六、Dimensionality reduction
降维是减少所考虑的变量数量的过程。它可用于从原始和嘈杂的特征中提取潜在特征,或在保持结构的同时压缩数据。 spark.mllib为RowMatrix类提供了降维支持
singular value decomposition(SVD)
奇异值分解(SVD)将矩阵分解为三个矩阵:U,Σ和V,使得
A=UΣVT,
其中
- U是一个正交矩阵,其列称为左奇异向量;
- Σ 是具有非负对角线降序的对角矩阵,其对角线称为奇异值;
- V是一个正交矩阵,其列称为右奇异向量。
对于大型矩阵,通常不需要完整的因式分解,而仅需要顶部奇异值及其关联的奇异矢量。这样可以节省存储空间,降低噪声并恢复矩阵的低阶结构。
如果我们保留前k个奇异值,则所得的低秩矩阵的维将为:
U: m×k,
Σ: k×k,
V: n×k.
1)表现
我们假设n小于m。奇异值和右奇异向量是从Gramian矩阵ATA的特征值和特征向量得出的。如果用户通过computeU参数请求,则通过矩阵乘法将存储左奇异矢量U的矩阵计算为U = A(VS-1)。实际使用的方法是根据计算成本自动确定的:
- 如果n较小(n <100)或k与n相比较大(k> n / 2),我们首先计算Gramian矩阵,然后在驱动程序上局部计算其最高特征值和特征向量。这需要在每个执行器和驱动程序上进行一次O(n2)存储操作,并在驱动程序上进行O(n2k)时间处理。
- 否则,我们将以分布式方式计算(ATA)v并将其发送到ARPACK,以计算驱动程序节点上(ATA)的最高特征值和特征向量。这需要O(k)次传递,每个执行程序上的O(n)存储以及驱动程序上的O(nk)存储。
2)SVD示例
spark.mllib为RowMatrix类中提供的面向行的矩阵提供SVD功能。
import org.apache.spark.mllib.linalg.Matrix
import org.apache.spark.mllib.linalg.SingularValueDecomposition
import org.apache.spark.mllib.linalg.Vector
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.mllib.linalg.distributed.RowMatrix
val data = Array(
Vectors.sparse(5, Seq((1, 1.0), (3, 7.0))),
Vectors.dense(2.0, 0.0, 3.0, 4.0, 5.0),
Vectors.dense(4.0, 0.0, 0.0, 6.0, 7.0))
val rows = sc.parallelize(data)
val mat: RowMatrix = new RowMatrix(rows)
// Compute the top 5 singular values and corresponding singular vectors.
val svd: SingularValueDecomposition[RowMatrix, Matrix] = mat.computeSVD(5, computeU = true)
val U: RowMatrix = svd.U // The U factor is a RowMatrix.
val s: Vector = svd.s // The singular values are stored in a local dense vector.
val V: Matrix = svd.V // The V factor is a local dense matrix.
principal component analysis(PCA)
主成分分析(PCA)是一种统计方法,用于查找旋转,以使第一个坐标具有最大的方差,而每个后续坐标又具有最大的方差。旋转矩阵的列称为主成分。 PCA被广泛用于降维。
spark.mllib支持以行定向格式和任何向量存储的高而瘦的矩阵的PCA。
示例代码
以下代码演示了如何在RowMatrix上计算主要成分并将其用于将向量投影到低维空间中。
有关API的详细信息,请参考RowMatrix Scala文档。
import org.apache.spark.mllib.linalg.Matrix
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.mllib.linalg.distributed.RowMatrix
val data = Array(
Vectors.sparse(5, Seq((1, 1.0), (3, 7.0))),
Vectors.dense(2.0, 0.0, 3.0, 4.0, 5.0),
Vectors.dense(4.0, 0.0, 0.0, 6.0, 7.0))
val rows = sc.parallelize(data)
val mat: RowMatrix = new RowMatrix(rows)
// Compute the top 4 principal components.
// Principal components are stored in a local dense matrix.
val pc: Matrix = mat.computePrincipalComponents(4)
// Project the rows to the linear space spanned by the top 4 principal components.
val projected: RowMatrix = mat.multiply(pc)
有关API的详细信息,请参考PCA Scala文档。
import org.apache.spark.mllib.feature.PCA
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.mllib.regression.LabeledPoint
import org.apache.spark.rdd.RDD
val data: RDD[LabeledPoint] = sc.parallelize(Seq(
new LabeledPoint(0, Vectors.dense(1, 0, 0, 0, 1)),
new LabeledPoint(1, Vectors.dense(1, 1, 0, 1, 0)),
new LabeledPoint(1, Vectors.dense(1, 1, 0, 0, 0)),
new LabeledPoint(0, Vectors.dense(1, 0, 0, 0, 0)),
new LabeledPoint(1, Vectors.dense(1, 1, 0, 0, 0))))
// Compute the top 5 principal components.
