phillips-Schmidt-Shin Test (KPSS Test)
另一种统计测试基于将时间序列的属性与白噪声过程的属性进行比较,测试结果用于确定平稳性。
何:静止;Ha:非平稳
from statsmodels.tsa.stattools import kpss
# STATIONARY
result = kpss(ts_stationary, regression='c')
print('KPSS Statistic: %f' % result[0])
# KPSS Statistic: 0.162979
print('p-value: %f' % result[1])
# p-value: 0.100000
# Since the p-value is high than the significance level (0.05)
# we cannot reject the null hypothesis and
# it means that it is stationary
# NON-STATIONARY
result = kpss(ts_non, regression='c')
print('KPSS Statistic: %f' % result[0])
# KPSS Statistic: 1.358781
print('p-value: %f' % result[1])
# p-value: 0.010000
# Since the p-value is less than 0.05
# we can reject the null hypothesis and
# it means that it is non-stationary5.4 单位根
当静止过程受到冲击时,冲击的影响会随着时间的推移而减弱,系统恢复正常运行。然而,在非平稳过程中,冲击的影响是永久性的。
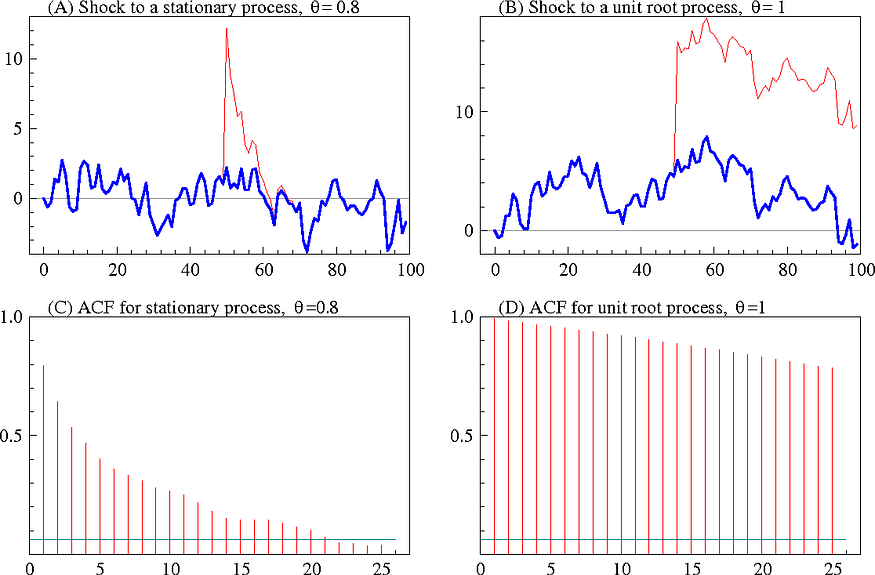
平稳时间序列和非平稳时间序列之间的差异。源
单位根是非平稳时间序列的特征,其中序列在干扰后倾向于返回其平均值,并且没有可预测的趋势。所以,我们也可以说,如果我们的时间序列有单位根,它就不是静止的。
我们有一个 AR(1) 模型:
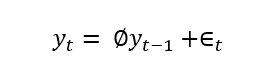
Φ 是 1 滞后的乘法系数。单位根是关于 Φ 的值。
我们可以将上述等式重写为序列的第一项和ε滞后版本的组合。这称为 MA 模型。
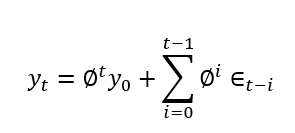
方差和期望值:
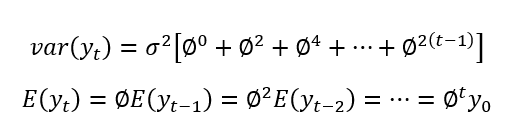
- 现在,让我们假设 |Φ| < 1:
当我们让 t 去无穷大时,Φ^t 将接近零,因此, 期望值将变为 E = 0。 随着时间的推移,它是恒定的。方差也将是恒定的。
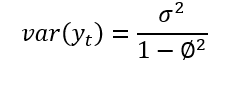
