采样介绍
假如我们有一个多分类任务或者多标签分类任务,给定训练集
我们想学习到一个通用函数
完整的训练方法,如使用softmax或者Logistic回归需要对每个训练数据计算所有类
“candidate sampling”训练方法包括为每一个训练数据
TensorFlow中各种采样
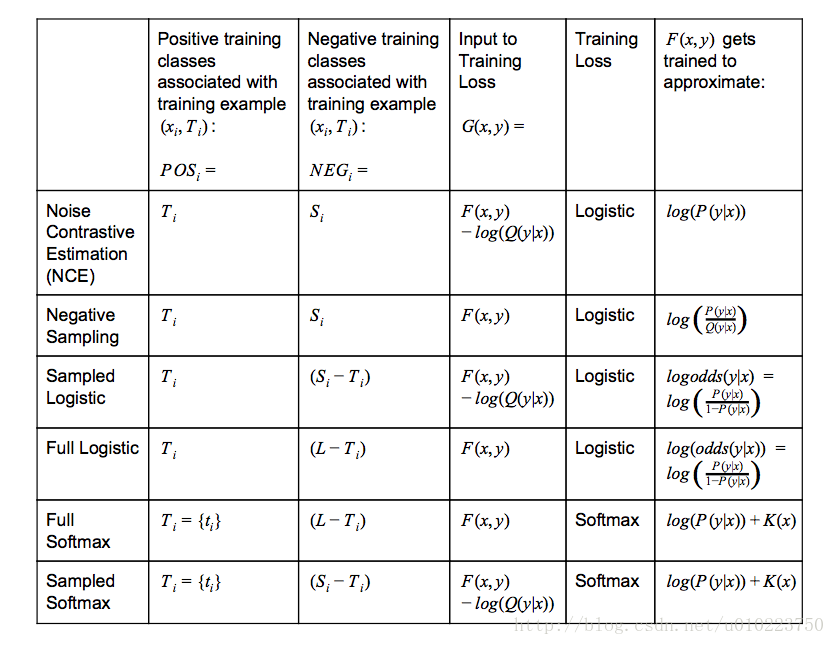
其中:
-
Q(y|x) 表示的是给定contextxi 采样到y 的概率 -
K(x) 表示任意不以来候选集的函数 -
logistic−training−loss=∑i(∑y∈POSilog(1+exp(−G(xi,y)))+∑y∈NEGilog(1+exp(G(xi,y))))(1) -
softmax−training−loss=∑i(−log(exp(G(xi,ti))∑y∈POSi∪NEGiexp(G(xi,y))))
softmax vs. logistic
在使用tensoflow的时候,我们有时候会纠结选择什么样的损失函数比较好,softmax和logistic在表达形式上是有点区别的,但是也不是很大,而且对于普通的softmax_cross_entropy_with_logits和sigmoid_cross_entropy_with_logits也都能够进行多分类任务,那么他们之间的区别是什么的?
就我个人所想到的,使用sigmoid_cross_entropy_with_logits和softmax_cross_entropy_with_logits的最大的区别是类别的排他性,在分类任务中,使用softmax_cross_entropy_with_logits我们一般是选择单个标签的分类,因为其具有排他性,说白了,softmax_cross_entropy_with_logits需要的是一个类别概率分布,其分布应该服从多项分布(也就是多项logistic regression),我们训练是让结果尽量靠近这种概率分布,不是说softmax_cross_entropy_with_logits不能进行多分,事实上,softmax_cross_entropy_with_logits是支持多个类别的,其参数labels也没有限制只使用一个类别,当使用softmax_cross_entropy_with_logits进行多分类时候,以二类为例,我们可以设置真实类别的对应labels上的位置是0.5,0.5,训练使得这个文本尽量倾向这种分布,在test阶段,可以选择两个计算概率最大的类作为类别标签,从这种角度说,使用softmax_cross_entropy_with_logits进行多分,实际上类似于计算文本的主题分布。
但是对于sigmoid_cross_entropy_with_logits,公式
tensorflow提供了下面两种candidate sample方法

- tf.nn.nce_loss
- tf.nn.sampled_softmax_loss
对比与之前讨论的,从最上面的图中的training loss采用的方法可以知道, tf.nn.nce_loss使用的是logistic 而tf.nn.sampled_softmax_loss采用的是softmax loss,其实这两者的区别也主要在这儿,采用logistic loss的本质上还是训练
个人看法,对于多标签多类别的分类任务使用Logistic比较好,对于多标签单类别的分类任务使用softmax比较好,采样中,采用tf.nn.sampled_softmax_loss训练cbow模型比较好,而 tf.nn.nce_loss训练skip-gram比较好。