1.CNN概念理解
1.1二维平面的卷积操作
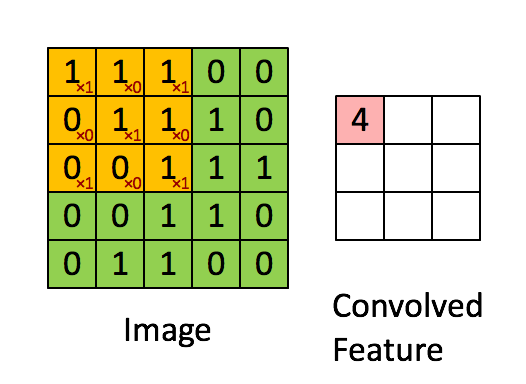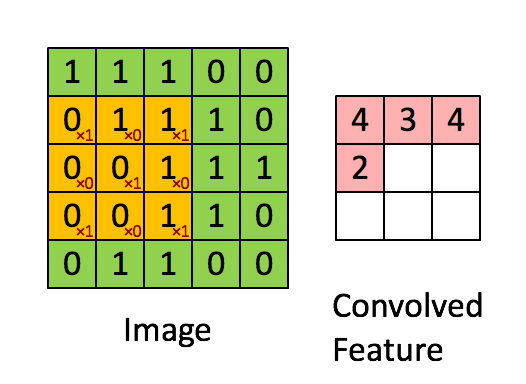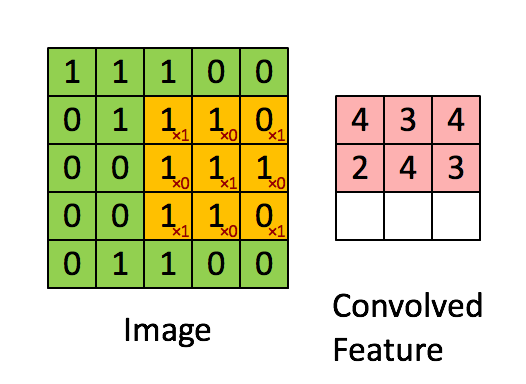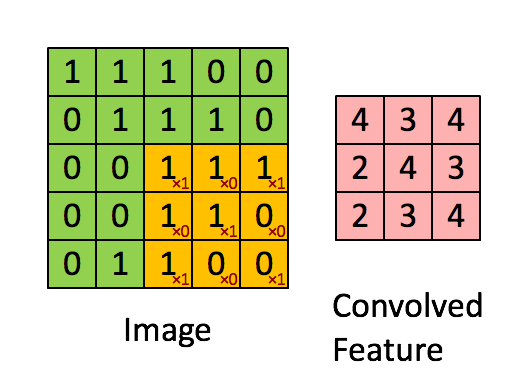
下图Image表示一幅图片,有颜色填充的网格表示一个卷积核,卷积核的大小为3*3。假设我们做步长为1的卷积操作,表示卷积核每次向右移动一个像素(当移动到边界时回到最左端并向下移动一个单位)。卷积核每个单元内有权重,下图的卷积核内有9个权重。在卷积核移动的过程中将图片上的像素和卷积核的对应权重相乘,最后将所有乘积相加得到一个名为Convolved Feature的
输出。
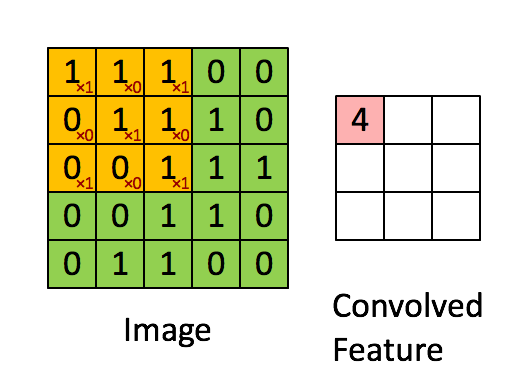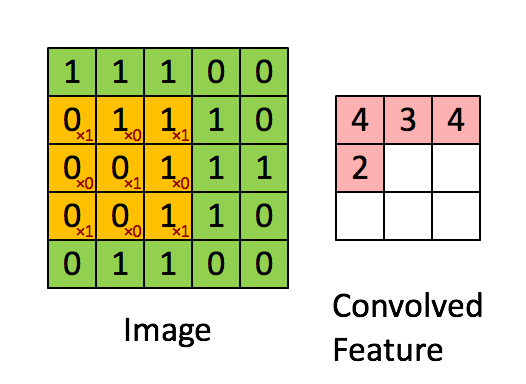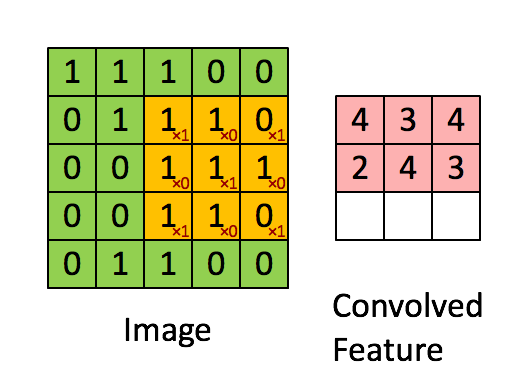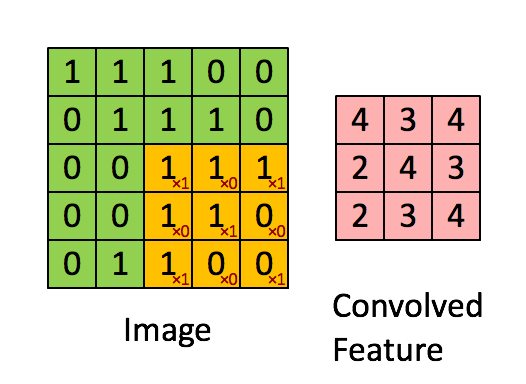
1.2被卷积矩阵的深度
卷积操作在二维平面上很好理解,但在CNN中,被卷积的图像(矩阵)是有深度的:

该深度可以类比彩色图像的RGB三通道进行理解,因此被卷积矩阵的维度是:depth*height*width.对有深度的矩阵进行卷积操作可以理解为二维卷积操作在所有深度上同时进行.
1.3局部感知