因此,我们可以说在这种情况下,我们的时间序列是静止的。
- |Φ| > 1:
在这种情况下,我们的时间序列会随着时间的推移而爆炸。因此,期望值 E 将收敛到 +- 无穷大。这使得这种情况是非静止的。
冲击作用对系统的影响随着时间的推移而增加。我们无法在现实生活中观察到这种系统。
- |Φ| = 1:
这是单位根情况,一种均匀的非平稳条件。期望值将是时间序列的第一个值 E (yt) = y0,并且它是常数。和差异:
![]()
随着时间的推移,方差会增加。由于方差不是恒定的,因此时间序列不是平稳的。
我们可以使用 Dickey-Fuller 检验检测时间序列中的单位根。
Ho:非静止; Ha:固定式 ( Ho: Non-stationary; Ha: stationary)
import numpy as np
import pandas as pd
import statsmodels.tsa.stattools as ts
# data with a unit root
y = np.random.randn(100).cumsum()
plt.plot(y)
plt.show()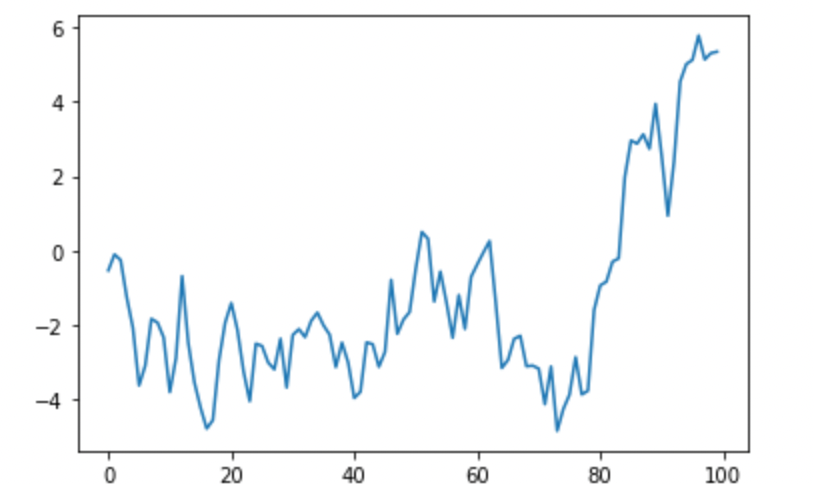
虚拟数据。图片由作者提供。
# Dickey-Fuller test
result = ts.adfuller(data)
print("Test Statistic: {:.4f}".format(result[0]))
print("p-value: {:.4f}".format(result[1]))
# check the p-value
if result[1] <= 0.05:
print("Rejecting the null hypothesis - Time series is stationary")
else:
print("Fail to reject the null hypothesis - Time series is not stationary")
"""
Test Statistic: -1.6213
p-value: 0.4721
Fail to reject the null hypothesis - Time series is not stationary
"""我们应用差分技术将单位根时间序列转换为信纸。
六、转型
好吧,如果我正在处理的时间序列数据不是静止的怎么办?那我该怎么办呢?非平稳时间序列可以设为平稳。有多种方法可以实现它。
- Differencing
- Decomposition
6.1 Differencing
我们取连续值序列的差值。假设我们的数据是 X = [x1, x2, x3, ...., xn],那么第一个区别是 ΔX = [nan, x2 — x1, x3 — x2, ..., xn — xn-1]。
通过差分,我们从序列中删除趋势分量。新系列变得更加静止。这就像删除数据的整体向上或向下方向,只留下围绕常数平均值的波动。

