第四周课件 下载密码:kx0q
上一篇博客主要介绍了第三周的课程的内容,主要讲解分类问题,引入了逻辑回归模型来解决分类问题,并详细的介绍了逻辑回归模型的细节,包括假设函数,代价函数,优化求解方法包括之前学习的梯度下降法和更高级的优化方法,以及多分类问题的探讨,最后介绍了过拟合问题,并以线性回归和逻辑回归为例讲解该问题的解决方法(正则化)。本篇博客将系统的介绍第四周的学习内容,本周主要讲的是神经网络学习,包括非线性假设(通过实例说明逻辑回归解决分类问题的局限性以及引入神经网络进行分类的必要性),神经元和大脑(神经网络算法的由来),神经网络模型的表示以及工作原理,通过逻辑运算的例子直观的理解神经网络,最后简单介绍了利用神经网络进行多分类的问题。
目录
神经网络学习
1.非线性假设
- 研究神经网络的目的
之前我们已经学习了线性回归和逻辑回归,对于大多数的分类或回归问题都有了一个不错的解决方案,那么我们为什么还要学习神经网络呢?首先通过一个例子,阐述一下研究神经网络的目的:
下图是一个数据集可视化的结果,该数据集有两个原始输入特征,现在要对该数据集的样本进行一个二分类:
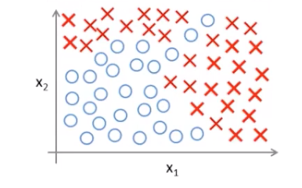
假设我们此时使用的是逻辑回归算法,如果仅使用原始的两个输入特征,是不可能把样本分类好的,因为我们需要一个非线性的决策边界。所以,此时我们应该在原始特征的基础上增加新的特征,比如这些原始特征的组合。决策边界和假设函数如下所示:

通过对原始特征进行组合增加特征,相当于数据集此时有多个输入特征,可以把每一种原始特征的组合当做一个新的输入特征。那么我们就有可能得到一个非线性的决策边界,从而如图中所示,把这些样本分开。
当只有两个原始输入特征时,上述这种组合方法是可行的,大不了就把所有的原始特征组合都包含到假设函数中。
但是,大多数机器学习问题的特征数量都是很大的,考虑如下的房价数据集,他有个原始输入特征,考虑房子能不能卖出去这样一个二分类问题:

为了得到一个很好的分类效果,我们可能会对原始特征进行组合以得到新的输入特征,接下来我们尝试一些组合方式,来查看特征的增加量:

首先我们考虑所有原始输入特征的2次项组合,包括大约有5000个新特征,此时特征增加量级是
;
当然,对于2次项的组合,我们也可以做一些简化,比如可以只取所有的平方项,那么此时特征会大大减少,只有100个。这不是一种好的做法,虽然特征数减少了,但是忽律了太多特征细节,很有可能得不到一个理想的分类效果。
既然有2次项组合,那么肯定可以进行3次项的组合,包括等大约有170000个新特征,此时特征增加量级是
。
当然还有各种原始特征组合方式,但是当进行到3次项组合时,我们发现特征数量就已经非常多,而这仅仅是在原始特征数为100个的情况下。那么当原始特征更多时,可想而知,此时的特征空间会极度膨胀。接下来我们看另一个例子:

这是一个计算机视觉的问题,我们的目的是让计算机看懂这张图片代表的是什么。当然对于我们人来说,这很简单,就是一辆车;但对于计算机来说却很难,他看到的实际是一个像素矩阵,矩阵中的元素是像素的亮度值。计算机视觉就是根据矩阵中像素的亮度值,得到他的含义,代表的是什么东西。

上图是一个汽车分类的问题,我们再对汽车进行分类时,首先需要一个标注训练数据集,包含一些汽车图片和一些非汽车图片,然后我们用这个标注数据集训练我们的分类模型,训练结束后,再进行测试,通过输入一张新的图片,让之前训练好的分类器判断它是什么。

假设我们在一幅汽车图片上取两个像素点作为原始输入特征,那么可能会得到这样一个数据集,我们把它可视化,其中+代表汽车,-代表非汽车:

