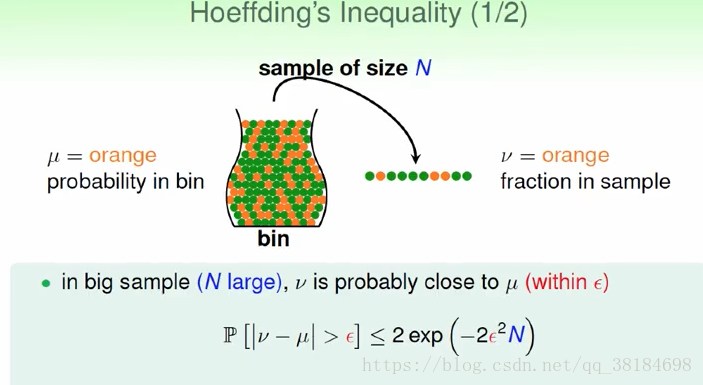
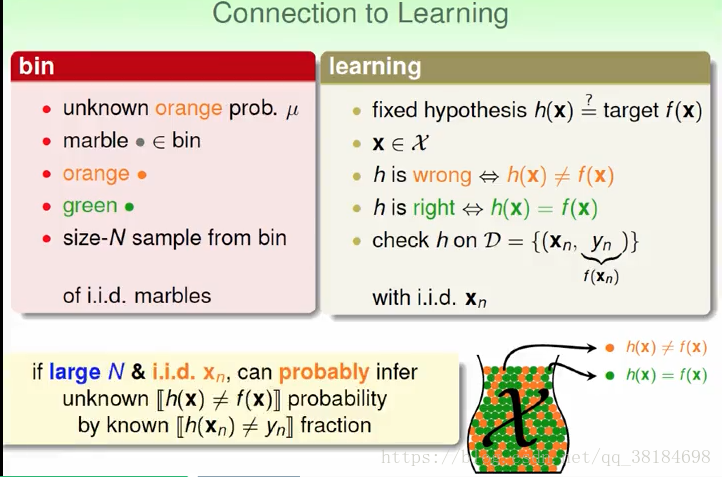
我们用罐子取弹珠来模拟机器学习,罐子里的弹珠类比x,假设我们已经通过机器学习得到了hypothesis h(x),用这个h(x)分类正确的x设为绿色弹珠,分类错误设为橘色弹珠,为了能估计Eout,我们取出一些弹珠求出绿色弹珠的比例,即求Ein,就能估计Eout,而能为我们的估计作出保证的就是Hoeffding不等式。

但是上述这一过程并没有进行机器学习,因为我们已经事先得到了一个hypothesis,而没有从许多hypothesis中进行选择的过程。实际上,上述方法用于validation中,进行validation的时候,我们已经完成了学习到最好的hypothesis的过程,即已经得到了一个h,我们就通过Hoeffding不等式保证这个h的Eout到底有多好。
那么真正的学习有许多hypothesis选择又会怎么样呢?首先我们用从丢硬币可以知道,当丢的次数很多时,小概率事件会发生。

换到机器学习中,对于某堆抽出来的数据,如果我们有很多hypothesis供我们选择,那么我们有很大可能刚好有某个hypothesis对这堆数据表现很好,它的Ein很低,然而实际上Eout却不是那么好,与Ein相差很大。Hoeffding不等式保证我们大部分情况下数据Ein和实际的Eout很接近,但是仍然有小部分数据是不好的,而大量的选择会增大这种不好的几率。

所以我们需要选择一个好的资料,这个资料能让演算法自由自在做选择,即当我们有许多hypothesis选择时,这些hypothesis作用在资料上得到的Ein和Eout都很接近,我们不用担心会踩到雷。而只要在一个hypothesis上,Ein和Eout差的很远,那这就不是好的资料。
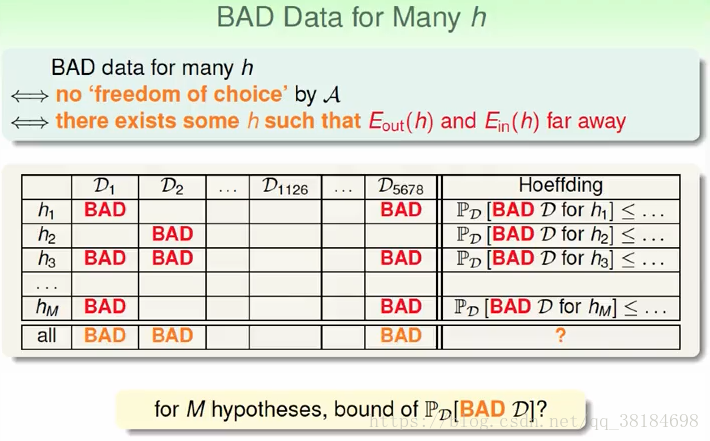
我们可以算出不是好的资料的概率:

最后我们可以得到,如果hypothesis是有限的,然后抽出来的数据又足够大,那么对于任意的演算法来说,我们都可以保证Ein和Eout很接近。然后如果有一个演算法的Ein很小,我们就有很大把握知道Eout也会很小,就能学习到一个好的演算法。