Paper:Sampling Matters in Deep Embedding Learning
论文链接:https://arxiv.org/abs/1706.07567
开源代码:https://github.com/chaoyuaw/incubator-mxnet/tree/master/example/gluon/embedding_learning
在embedding learning中,除了损失函数如contrastive loss和triplet loss起很大作用外,采样策略也同样非常重要。
又是一篇ICCV 2017的文章。(最近看的好几篇都是2017的诶)
这篇paper提出了一个distance weighed sampling,选取信息量更大更稳定的训练样本。进一步,还提出了一个margin based loss。
Sampling
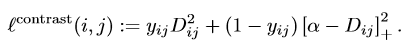
contrastive loss将正样本拉近,给负样本之间一个距离alpha。但是问题就在于:必须为每个负样本都选择一个余量alpha,在空间上并不够鲁棒。
![]()
triplet loss避免了这一点,仅要求正例的距离小于负例的距离。没有一个alpha参量的限制。
样本选择
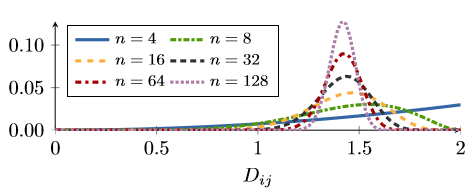
n维球面中,成对距离的分布如下:

并且在高维空间中,q(d)的近似为
因此,(1)对负样本均匀采样的话,很容易获得根号2以外地方的样本。
采样困难样本,负样本的梯度表现:
an之间的梯度如上,当加入噪声:

因此,(2)当有一定的噪声时候,很容易被噪声影响。这样非常影响训练。
Distance weighted sampling
作者提出了距离权重采样,采样公式如下:
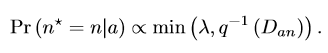
为了解决第一个问题,按q-1()采样。
对于第二个问题,加了一个裁剪。

不同采样策略的对比如上。可以看出,Distance weighted sampling能够采样到的样本更丰富。
Margin based loss

上图展示了作者提出的margin based loss。
其中,蓝色表示ap,绿色表示an。
图12是常见两种loss,c是给triplet开方,d是paper中的
其中,alpha控制margin,beta决定边界距离。
beta的组成:
beta(class)是样本偏置, beta(img)是类别偏置,beta(0)是人工定义的初始值。
Experiment
1、.采样方式的对比

在semi-hard中,contrastive和triplet表现相近
2、人脸识别对比