美国净发电量(十亿千瓦时)。其他面板在变换和差分后显示相同的数据。源
从前一个观测值中减去每个观测值的过程称为滞后 1 差值。对于具有季节性模式的时间序列,滞后通常设置为季节性周期的长度。
# lag-1
ts_non_lag1 = ts_non.diff(periods=1)
第一个滞后。图片由作者提供。
6.2 分解
在分解方法中,我们尝试将时间序列分解为三个组成部分:趋势、季节性和残差。我们可以隔离每一块。
分解时间序列后,可以进一步分析残差以确定它们是否平稳。如果残差是非平稳的,则可能需要进一步的预处理(例如差分或季节性分解)以使时间序列保持平稳。
添加剂分解
y_t = T_t + S_t + E_t
它通常用于时间序列相对稳定,没有大的波动或结构变化,并且非常适合对相对简单的时间序列模式进行建模和预测。
当季节性变化的大小(如每年同一时间发生的变化)随时间保持大致相同,并且残差分量(减去趋势和季节性后剩余的成分)不遵循任何模式并且是随机分布时,最好使用它。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import statsmodels.api as sm
# generated data
date_range = pd.date_range(start='01/01/2000', end='01/01/2022', freq='M')
value = np.random.randint(low=1000, high=2000, size=len(date_range)) + np.sin(np.linspace(0, 10 * np.pi, len(date_range))) * 300
data = pd.DataFrame({'value': value}, index=date_range)
# additive decomposition
result = sm.tsa.seasonal_decompose(data['value'], model='additive')
# plot
plt.figure(figsize=(10,7))
plt.subplot(411)
plt.plot(result.observed, label='observed')
plt.legend(loc='best')
plt.subplot(412)
plt.plot(result.trend, label='trend')
plt.legend(loc='best')
plt.subplot(413)
plt.plot(result.seasonal, label='seasonal')
plt.legend(loc='best')
plt.subplot(414)
plt.plot(result.resid, label='residual')
plt.legend(loc='best')
plt.tight_layout()
plt.show()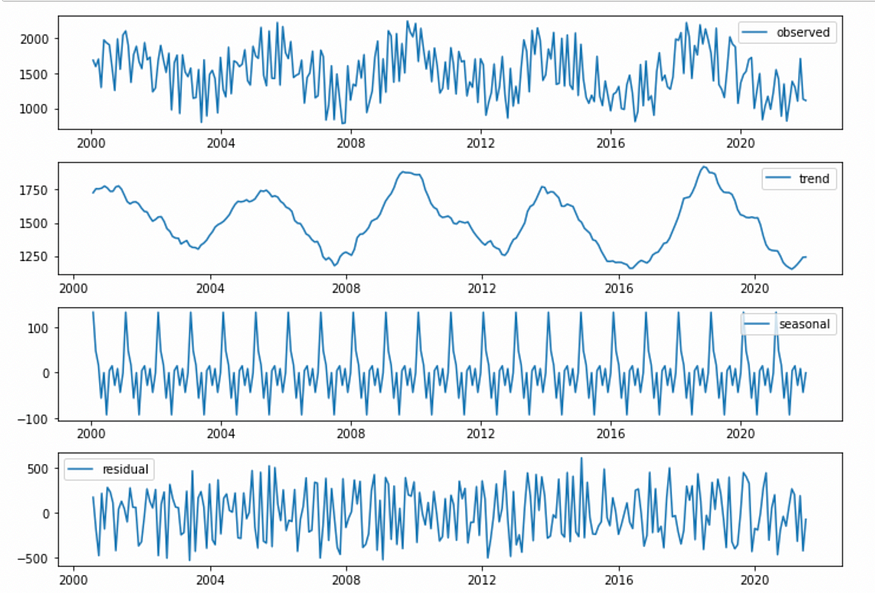