val pca = new PCA(5).fit(data.map(_.features))
// Project vectors to the linear space spanned by the top 5 principal
// components, keeping the label
val projected = data.map(p => p.copy(features = pca.transform(p.features)))
七、Feature Extraction and Transformation
TF-IDF
注意我们建议您使用基于DataFrame的API,这在TF-IDF的ML用户指南中有详细介绍。
术语频率逆文档频率(TF-IDF)是一种特征向量化方法,广泛用于文本挖掘中,以反映术语对语料库中文档的重要性。用t表示项,用d表示文档,用D表示语料。术语频率TF(t,d)是术语t在文档d中出现的次数,而文档频率DF(t,D)是数字包含术语t的文档。如果我们仅使用术语频率来衡量重要性,则很容易过分强调那些经常出现但几乎没有有关文档信息的术语,例如“一个”,“该”和“属于”。如果术语在整个语料库中经常出现,则表示该术语不包含有关特定文档的特殊信息。反向文档频率是一个术语提供多少信息的数字度量:
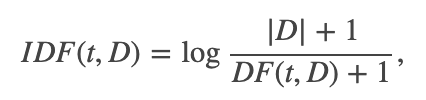
| D |是语料库中文档的总数。由于使用对数,因此如果一个术语出现在所有文档中,则其IDF值将变为0。请注意,应用了平滑术语以避免对主体外的术语除以零。 TF-IDF度量只是TF和IDF的乘积:
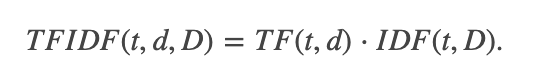
术语频率和文档频率的定义有几种变体。在spark.mllib中,我们将TF和IDF分开以使其具有灵活性。我们对词频的实现利用了哈希技巧。通过应用哈希函数将原始特征映射到索引(项)。然后根据映射的索引计算词频。这种方法避免了需要计算全局项到索引图的情况,这对于大型语料库可能是昂贵的,但是它会遭受潜在的哈希冲突,即哈希后不同的原始特征可能变成相同的术语。为了减少冲突的机会,我们可以增加目标要素的维数,即哈希表的存储桶数。默认特征尺寸为2^20 = 1,048,576。
注意:spark.mllib不提供文本分割工具。我们将用户推荐给Stanford NLP Group和scalanlp / chalk。
示例代码
import org.apache.spark.mllib.feature.{HashingTF, IDF}
import org.apache.spark.mllib.linalg.Vector
import org.apache.spark.rdd.RDD
// Load documents (one per line).
val documents: RDD[Seq[String]] = sc.textFile("data/mllib/kmeans_data.txt")
.map(_.split(" ").toSeq)
val hashingTF = new HashingTF()
val tf: RDD[Vector] = hashingTF.transform(documents)
// While applying HashingTF only needs a single pass to the data, applying IDF needs two passes:
// First to compute the IDF vector and second to scale the term frequencies by IDF.
tf.cache()
val idf = new IDF().fit(tf)
val tfidf: RDD[Vector] = idf.transform(tf)
// spark.mllib IDF implementation provides an option for ignoring terms which occur in less than
// a minimum number of documents. In such cases, the IDF for these terms is set to 0.
// This feature can be used by passing the minDocFreq value to the IDF constructor.