很显然我们需要一个非线性的决策边界。实际上,对于一幅汽车图片,它远远不止两个像素点。假设我们的汽车图片,像素是50*50的灰度图,那么它就有2500个像素点(每个像素点亮度取值0-255),也就意味着有2500个原始输入特征;如果考虑彩色图的话,会有RGB三个颜色通道,此时将会有7500个原始输入特征。
如果我们再像之前那样,通过对原始特征进行组合,增加新特征的话,仅仅是2次项组合方式,就会增加300w个新特征,这是相当恐怖的,更不用说其他组合方式了。

因此,通过上述两个例子,我们知道在原始输入特征很多的情况下,再使用简单的逻辑回归并通过对原始特征组合增加新特征的方式是不可行的,计算成本太高。
我们此时需要一个更加强大的非线性分类器--神经网络,与逻辑回归不同,不论原始输入特征是多少维,它都会有一个很好的分类效果。
2.神经元与大脑
神经网络的起源是一种模仿人类大脑的算法。
既然我们想要创造一个智能的机器,我们何不模仿人类最神奇的大脑,如果我们知道了大脑的学习算法,那么我们就能制造出真正智能的机器了。而这个假设是有科学依据的:

图中所示的大脑皮层是我们的听觉皮层,如果我们切断听觉神经并为听觉皮层连接上视觉神经,我们会发现这个听觉皮层会学会看。
这就说明,大脑会根据我们看到的事物,通过一种学习算法,从而得到一种看的能力。我们致力于研究的正是这种学习算法。一旦知道了该算法的机理,那么真正的智能就会诞生了。
3.模型展示I
本小节我们将学习如何表示神经网络:
首先我们先看一下大脑中的神经元结构:

神经元通过Dendrite(输入通道)接收信息,再通过Nucleus(细胞体)处理信息,最后通过Axon(输出通道)将处理后的信息传递给其他神经元。
接下来我们使用人工神经网络模型来模仿大脑的神经元:
- 单个神经元

仅考虑存在三个输入特征,事实上可以有个输入特征。
单个神经元的模型实际上完全可以看作是一个逻辑回归模型,原始输入特征称为输入层;图中的黄圈代表神经元,称为输出层;
是模型最后的输出,
.
神经元的计算操作,就是对原始输入特征进行加权组合,再通过一个sigmoid激活函数,得到最后的输出。其中是参数,也叫权重,
是原始输入特征。
有时候会在输入特征中增加一个偏置项,其值恒等于1;有时候则没有该项,视具体情况而定。
- 多个神经元

其中Layer1称为输入层,对应原始输入特征,可以有个,有时需要添加一个偏置项
;
Layer3为输出层,上图中只有一个神经元,实际上可以有多个,视情况而定(几分类就有几个);
Layer2为隐藏层,上图中只有一个隐藏层,实际上隐藏层可以有多个,输入层和输出层之间的都是隐藏层;而且每个隐藏层可以有多个神经元,有时隐藏层也会有偏置项。
各层之间的神经元采用全联接的方式。
接下来看一下各层之间具体的运算过程和符号表示:

:第j层的第i个神经元
:从第j层到第j+1层的权重(参数)矩阵,如果第j层有
个神经元,第j+1层有
个神经元,那么他们之间的权重矩阵
的维度是
.
具体的运算过程如上图所示,前一层所有神经元输出值的加权组合再通过一个sigmoid激活函数,作为下一层每一个神经元的输入。
上图中的网络结构比较简单,实际上一般有很多隐藏层,每个隐藏层有很多神经元,计算过程都是一样的。
输入层的单元数由原始输入特征决定。
输出层的单元数由分类类别数决定。
总结:
神经网络实际上可以得到一个从输入特征x到输出变量y的一个映射.根据参数
的不同,就会得到不同假设函数
。
4.模型展示II
- 向量化表示方法:

用向量表示所有输入原始输入特征+偏置项,它的每一维度代表一个原始输入特征,
也可以记为
。
向量与第j层的神经元有关,每个分量代表j-1层特征的加权组合。
向量是
经过激活函数得到的结果,两个向量是同维的;
是第j层神经元的输出。
对添加偏置项
,作为j+1层的输入,重复上述过程,直到输出层得到假设函数
。
上述过程就是神经网络算法的前向传播过程,从输入层开始,上一层的特征向量作为输入和一个参数矩阵进行线性组合,再通过一个激活函数,最后添加一个偏置项,得到下一层的输出;该输出再作为下一层的输入重复上述过程,直到输出层。
- 神经网络原理