在传统神经网络中每个神经元都要与图片上每个像素相连接,这样的话就会造成权重的数量巨大造成网络难以训练。而在含有卷积层的的神经网络中每个神经元的权重个数都是卷积核的大小,这样就相当于每个神经元只与对应图片部分的像素相连接,极大的减少了权重的数量。同时我们可以设置卷积操作的步长,假设将上图卷积操作的步长设置为3时每次卷积都不会有重叠区域(在超出边界的部分补自定义的值)。局部感知的直观感受如下图:

使用局部感知的原因在于图片中相邻区域具有更大的相关性,距离较远时相关性也较小.
1.4参数共享
卷积核的权重通过学习得到且在卷积过程中卷积核的权重不会改变,这是参数共享的思想。说明我们通过一个卷积核的操作提取了原图的不同位置的同样(类似)特征。简单来说就是在一幅图片中的不同位置的相同目标,它们的特征是基本相同的。其过程如下图:
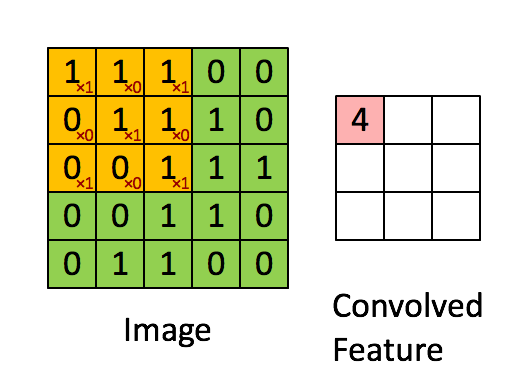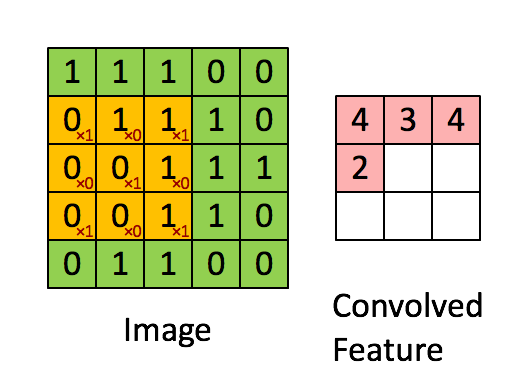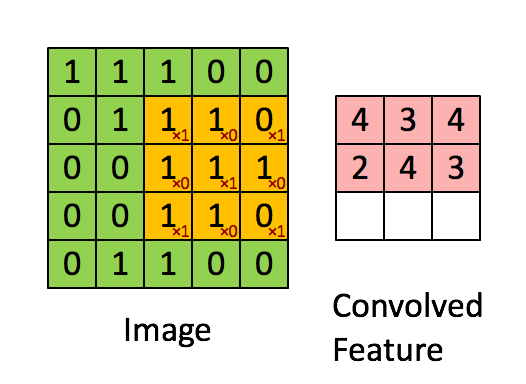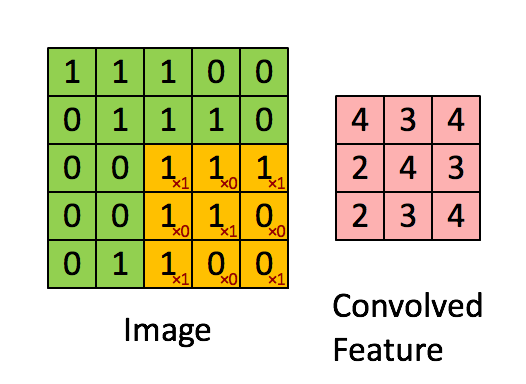
1.5多核卷积
权值共享部分给我们启发:用一个卷积核操作只能得到一部分特征可能获取不到全部特征,这时候就必须引入多核卷积来尽可能多得获取图像矩阵的全部特征,即每个卷积核学习不同特征(每个卷积核学习到不同的权重)来提取原图特征。
上图的图片经过三个卷积核的卷积操作得到三个特征图。需要注意的是,在多核卷积的过程中每个卷积核的大小应该是相同的。

上图的图片经三个卷积核的卷积操作得到三个特征图(每个特征图体现原图不同特征)。
注意:在多核卷积过程中每个卷积核大小应保持一致。
2.下采样层(池化)
在卷积神经网络中,我们经常会碰到池化操作,池化不同于卷积操作(作用于图像的不同区域).池化层往往在卷积层后面,通过池化来降低卷积层输出的特征向量,同时改善结果(不易出现过拟合)。