val idfIgnore = new IDF(minDocFreq = 2).fit(tf)
val tfidfIgnore: RDD[Vector] = idfIgnore.transform(tf)
Word2Vec
Word2Vec计算单词的分布式矢量表示。分布式表示的主要优点是在向量空间中相似的词很接近,这使得对新颖模式的泛化更加容易,并且模型估计更加可靠。分布式矢量表示被证明在许多自然语言处理应用程序中很有用,例如命名实体识别,歧义消除,解析,标记和机器翻译。
1)模型
在Word2Vec的实现中,我们使用了跳过语法模型。跳过语法的训练目标是学习能够很好地预测同一句子中上下文的单词向量表示。从数学上讲,给定一系列训练词w1,w2,…,wT,跳过语法模型的目的是使平均对数似然性最大化

示例代码
下面的示例演示如何加载文本文件,将其解析为Seq [String]的RDD,构造Word2Vec实例,然后使用输入数据拟合Word2VecModel。最后,我们显示指定单词的前40个同义词。要运行该示例,请首先下载text8数据并将其提取到您的首选目录中。在这里,我们假设提取的文件是text8,并且与您运行spark shell时在同一目录中。
import org.apache.spark.mllib.feature.{Word2Vec, Word2VecModel}
val input = sc.textFile("data/mllib/sample_lda_data.txt").map(line => line.split(" ").toSeq)
val word2vec = new Word2Vec()
val model = word2vec.fit(input)
val synonyms = model.findSynonyms("1", 5)
for((synonym, cosineSimilarity) <- synonyms) {
println(s"$synonym $cosineSimilarity")
}
// Save and load model
model.save(sc, "myModelPath")
val sameModel = Word2VecModel.load(sc, "myModelPath")
StandardScaler
通过缩放到单位方差和/或使用训练集中样本上的列摘要统计信息去除均值来对特征进行标准化。这是非常常见的预处理步骤。
例如,当所有特征均具有单位方差和/或均值为零时,支持向量机的RBF内核或L1和L2正则化线性模型通常会更好地工作。标准化可以提高优化过程中的收敛速度,还可以防止差异很大的特征在模型训练期间产生过大的影响。
1)模型拟合
StandardScaler在构造函数中具有以下参数:
- withMean:默认为False。在缩放之前,将数据以均值居中。它将生成密集的输出,因此在应用于稀疏输入时要小心。
- withStd:默认为True。将数据缩放到单位标准偏差。
我们在StandardScaler中提供了一个拟合方法,该方法可以获取RDD [Vector]的输入,学习汇总统计信息,然后返回一个模型,该模型可以将输入数据集转换为单位标准差和/或零均值特征,具体取决于我们如何配置StandardScaler 。
此模型实现VectorTransformer,可以将标准化应用到Vector上以生成转换后的Vector或在RDD [Vector]上生成转换的RDD [Vector]。
请注意,如果要素的方差为零,它将在向量中返回该要素的默认0.0值。
示例代码
import org.apache.spark.mllib.feature.{StandardScaler, StandardScalerModel}
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.mllib.util.MLUtils
val data = MLUtils.loadLibSVMFile(sc, "data/mllib/sample_libsvm_data.txt")
val scaler1 = new StandardScaler().fit(data.map(x => x.features))
val scaler2 = new StandardScaler(withMean = true, withStd = true).fit(data.map(x => x.features))
// scaler3 is an identical model to scaler2, and will produce identical transformations
val scaler3 = new StandardScalerModel(scaler2.std, scaler2.mean)
// data1 will be unit variance.
val data1 = data.map(x => (x.label, scaler1.transform(x.features)))
// data2 will be unit variance and zero mean.
val data2 = data.map(x => (x.label, scaler2.transform(Vectors.dense(x.features.toArray))))
Normalizer
归一化器将单个样本缩放为单位Lp范数。这是文本分类或聚类的常用操作。例如,两个L2归一化TF-IDF向量的点积是向量的余弦相似度。
规范化器在构造函数中具有以下参数:
- p Lp空间中的归一化,默认情况下p = 2。
规范化器实现了VectorTransformer,可以将规范化应用到Vector上以生成转换后的Vector或在RDD [Vector]上生成转换后的RDD [Vector]。
请注意,如果输入范数为零,则它将返回输入向量。
示例代码
import org.apache.spark.mllib.feature.Normalizer
import org.apache.spark.mllib.util.MLUtils
val data = MLUtils.loadLibSVMFile(sc, "data/mllib/sample_libsvm_data.txt")
val normalizer1 = new Normalizer()
val normalizer2 = new Normalizer(p = Double.PositiveInfinity)
// Each sample in data1 will be normalized using $L^2$ norm.
val data1 = data.map(x => (x.label, normalizer1.transform(x.features)))
// Each sample in data2 will be normalized using $L^\infty$ norm.