如果我们遮住左半边只看上图中的黄色部分,实际上它就是一个逻辑回归,对输入特征进行加权组合,再通过sigmoid,得到。
但是神经网络的不同在于,他不是直接以原始输入特征作为输入,而是先对原始输入特征通过隐藏层进行一系列训练,计算出更复杂的特征,来作为最终“逻辑回归”的输入,从而得到一个复杂的非线性假设。
这些复杂的特征取决于权重,
不同,计算得到的复杂特征也就不同。
输入层一般来说是原始特征,当然也可以对原始特征进行一些组合,形成新的特征;二者拼接作为输入层,也是可以的。
- 其他结构神经网络

Layer1是原始输入特征;
Layer2是对原始输入特征进行计算得到复杂特征1;
Layer3再对复杂特征1进行计算得到复杂特征2;
复杂特征2最后作为“逻辑回归”的输入特征,进行分类(上图是2分类)。
隐藏层越多,计算得到的特征就越复杂,就会得到更加复杂的非线性假设和决策边界。
5.例子与直觉理解I
简单逻辑运算:
- AND

假设权重已经训练得到,分别是,那么假设函数
也就确定了,表达式如上图中所示。
上图是单神经元结构,g是sigmoid激活函数,对于不同的输入组合,带入
,得到最终的结果,如上图所示。
- OR

假设权重已经训练得到,分别是,那么假设函数
也就确定了,表达式如上图中所示。
上图是单神经元结构,g是sigmoid激活函数,对于不同的输入组合,带入
,得到最终的结果,如上图所示。
6.例子与直觉理解II
- NOT

假设权重已经训练得到,分别是,那么假设函数
也就确定了,表达式如上图中所示。
上图是单神经元结构,g是sigmoid激活函数,对于不同的输入,带入
,得到最终的结果,如上图所示。
- 复杂逻辑运算XNOR
可以把简单的逻辑运算复合在一起:
XNOR
= (
AND
) OR ((NOT
) AND (NOT
))

假设简单逻辑运算的权重已经训练得到,分别如上图所示,下半部分的复杂逻辑运算可以直接用各简单逻辑运算的参数,那么假设函数也就确定了。
上图是多神经元结构,除了输入、输出层之外还有一个隐藏层,隐藏层对输入层的特征进行计算,得到更复杂的特征,从而得到一个复杂的非线性决策边界,使用的是sigmoid激活函数,对于不同的输入组合,带入上图中的结构,得到的隐藏层结果和最终的结果,如上图所示。
7.多元分类
实际中,我们一般用神经网络解决一些多类别分类的问题。
首先我们来看一个四分类的例子,他的训练数据集如下:

其中是原始输入特征,
为输出变量(标记Label);由于这是一个四分类问题,
是一个四维向量,且只有一个分量为1,代表该训练样本所属的类别,具体类别对应如上图所示。
采用的神经网络结构:

假设采用的神经网络结构如上图所示,它有四层,输入层有三个单位,代表原始输入特征是3维的;输出层有四个单元,代表进行一个四分类;中间有两个隐藏层,用于对原始特征进行训练,得到更加复杂的特征,从而最后得到复杂的非线性决策边界。
- 训练过程:
首先初始化模型参数,把所有的训练样本“喂”给上述网络模型,通过前向传播,到输出层得到一个四维向量,对该向量进行归一化操作(softmax),再与训练样本标签y计算损失函数;
最小化该损失函数,反向传播(下节讲述)更新模型参数,直到得到一组不错的模型参数为止,模型训练结束。
- 测试过程:
模型训练结束后,参数也就确定了,对于新的样本,将其输入特征带入上述网络结构中,得到最后的输出并归一化,得到一个四维向量,该向量哪个分量的数值最大,则认为这个新样本属于哪个类别。

8.编程作业:多元分类与神经网络
本周的编程作业详见我的另一篇博客:神经网络与多分类