一、卷积核的定义
下图显示了CNN中最重要的部分,这部分称之为卷积核(kernel)或过滤器(filter)或内核(kernel)。因为TensorFlow官方文档中将这个结构称之为过滤器(filter),故在本文中将统称这个结构为过滤器。如下图1所示,过滤器可以将当前层网络上的一个子节点矩阵转化为下一层神经网络上的一个单位节点矩阵。单位节点矩阵指的是高和宽都是1,但深度(长)不限的节点矩阵。

图1:卷积层过滤器(filter)结构示意图
二、feature map(特征映射)的含义
在每个卷积层,数据都是以三维形式存在的。你可以把它看成许多个二维图片叠在一起,其中每一个称为一个feature map。在输入层,如果是灰度图片,那就只有一个feature map;如果是彩色图片,一般就是3个feature map(红绿蓝)。层与层之间会有若干个过滤器/卷积核(kernel),这个过滤器的尺寸大小(宽、高)和深度(长)是需要人工设定的,常用的过滤器尺寸有3*3或5*5。当前层中的所有feature map分别跟当前层和下一层间的每个卷积核做卷积求和后,都会产生下一层的一个feature map(这一句可能有点绕,但看完下面的例子后,相信你就能理解了)。通常有多少个卷积核,下一层就会生成多少个feature map,也就是下图3右边生成的`豆腐皮儿`的层数。
直接举例进行说明输出图片的长和宽。
输入照片为:32*32*3,

这是用一个activation map与一个Filter做卷积得到的结果,即一个新的activation map。(filter 总会自动扩充到和输入照片一样的depth)。
具体的卷积过程见通俗理解卷积神经网络 4.3节 cs231d的动态卷积图
当我们用6个5*5的Filter时,我们将会得到6个分开的activation maps,如图所示:

得到的“新照片”的大小为:28*28*6.
其实,每个卷积层之后都会跟一个相应的激活函数(activation functions):

假设,input为7*7,Filter尺寸为3*3,stride(步长)为2,则output过程如下所示:
最终得到一个3*3的output。
注:在这个例子中stride不能为3,因为那样就越界了。
总的来说
Output size=(N-F)/stride +1
这里N表示输入图片的边长,F表示Filter的边长。
当有填充(pad)时,例如对一个input为7*7进行pad=1填充,Filter为3*3,stride=1,会得到一个7*7的output。

Output size=(N-F+2*pad)/stride +1
注:0填充(pad)的主要目的是因为我们在前面的图中所示的那样,一直用5*5的Filter进行卷积,会导致体积收缩的太快,不利于特征的提取。
举例说明:

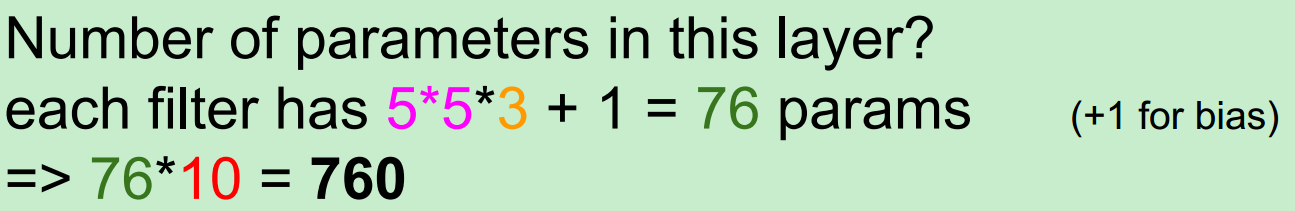
在这里要注意一下1*1的卷积核,为什么呢?
举例:一个56*56*64的input,用32个1*1的卷积核进行卷积(每一个卷积核的尺寸为1*1*64,执行64维的点乘操作),将得到一个56*56*32的output,看到输出的depth减少了,也就是降维,那么parameters也会相应的减少。
下面介绍一下Pooling(池化)操作:
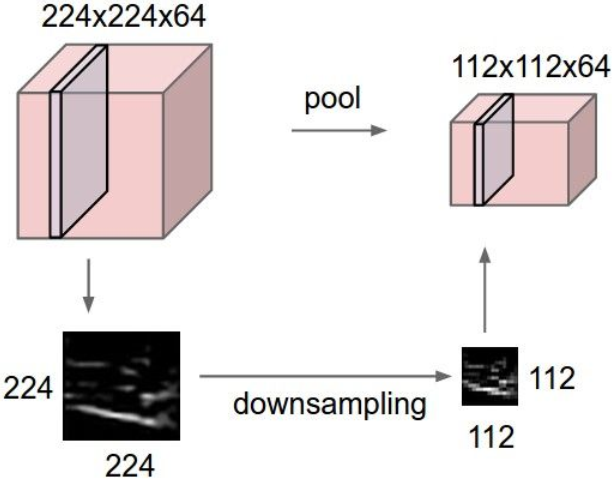
将represention变小,易于操作和控制,对每一个activation map单独进行操作。
用的最多的是最大池化(MAX POOLING):