val data2 = data.map(x => (x.label, normalizer2.transform(x.features)))
ChiSqSelector
特征选择试图识别用于模型构建的相关特征。它减小了特征空间的大小,从而可以提高速度和统计学习行为。
ChiSqSelector实现Chi-Squared特征选择。它对具有分类特征的标记数据进行操作。 ChiSqSelector使用卡方独立性检验来决定选择哪些功能。它支持五种选择方法:numTopFeatures,percentile,fpr,fdr,fwe:
- numTopFeatures 根据卡方检验选择固定数量的顶部特征。这类似于产生具有最大预测能力的特征。
- percentile 与numTopFeatures相似,但是选择所有功能的一部分而不是固定数量。
- fpr 选择p值低于阈值的所有特征,从而控制选择的误报率。
- fdr 使用Benjamini-Hochberg过程选择错误发现率低于阈值的所有特征。
- fwe 选择p值低于阈值的所有特征。阈值按1 / numFeatures缩放,从而控制族的选择错误率。
默认情况下,选择方法为numTopFeatures,顶部要素的默认数量设置为50。用户可以使用setSelectorType选择选择方法。可以使用保留的验证集来调整要选择的功能的数量。
1)模型拟合
fit方法采用具有分类特征的RDD [LabeledPoint]输入,学习摘要统计信息,然后返回ChiSqSelectorModel,它可以将输入数据集转换为精简特征空间。 ChiSqSelectorModel既可以应用于向量以生成简化的矢量,也可以应用于RDD [Vector]以生成简化的RDD [Vector]。
请注意,用户还可以通过提供一组选定要素索引(必须按升序排序)来手动构建ChiSqSelectorModel。
code example
import org.apache.spark.mllib.feature.ChiSqSelector
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.mllib.regression.LabeledPoint
import org.apache.spark.mllib.util.MLUtils
// Load some data in libsvm format
val data = MLUtils.loadLibSVMFile(sc, "data/mllib/sample_libsvm_data.txt")
// Discretize data in 16 equal bins since ChiSqSelector requires categorical features
// Even though features are doubles, the ChiSqSelector treats each unique value as a category
val discretizedData = data.map { lp =>
LabeledPoint(lp.label, Vectors.dense(lp.features.toArray.map { x => (x / 16).floor }))
}
// Create ChiSqSelector that will select top 50 of 692 features
val selector = new ChiSqSelector(50)
// Create ChiSqSelector model (selecting features)
val transformer = selector.fit(discretizedData)
// Filter the top 50 features from each feature vector
val filteredData = discretizedData.map { lp =>
LabeledPoint(lp.label, transformer.transform(lp.features))
}
ElementwiseProduct
ElementwiseProduct使用逐元素乘法将每个输入向量乘以提供的“权重”向量。换句话说,它通过标量乘法器缩放数据集的每一列。这表示输入向量v和转换向量scaleVec之间的Hadamard乘积,以产生结果向量。
将scalingVec表示为“ w”,此转换可以写为:
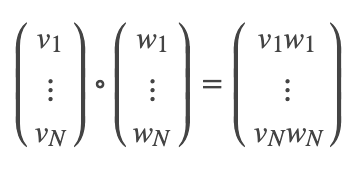
ElementwiseProduct在构造函数中具有以下参数:
- scalingVec: 转换向量
ElementwiseProduct实现VectorTransformer,可以将权重应用于Vector来生成转换后的Vector或在RDD [Vector]上生成转换后的RDD [Vector]。
import org.apache.spark.mllib.feature.ElementwiseProduct
import org.apache.spark.mllib.linalg.Vectors
// Create some vector data; also works for sparse vectors
val data = sc.parallelize(Array(Vectors.dense(1.0, 2.0, 3.0), Vectors.dense(4.0, 5.0, 6.0)))
val transformingVector = Vectors.dense(0.0, 1.0, 2.0)
val transformer = new ElementwiseProduct(transformingVector)
// Batch transform and per-row transform give the same results:
val transformedData = transformer.transform(data)
val transformedData2 = data.map(x => transformer.transform(x))
PCA
使用PCA将向量投影到低维空间的特征转换器。您可以在降维时阅读的详细信息。
code example
import org.apache.spark.mllib.feature.PCA
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.mllib.regression.{LabeledPoint, LinearRegressionWithSGD}
val data = sc.textFile("data/mllib/ridge-data/lpsa.data").map { line =>
val parts = line.split(',')
LabeledPoint(parts(0).toDouble, Vectors.dense(parts(1).split(' ').map(_.toDouble)))
}.cache()
val splits = data.randomSplit(Array(0.6, 0.4), seed = 11L)
val training = splits(0).cache()
val test = splits(1)
val pca = new PCA(training.first().features.size / 2).fit(data.map(_.features))
val training_pca = training.map(p => p.copy(features = pca.transform(p.features)))
val test_pca = test.map(p => p.copy(features = pca.transform(p.features)))
val numIterations = 100
val model = LinearRegressionWithSGD.train(training, numIterations)
val model_pca = LinearRegressionWithSGD.train(training_pca, numIterations)
val valuesAndPreds = test.map { point =>
val score = model.predict(point.features)
(score, point.label)
}
val valuesAndPreds_pca = test_pca.map { point =>
val score = model_pca.predict(point.features)
(score, point.label)
}
val MSE = valuesAndPreds.map { case (v, p) => math.pow((v - p), 2) }.mean()
val MSE_pca = valuesAndPreds_pca.map { case (v, p) => math.pow((v - p), 2) }.mean()
println(s"Mean Squared Error = $MSE")
println(s"PCA Mean Squared Error = $MSE_pca")
