要说明这个问题,首先要从计算机视觉中的“Hello World”问题说起:MNIST手写数字的分类。给定图像,将其分类。

来自MNIST数据集的图片样本。
MNIST数据集中的每个图像都是28x28像素,包含一个居中的灰度数字。
什么是卷积?
首先,介绍一下什么是卷积神经网络。
它是使用卷积层(Convolutional layers)的神经网络,基于卷积的数学运算。
卷积层由一组滤波器组成,滤波器可以视为二维数字矩阵。这是一个示例3x3滤波器:

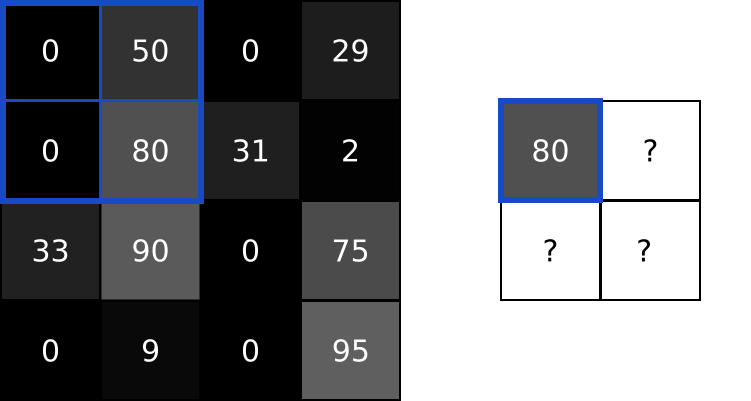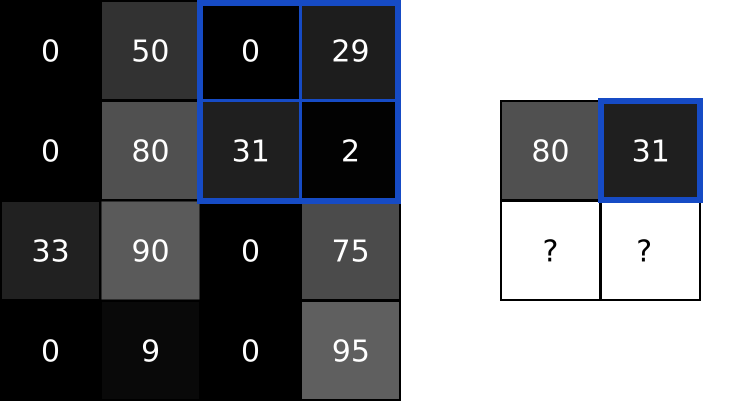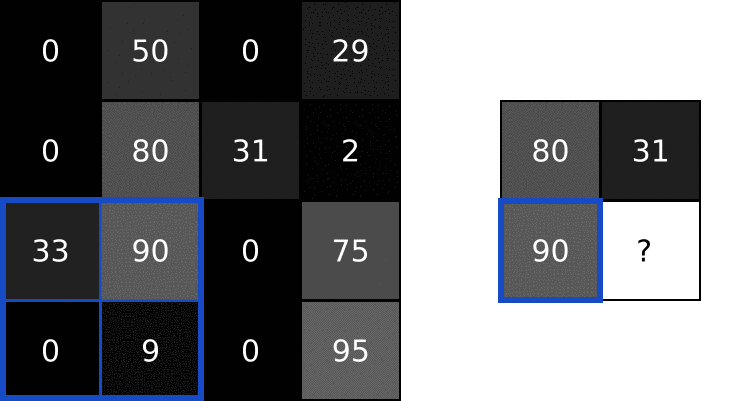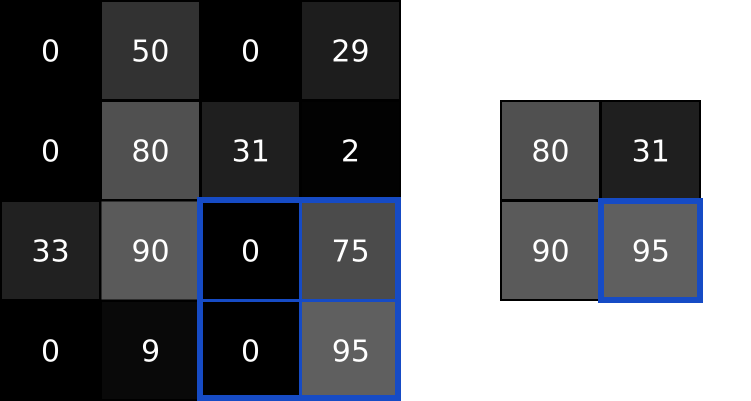
我们可以将滤波器与输入图像进行卷积来产生输出图像,那么什么是卷积操作呢?具体的步骤如下:在图像的某个位置上覆盖滤波器;将滤波器中的值与图像中的对应像素的值相乘;把上面的乘积加起来,得到的和是输出图像中目标像素的值;对图像的所有位置重复此操作。这个4步描述有点抽象,所以让我们举个例子吧。看下面的4x4灰度图像和3x3滤波器:

