使用台湾大学林智仁(C.J.Lin)等人开发的libsvm进行支持向量机回归分析(SVR)。如何安装libsvm工具箱,可以参考Matlab R2017a中libsvm工具箱的安装
libsvm软件包中主要函数调用格式如下:
1、训练函数 svmtrain
model = svmtrain(training_label_vector, training_instance_matrix, 'libsvm_options');
其中,training_label_vector:为训练集样本对应的类别标签,如有m个样本,则是mx1矩阵;
training_instance_matrix:为训练集样本的输入属性矩阵,如有m个样本,每个样本特征维n维,则是mxn矩阵
(training_label_vector和training_instance_matrix行数相等,每一行代表一个样本);
model:为训练好的支持向量机模型。
2、预测函数 svmpredict
[predicted_label, accuracy, decision_values/prob_estimates] = svmpredict(testing_label_vector, testing_instance_matrix, model, 'libsvm_options')
其中,testing_label_vector:为测试集样本对应的类别标签,如有m个样本,则是mx1矩阵;
testing_instance_matrix:为测试集样本的输入属性矩阵,如有m个样本,每个样本特征维n维,则是mxn矩阵
(testing_label_vector和testing_instance_matrix行数相等,每一行代表一个样本);
predicted_label:为预测得到的测试集样本的类别标签
accuracy:测试集的预测结果,为一个向量,保存格式为[准确率,MSE,R^2];
prob_estimates: If selected, probability estimate vector.
3、MATLAB程序实现
3.1 数据下载
还是使用之前 波士顿房屋数据集。
%%Download Housing Prices
filename = 'housing.txt';
urlwrite('http://archive.ics.uci.edu/ml/machine-learning-databases/housing/housing.data',filename);
inputNames = {'CRIM','ZN','INDUS','CHAS','NOX','RM','AGE','DIS','RAD','TAX','PTRATIO','B','LSTAT'};
outputNames = {'MEDV'};
housingAttributes = [inputNames,outputNames];
%%Import Data
formatSpec = '%8f%7f%8f%3f%8f%8f%7f%8f%4f%7f%7f%7f%7f%f%[^\n\r]';
fileID = fopen(filename,'r');
dataArray = textscan(fileID, formatSpec, 'Delimiter', '', 'WhiteSpace', '', 'ReturnOnError', false);
fclose(fileID);
housing = table(dataArray{1:end-1}, 'VariableNames', {'VarName1','VarName2','VarName3','VarName4','VarName5','VarName6','VarName7','VarName8','VarName9',...
'VarName10','VarName11','VarName12','VarName13','VarName14'});
%Delete the file and clear temporary variables
clearvars filename formatSpec fileID dataArray ans;
%%delete housing.txt
%%Read into a Table
housing.Properties.VariableNames = housingAttributes;
features = housing{:,inputNames};
prices = housing{:,outputNames};3.2 产生训练集/测试集
%% 随机产生训练集和测试集
[n,m] = size(features);
len = n;
index = randperm(len);%生成1~len 的随机数
%训练集——前70%
p_train = features(index(1:round(len*0.7)),:);%训练样本输入
t_train = prices(index(1:round(len*0.7)),:);%训练样本输出
%测试集——后30%
p_test = features(index(round(len*0.7)+1:end),:);%测试样本输入
t_test = prices(index(round(len*0.7)+1:end),:);%测试样本输出3.3 数据归一化
%% 数据归一化
%输入样本归一化
[pn_train,ps1] = mapminmax(p_train');
pn_train = pn_train';
pn_test = mapminmax('apply',p_test',ps1);
pn_test = pn_test';
%输出样本归一化
[tn_train,ps2] = mapminmax(t_train');
tn_train = tn_train';
tn_test = mapminmax('apply',t_test',ps2);
tn_test = tn_test';3.4 创建/训练SVR模型
采用默认的RBF核函数。首先利用交叉验证方法寻找最佳的参数c(惩罚因子)和参数g(RBF核函数中的方差),然后利用最佳的参数训练模型。值得一提的是,当模型的性能相同时,为了减少计算量,有先选择惩罚因子c比较小的参数组合,这是因为惩罚因子c越大,最终 得到的支持向量机将越多,计算量越大。
%% SVM模型创建/训练
% 寻找最佳c参数/g参数——交叉验证方法
[c,g] = meshgrid(-10:0.5:10,-10:0.5:10);
[m,n] = size(c);
cg = zeros(m,n);
eps = 10^(-4);
v = 5;
bestc = 0;
bestg = 0;
error = Inf;
for i = 1:m
for j = 1:n
cmd = ['-v ',num2str(v),' -t 2',' -c ',num2str(2^c(i,j)),' -g ',num2str(2^g(i,j) ),' -s 3 -p 0.1'];
cg(i,j) = svmtrain(tn_train,pn_train,cmd);
if cg(i,j) < error
error = cg(i,j);
bestc = 2^c(i,j);
bestg = 2^g(i,j);
end
if abs(cg(i,j) - error) <= eps && bestc > 2^c(i,j)
error = cg(i,j);
bestc = 2^c(i,j);
bestg = 2^g(i,j);
end
end
end
% 创建/训练SVM
cmd = [' -t 2',' -c ',num2str(bestc),' -g ',num2str(bestg),' -s 3 -p 0.01'];
model = svmtrain(tn_train,pn_train,cmd);3.5 SVR仿真测试
%% SVM仿真预测
[Predict_1,error_1,dec_values_1] = svmpredict(tn_train,pn_train,model);
[Predict_2,error_2,dec_values_2] = svmpredict(tn_test,pn_test,model);
% 反归一化
predict_1 = mapminmax('reverse',Predict_1,ps2);
predict_2 = mapminmax('reverse',Predict_2,ps2);
% 结果对比
result_1 = [t_train predict_1];
result_2 = [t_test predict_2];3.6 绘图
%% 绘图
figure(1)
plot(1:length(t_train),t_train,'r-*',1:length(t_train),predict_1,'b:o')
grid on
legend('真实值','预测值')
xlabel('样本编号')
ylabel('房价')
string_1 = {'训练集预测结果对比';
['mse = ' num2str(error_1(2)) ' R^2 = ' num2str(error_1(3))]};
title(string_1)
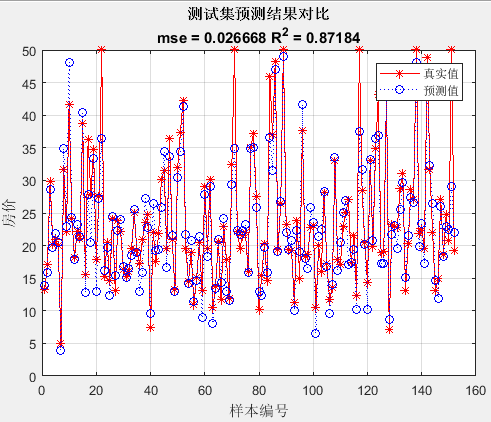
figure(2)
plot(1:length(t_test),t_test,'r-*',1:length(t_test),predict_2,'b:o')
grid on
legend('真实值','预测值')
xlabel('样本编号')
ylabel('房价')
string_2 = {'测试集预测结果对比';
['mse = ' num2str(error_2(2)) ' R^2 = ' num2str(error_2(3))]};
title(string_2)