训练一个神经网络意味着要输入训练样本并且不断调整神经元的权重,从而不断提高对目标的准确预测。每当神经网络经过一个训练样本的训练,它的权重就会进行一次调整。
所以,词典的大小决定了我们的Skip-Gram神经网络将会拥有大规模的权重矩阵,所有的这些权重需要通过数以亿计的训练样本来进行调整,这是非常消耗计算资源的,并且实际中训练起来会非常慢。
负采样(negative sampling)解决了这个问题,它是用来提高训练速度并且改善所得到词向量的质量的一种方法。不同于原本每个训练样本更新所有的权重,负采样每次让一个训练样本仅仅更新一小部分的权重,这样就会降低梯度下降过程中的计算量。
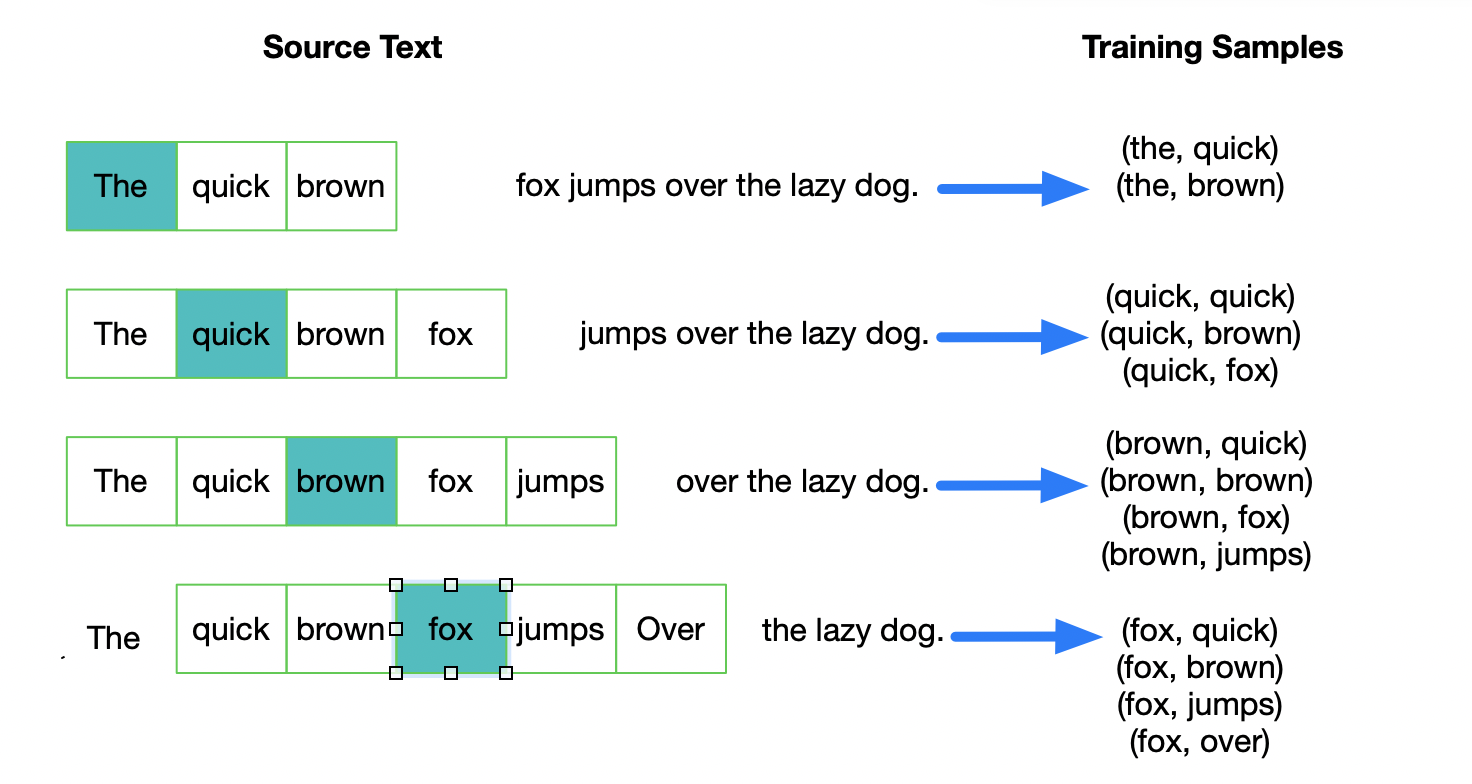
当我们用训练样本 ( input word: "fox",output word: "quick") 来训练我们的神经网络时,“ fox”和“quick”都是经过one-hot编码的。如果我们的词典大小为10000时,在输出层,我们期望对应“quick”单词的那个神经元结点输出1,其余9999个都应该输出0。在这里,这9999个我们期望输出为0的神经元结点所对应的单词我们称为“negative” word。
当使用负采样时,我们将随机选择一小部分的negative words(比如选5个negative words)来更新对应的权重。我们也会对我们的“positive” word进行权重更新(在我们上面的例子中,这个单词指的是”quick“)。
PS: 在论文中,作者指出指出对于小规模数据集,选择5-20个negative words会比较好,对于大规模数据集可以仅选择2-5个negative words。
我们使用“一元模型分布(unigram distribution)”来选择“negative words”。个单词被选作negative sample的概率跟它出现的频次有关,出现频次越高的单词越容易被选作negative words。
每个单词被选为“negative words”的概率计算公式:
![]()
其中 f(ωi)代表着单词出现的频次,而公式中开3/4的根号完全是基于经验的。
在代码负采样的代码实现中,unigram table有一个包含了一亿个元素的数组,这个数组是由词汇表中每个单词的索引号填充的,并且这个数组中有重复,也就是说有些单词会出现多次。那么每个单词的索引在这个数组中出现的次数该如何决定呢,有公式,也就是说计算出的负采样概率*1亿=单词在表中出现的次数。
有了这张表以后,每次去我们进行负采样时,只需要在0-1亿范围内生成一个随机数,然后选择表中索引号为这个随机数的那个单词作为我们的negative word即可。一个单词的负采样概率越大,那么它在这个表中出现的次数就越多,它被选中的概率就越大。