版权声明:本文为博主原创文章,未经博主允许不得转载。http://blog.csdn.net/aspirinvagrant https://blog.csdn.net/fenghuangdesire/article/details/52006460
权重更新
MLlib采用如下方式更新模型(LR、SVM、线性回归等)的权重:
逻辑回归(LR)回顾
Logistic regression是机器学习常用的分类模型,用于将不同样本分开。本文的重点不在Logistic regression的细节,关于Logistic regression的具体原理和公式推导请参考zuoxy09的博文—— 机器学习算法与Python实践之(七)逻辑回归(Logistic Regression)。
接下来给出Logistic regression的cost function:
使用梯度下降(Gradient Descent),对
对于梯度下降的方法,请参考—— 随机梯度下降与批量梯度下降。
对上面的式子做如下变换:
并行的梯度下降
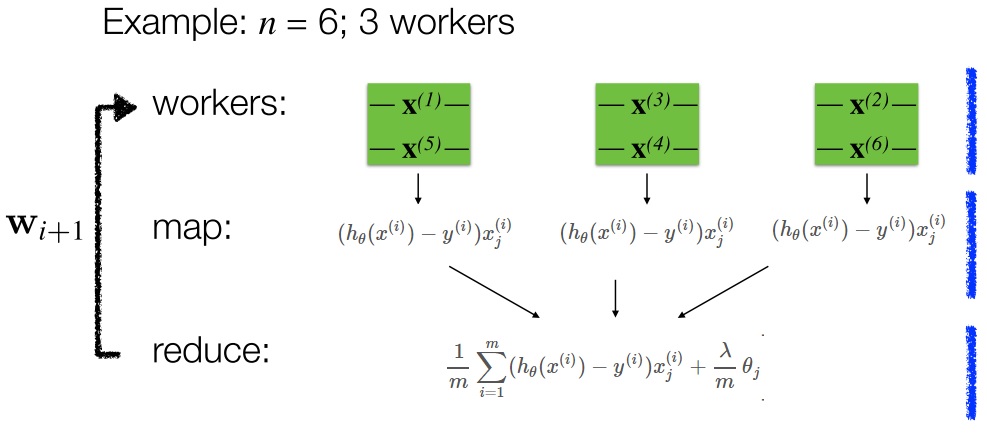
其中:
map函数计算每个点的梯度:
reduce函数计算所有点的梯度求和以及正则项:
Mlib源码分析
Logistic regression利用梯度下降求解参数
GradientDescent#runMiniBatchSGD方法中,包括两部分
/**
*
* @param data 样本数据RDD,格式 (label, [features])
* @param gradient 对应LogisticGradient,用于计算每个样本梯度及误差
* @param updater 对应SquaredL2Updater, 用于每次更新权重
* @param stepSize 初始步长
* @param numIterations 迭代次数
* @param regParam 正则化因子
* @param miniBatchFraction 每次迭代参与计算的样本比例
* @param convergenceTol 迭代前后的变化,小于某个阈值停止迭代
* @return (Vector, Array[Double]) 第一个为权重,每二个为每次迭代的误差值
*/
def runMiniBatchSGD(
data: RDD[(Double, Vector)],
gradient: Gradient,
updater: Updater,
stepSize: Double,
numIterations: Int,
regParam: Double,
miniBatchFraction: Double,
initialWeights: Vector,
convergenceTol: Double): (Vector, Array[Double]) = {
// 误差变化历史记录
val stochasticLossHistory = new ArrayBuffer[Double](numIterations)
// Record previous weight and current one to calculate solution vector difference
var previousWeights: Option[Vector] = None
var currentWeights: Option[Vector] = None
val numExamples = data.count()
// Initialize weights as a column vector
var weights = Vectors.dense(initialWeights.toArray)
val n = weights.size
// 第一次迭代初始化正则因子
var regVal = updater.compute(
weights, Vectors.zeros(weights.size), 0, 1, regParam)._2
// indicates whether converged based on convergenceTol
var converged = false
var i = 1
while (!converged && i <= numIterations) {
val bcWeights = data.context.broadcast(weights)
// Sample a subset (fraction miniBatchFraction) of the total data
// compute and sum up the subgradients on this subset (this is one map-reduce)
// treeAggregate的使用请参考http://stackoverflow.com/questions/29860635/how-to-interpret-rdd-treeaggregate
// 计算梯度和误差
val (gradientSum, lossSum, miniBatchSize) = data.sample(false, miniBatchFraction, 42 + i)
.treeAggregate((BDV.zeros[Double](n), 0.0, 0L))(
seqOp = (c, v) => {
// c: (grad, loss, count), v: (label, features)
val loss = gradient.compute(v._2, v._1, bcWeights.value, Vectors.fromBreeze(c._1))
(c._1, c._2 + loss, c._3 + 1)
},
combOp = (c1, c2) => {
// c: (grad, loss, count)
(c1._1 += c2._1, c1._2 + c2._2, c1._3 + c2._3)
})
if (miniBatchSize > 0) {
stochasticLossHistory.append(lossSum / miniBatchSize + regVal)
// 更新梯度
val update = updater.compute(
weights, Vectors.fromBreeze(gradientSum / miniBatchSize.toDouble),
stepSize, i, regParam)
weights = update._1
regVal = update._2
previousWeights = currentWeights
currentWeights = Some(weights)
if (previousWeights != None && currentWeights != None) {
converged = isConverged(previousWeights.get,
currentWeights.get, convergenceTol)
}
} else {
logWarning(s"Iteration ($i/$numIterations). The size of sampled batch is zero")
}
i += 1
}
(weights, stochasticLossHistory.toArray)
}上面方法中包含两部分:
1、 计算梯度gradient.compute
override def compute(
data: Vector,
label: Double,
weights: Vector,
cumGradient: Vector): Double = {
val dataSize = data.size
val margin = -1.0 * dot(data, weights)
// 公式(2)中求和部分
val multiplier = (1.0 / (1.0 + math.exp(margin))) - label
// cumGradient为当前累计求和后的梯度
// cumGradient += multiplier * data
axpy(multiplier, data, cumGradient)
// 误差
if (label > 0) {
// The following is equivalent to log(1 + exp(margin)) but more numerically stable.
MLUtils.log1pExp(margin)
} else {
MLUtils.log1pExp(margin) - margin
}
}2、 更新权重updater.compute
override def compute(
weightsOld: Vector,
gradient: Vector,
stepSize: Double,
iter: Int,
regParam: Double): (Vector, Double) = {
// 本次迭代步长alpha
val thisIterStepSize = stepSize / math.sqrt(iter)
// 根据公式(3)计算权重,brzWeights为当前权重theta
val brzWeights: BV[Double] = weightsOld.toBreeze.toDenseVector
// :* 为向量scalar计算
brzWeights :*= (1.0 - thisIterStepSize * regParam)
// brzWeights += -thisIterStepSize * gradient
brzAxpy(-thisIterStepSize, gradient.toBreeze, brzWeights)
// 正则项
val norm = brzNorm(brzWeights, 2.0)
(Vectors.fromBreeze(brzWeights), 0.5 * regParam * norm * norm)
}线性SVM
cost function:
注:
使用梯度下降(Gradient Descent),对
关于SVM参数计算推导见 这里。