Output size=(N-F)/S +1
三、数据是如何被输入到神经网络中
一个像素就是一个颜色点,一个颜色点由红绿蓝三个值来表示,例如,红绿蓝为255,255,255,那么这个颜色点就是白色。如果图像的大小是64 * 64个像素,那么3个64 * 64大小的矩阵在计算机中就代表了这张图像。上图中只画了个5 * 4的矩阵,而不是64 * 64,为什么呢?因为没有必要,搞复杂了反而不易于理解。
为了更加方便后面的处理,在人工智能领域中我们一般会把上面那三个矩阵转化成1个向量(向量可以理解成1 * n或n * 1的数组,前者为行向量,后者为列向量,后面我也会对向量进行详细的讲解)。那么这个向量的总维数就是64 * 64 * 3,结果是12288,也就是说上面那个有码的图像在计算机中就是12288个数字。在人工智能领域中,每一个输入到神经网络的数据都被叫做一个特征,那么上面的这张图像中就有12288个特征。这个12288维的向量也被叫做特征向量。神经网络接收这个特征向量作为输入,并进行预测,分析那块有码,然后去除可恶的马赛克,然后给出无码的图像!
对于不同的应用,需要识别的对象不同,有些是语音,有些是图像,有些是金融数字,有些是机器人传感器数据,但是它们在计算机中都有对应的数字表示形式,通常我们会把它们转化成一个特征向量,然后将其输入到神经网络中。
此文阐述了卷积层的一个特定的解剖特征。许多卷积架构是从一个外部卷积单元开始的,它将信道RGB的输入图像映射到一系列内部过滤器中。在当下最通用的深度学习框架中,这个代码可能如下所示:
out_1=Conv2d(input=image, filter=32, kernel_size=(3,3), strides=(1,1));//卷积层
relu_out=relu(out_1);//利用激活函数ReLU去线性化
pool_out=MaxPool(relu_out, kernel_size=(2,2), strides=2);//最大池化降维 很容易理解,上面的结果是一系列的具有32层深度的过滤器。我们不知道的是,该如何将具有3个信道的图像精确地映射到这32层中!另外,我们也不清楚该如何应用最大池(max-pool)操作符。例如,是否一次性将最大池化应用到了所有的过滤层中以有效地生成一个单一的过滤映射?又或者,是否将最大池独立应用于每个过滤器中,以产生相同的32层的池化过滤器?
具体如何做的呢?
一图胜千言,下图可以显示上述代码片段中所有的操作。

图2:卷积层的应用
观察上图,可以看到最显著的一点是,步骤1中的每个过滤器(即Filter-1、Filter-2……)实际上包含一组3个权重矩阵(Wt-R、Wt-G和WT-B)。每个过滤器中的3个权重矩阵分别用于处理输入图像中的红(R)、绿(G)和蓝(B)信道。在正向传播期间,图像中的R、G和B像素值分别与Wt-R、Wt-G和Wt-B权重矩阵相乘以产生一个间歇激活映射(intermittent activation map)(图中未标出),然后将这3个权重矩阵的输出(即3个间歇激活映射)相加以为每个过滤器产生一个激活映射(activation map)。
随后,这些激活映射中的每一个都要经过激活函数ReLu去线性化,最后到最大池化层,而后者主要为激活映射降维。最后,我们得到的是一组经过激活函数和池化层处理后的激活映射,现在其信号分布在一组32个(过滤器的数量)二维张量之中(也具有32个feature map,每个过滤器会得到一个feature map)。
来自卷积层的输出经常用作后续卷积层的输入。因此,如果我们的第二个卷积单元如下:
conv_out_2 = Conv2d(input = relu_out,filters = 64)
那么框架就需要实例化64个过滤器,每个过滤器使用一组32个权重矩阵。
参考:
https://www.cnblogs.com/Yu-FeiFei/p/6800519.html