图像中的数字表示像素亮度,0是黑色,255是白色。我们将对输入图像和滤波器进行卷积,生成2x2输出图像。
首先,让我们将滤镜覆盖在图片的左上角:

接下来,我们在重叠的图像和滤波器元素之间逐个进行乘法运算,按照从左向右、从上到下的顺序。

把最右列的乘积结果全部相加,得到: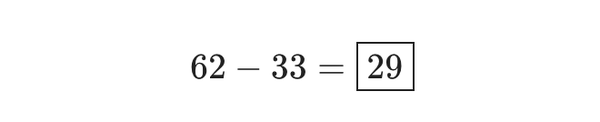
由于滤波器覆盖在输入图像的左上角,因此目标像素是输出图像的左上角像素: 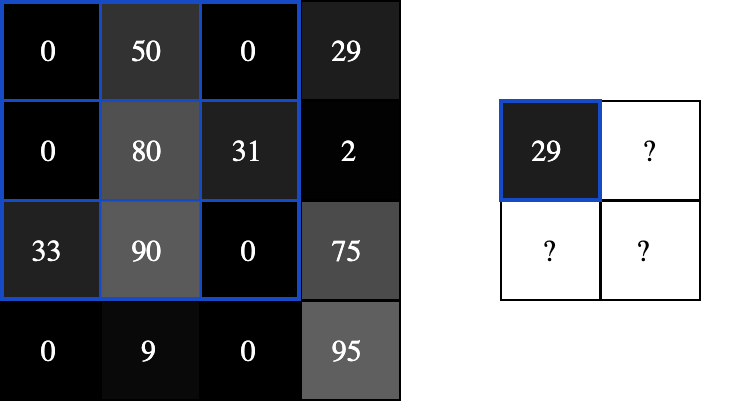
用同样的方式处理图像剩下的区域: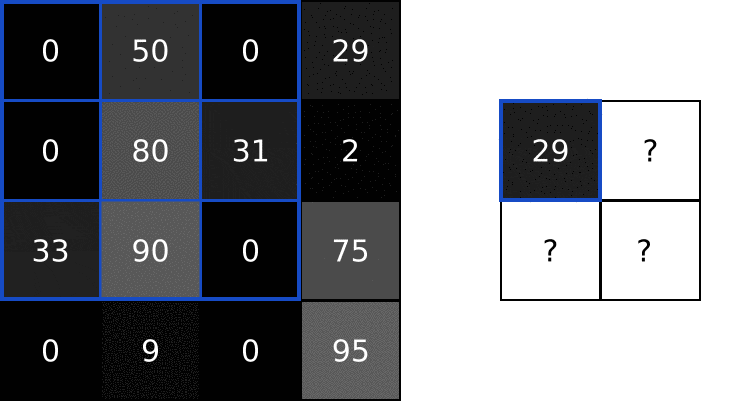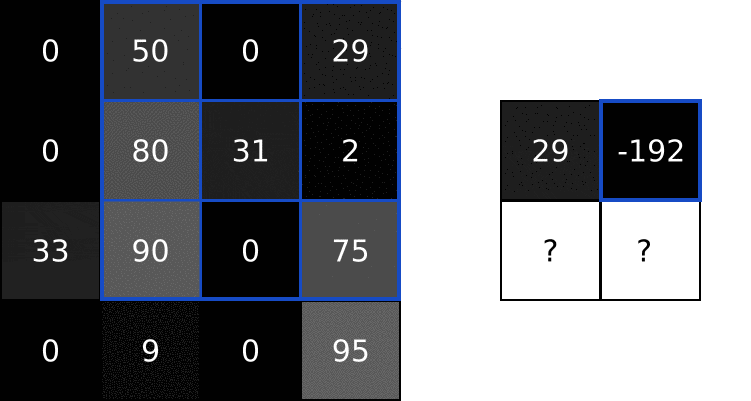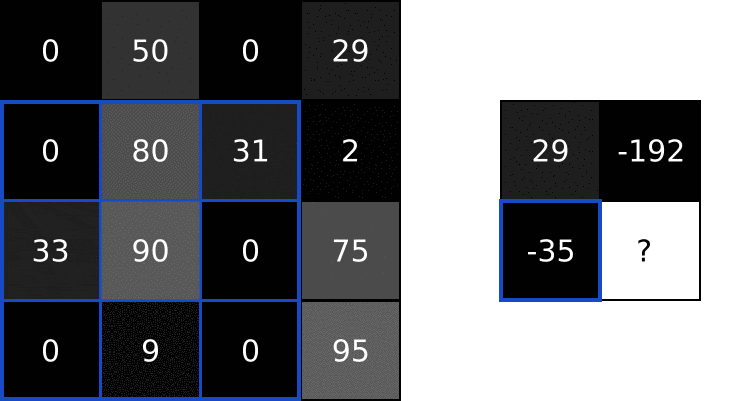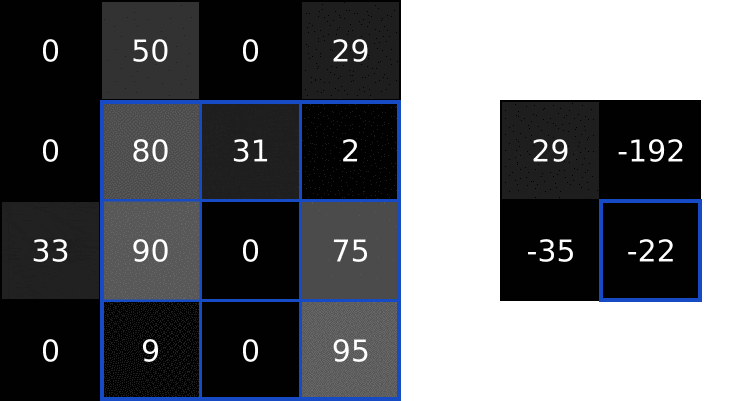 求卷积有何用?看完了基本概念,你可能会有疑问,对图像求卷积有什么用吗?我们在前文中使用的那个3x3滤波器,通常称为垂直索伯滤波器(Sobel filter):
求卷积有何用?看完了基本概念,你可能会有疑问,对图像求卷积有什么用吗?我们在前文中使用的那个3x3滤波器,通常称为垂直索伯滤波器(Sobel filter):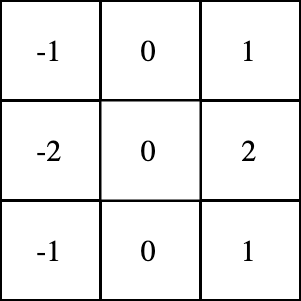 看看用它来处理知名的Lena照片会得到什么:
看看用它来处理知名的Lena照片会得到什么: 看出来了吗?其实,索伯滤波器是是边缘检测器。现在可以解释卷积操作的用处了:用输出图像中更亮的像素表示原始图像中存在的边缘。你能看出为什么边缘检测图像可能比原始图像更有用吗?回想一下MNIST手写数字分类问题。在MNIST上训练的CNN可以找到某个特定的数字。比如发现数字1,可以通过使用边缘检测发现图像上两个突出的垂直边缘。通常,卷积有助于我们找到特定的局部图像特征(如边缘),用在后面的网络中。填充在上面的处理过程中,我们用3x3滤波器对4x4输入图像执行卷积,输出了一个2x2图像。通常,我们希望输出图像与输入图像的大小相同。因此需要在图像周围添加零,让我们可以在更多位置叠加过滤器。3x3滤波器需要在边缘多填充1个像素。