添加剂分解。图片由作者提供。
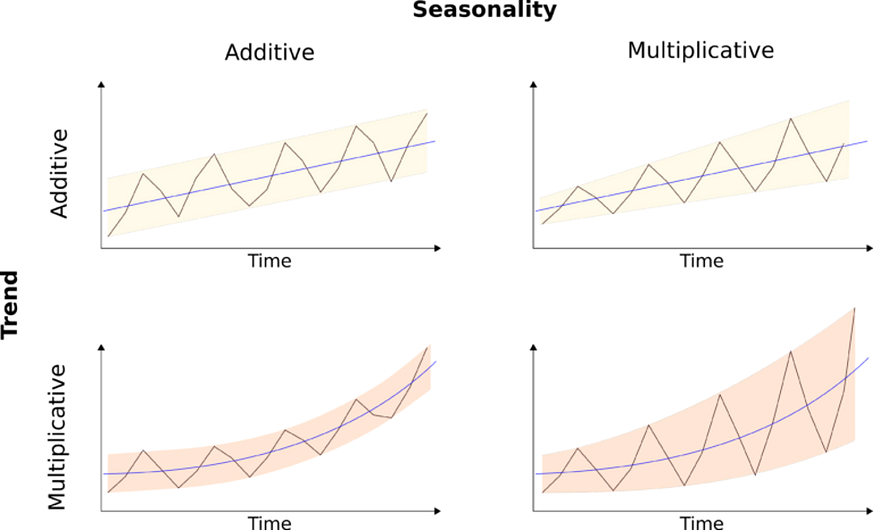
加法和乘法。源
乘法分解
y_t = T_t * S_t * E_t
它通常用于时间序列表现出非恒定增长或下降的情况,并且波动幅度与序列的大小成正比。
result = sm.tsa.seasonal_decompose(data['value'], model='multiplicative')季节性分解 (STL)
它涉及平滑和 LOESS 回归的组合,以将时间序列分为其季节性、趋势和残差分量。它的工作原理是首先将平滑曲线拟合到时间序列,然后删除该曲线以获得季节性分量。然后将该过程的残差与另一条平滑曲线拟合以获得趋势分量,并且该过程的残差被视为残差分量。
STL 分解对于分析具有强季节性模式和趋势的时间序列数据特别有用。
result = STL(data, period=12, seasonal=7, robust=True).fit()period指定每个周期的观测值数。例如,我的数据是每月一次,因此,我使用 12 作为期间。seasonal指定季节性窗口中的观测值数。此值会影响季节性分量的平滑度。较小的值表示更平滑的季节性分量,而较大的值则提供更锯齿状的分量。robust是设置稳健拟合的标志。稳健估计值是能够抵抗数据中异常值或极值影响的统计估计值。它通常用于数据包含异常值或极值的情况,这些异常值或极值会极大地影响传统估计方法(如平均值或回归)的结果。
plt.figure(figsize=(15, 10))
plt.subplot(411)
plt.plot(data, label='Original')
plt.legend(loc='best')
plt.subplot(412)
plt.plot(result.trend, label='Trend')
plt.legend(loc='best')
plt.subplot(413)
plt.plot(result.seasonal,label='Seasonality')
plt.legend(loc='best')
plt.subplot(414)
plt.plot(result.resid, label='Residuals')
plt.legend(loc='best')
plt.tight_layout()
plt.show()
STL 分解。图片由作者提供。
七、结论
这是一个漫长而疲惫的职位。这就是为什么我不会试图将所有信息融化在一个锅里,以延长它为代价。如果你要处理时间序列问题,平稳性是必须知道的主题之一。同时,这个主题包含不止一个概念。因此,您还应该了解这些概念。
请记住,平稳时间序列随时间推移具有恒定的统计属性,因此更容易建模和预测。然而,许多现实世界的时间序列是非平稳的,必须通过差分和分解等技术进行转换才能实现平稳性。理解平稳性的概念及其含义对于在金融、经济和工程等领域工作的人来说至关重要,在这些领域经常使用时间序列分析。奥坎·耶尼根