为什么可以通过降低维度呢?
因为图像具有一种“静态性”的属性,这也就意味着在一个图像区域有用的特征极有可能在另一个区域同样适用。因此,为了描述大的图像,一个很自然的想法就是对不同位置的特征进行聚合统计,例如,人们可以计算图像一个区域上的某个特定特征的平均值 (或最大值)来代表这个区域的特征。
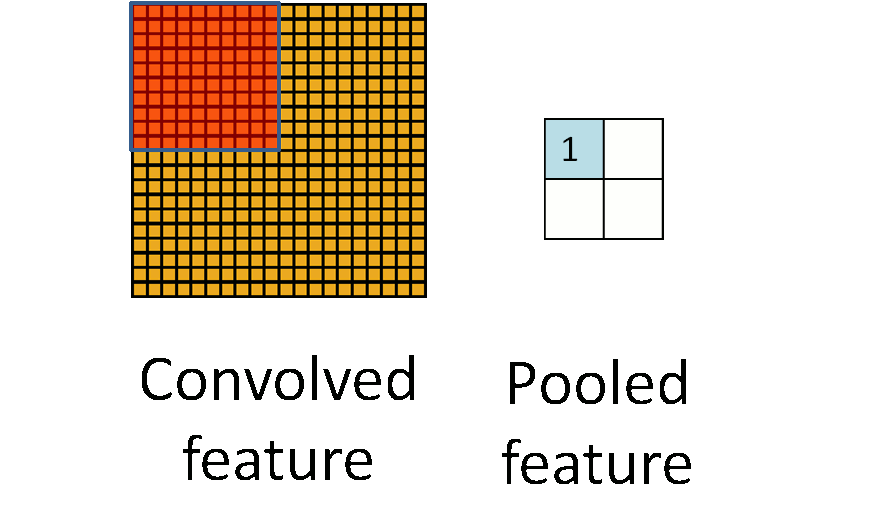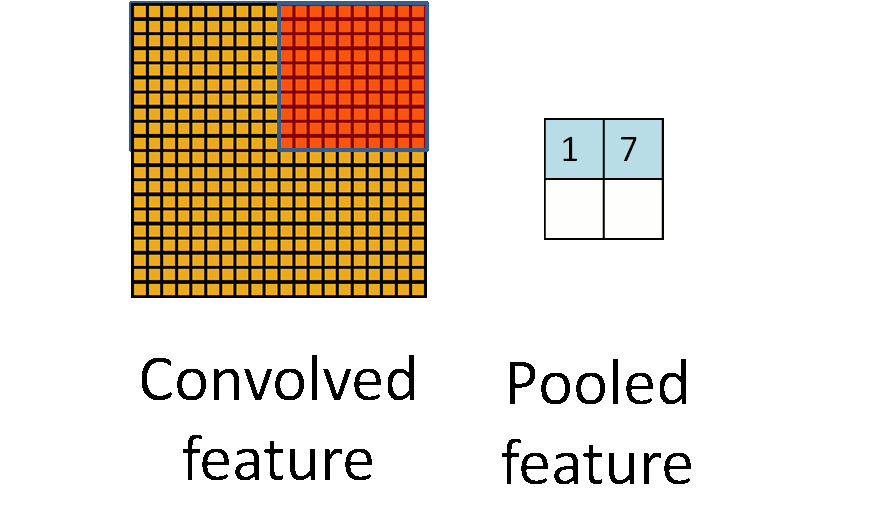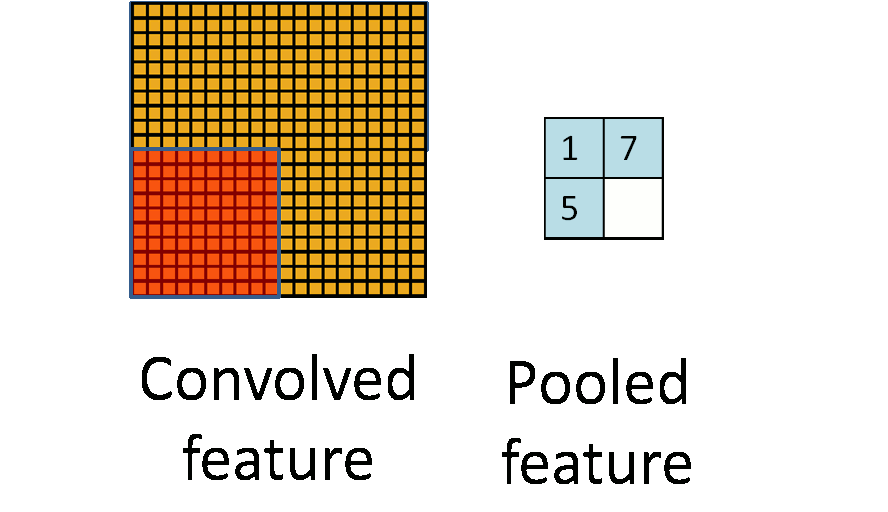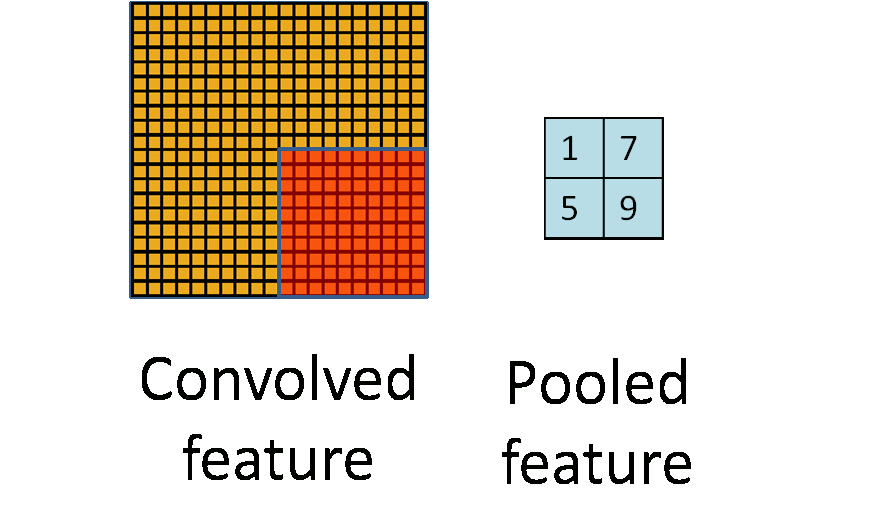
3.源码剖析
# -*- coding: utf-8 -*-
"""
Created on Sat Apr 28 14:59:48 2018
@author: demons
"""
import sys
sys.path.append('..')
import numpy as np
import torch
from torch import nn
from torch.autograd import Variable
from torchvision.datasets import CIFAR10
def vgg_block(num_convs, in_channels, out_channels):
net = [nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1), nn.ReLU(True)] # 定义第一层
for i in range(num_convs-1): # 定义后面的很多层
net.append(nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1))
net.append(nn.ReLU(True))
net.append(nn.MaxPool2d(2, 2)) # 定义池化层
return nn.Sequential(*net)
block_demo = vgg_block(3, 64, 128)
print(block_demo)
# 首先定义输入为 (1, 64, 300, 300)
input_demo = Variable(torch.zeros(1, 64, 300, 300))
output_demo = block_demo(input_demo)
print(output_demo.shape)
runfile('C:/Users/demons/Desktop/trainingtorch/VGG.py', wdir='C:/Users/demons/Desktop/trainingtorch')
Sequential(
(0): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace)
(2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace)
(4): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(5): ReLU(inplace)
(6): MaxPool2d(kernel_size=(2, 2), stride=(2, 2), dilation=(1, 1), ceil_mode=False)
)
torch.Size([1, 128, 150, 150])