看出来了吗?其实,索伯滤波器是是边缘检测器。现在可以解释卷积操作的用处了:用输出图像中更亮的像素表示原始图像中存在的边缘。你能看出为什么边缘检测图像可能比原始图像更有用吗?回想一下MNIST手写数字分类问题。在MNIST上训练的CNN可以找到某个特定的数字。比如发现数字1,可以通过使用边缘检测发现图像上两个突出的垂直边缘。通常,卷积有助于我们找到特定的局部图像特征(如边缘),用在后面的网络中。填充在上面的处理过程中,我们用3x3滤波器对4x4输入图像执行卷积,输出了一个2x2图像。通常,我们希望输出图像与输入图像的大小相同。因此需要在图像周围添加零,让我们可以在更多位置叠加过滤器。3x3滤波器需要在边缘多填充1个像素。  这种方法称之为“相同”填充,因为输入和输出具有相同的大小。而不使用任何填充称为“有效”填充。池化图像中的相邻像素倾向于具有相似的值,因此通常卷积层相邻的输出像素也具有相似的值。这意味着,卷积层输出中包含的大部分信息都是冗余的。如果我们使用边缘检测滤波器并在某个位置找到强边缘,那么我们也可能会在距离这个像素1个偏移的位置找到相对较强的边缘。但是它们都一样是边缘,我们并没有找到任何新东西。池化层解决了这个问题。这个网络层所做的就是通过减小输入的大小降低输出值的数量。池化一般通过简单的最大值、最小值或平均值操作完成。以下是池大小为2的最大池层的示例:
这种方法称之为“相同”填充,因为输入和输出具有相同的大小。而不使用任何填充称为“有效”填充。池化图像中的相邻像素倾向于具有相似的值,因此通常卷积层相邻的输出像素也具有相似的值。这意味着,卷积层输出中包含的大部分信息都是冗余的。如果我们使用边缘检测滤波器并在某个位置找到强边缘,那么我们也可能会在距离这个像素1个偏移的位置找到相对较强的边缘。但是它们都一样是边缘,我们并没有找到任何新东西。池化层解决了这个问题。这个网络层所做的就是通过减小输入的大小降低输出值的数量。池化一般通过简单的最大值、最小值或平均值操作完成。以下是池大小为2的最大池层的示例: