这里我们用到了特征筛,为什么要进行特征进行选择?
在一个数据集中,我们需要找出对因变量影响显著的变量,对于显著性较低的我们进行剔除,留下显著性高的特征把它们加入模型,从而使我们的模型复杂度更低,更加的简洁,准确。
这篇文章使用反向淘汰的方法来进行此项工作
反向淘汰步骤:
- 确定我们用来衡量显著性的一个阈值(决定取舍),这里我们取0.05
- 将所有的特征ALL IN到模型进行训练
- 计算出每个特征的P_value
- 将P_value最高的且高于显著水平的阈值的特征从模型训练中剔除
- 利用剩下的特征进行新一轮的拟合,如果存在P_value大于阈值,则返回4步,直到所有特征的P_value小于设定的阈值
关于P_value:
- p值是指在一个概率模型中,统计摘要(如两组样本均值差)与实际观测数据相同,或甚至更大这一事件发生的概率。换言之,是检验假设零假设成立或表现更严重的可能性。p值若与选定显著性水平(0.05或0.01)相比更小,则零假设会被否定而不可接受。然而这并不直接表明原假设正确。p值是一个服从正态分布的随机变量,在实际使用中因样本等各种因素存在不确定性。产生的结果可能会带来争议。
- 零假设(null hypothesis),统计学术语,又称原假设,指进行统计检验时预先建立的假设。 零假设成立时,有关统计量应服从已知的某种概率分布。
当统计量的计算值落入否定域时,可知发生了小概率事件,应否定原假设。
数据集说明:
CRIM:城镇人均犯罪率。
ZN:住宅用地超过 25000 sq.ft. 的比例。
INDUS:城镇非零售商用土地的比例。
CHAS:查理斯河空变量(如果边界是河流,则为1;否则为0)。
NOX:一氧化氮浓度。
RM:住宅平均房间数。
AGE:1940 年之前建成的自用房屋比例。
DIS:到波士顿五个中心区域的加权距离。
RAD:辐射性公路的接近指数。
TAX:每 10000 美元的全值财产税率。
PTRATIO:城镇师生比例。
B:1000(Bk-0.63)^ 2,其中 Bk 指代城镇中黑人的比例。
LSTAT:人口中地位低下者的比例。
MEDV:自住房的平均房价,以千美元计。
#导入用到的库
import sklearn.datasets as datasets
import pandas as pd
import numpy as np
#载入数据集
Boston = datasets.load_boston()
# print(Boston.feature_names)
x = Boston.data #shape:(506, 13)
y = Boston.target #shape:(506,)由于多元线性回归基本方程为:

因此需要在变量矩阵添加一列全一:(该操作也是反向淘汰的准备工作)
#数据预处理
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
x = ss.fit_transform(x)#特征缩放
x = np.append(arr=np.ones((x.shape[0],1)),values= x ,axis = 1) #添加方程式常数项的系数
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size = 0.25,random_state = 0)#分割数据集为训练集与测试集#创建回归器并拟合数据
import statsmodels.formula.api as sm
x_option = x_train[:,[0,1,2,3,4,5,6,7,8,9,10,11,12,13]]
ols = sm.OLS(endog= y_train,exog=x_option,).fit()
ols.summary() #查看回归器的参数信息输出:
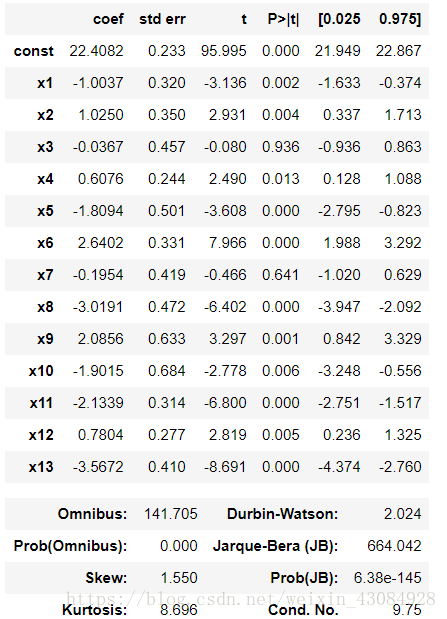
可以看到x_3(特征I–NDUS。)的P_value是最高的且高于设定的阈值,将之剔除
新一轮拟合:
x_option = x_train[:,[0,1,2,4,5,6,7,8,9,10,11,12,13]]
ols = sm.OLS(endog= y_train,exog=x_option,).fit()
ols.summary() 输出:
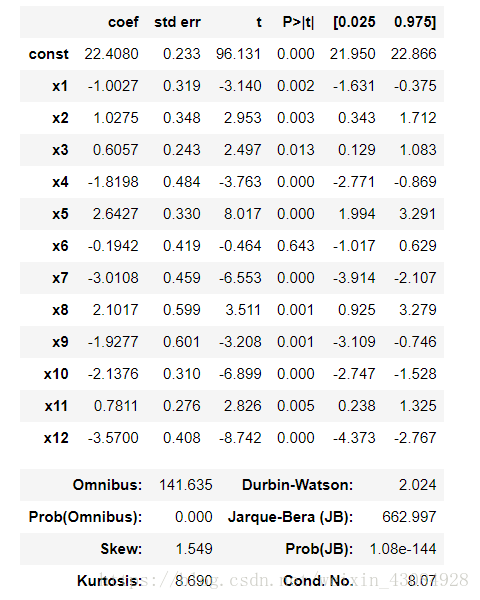
这次也是剔除x_6不过这里的x_3对应的是X_train的第7个变量(加了一列)即(RM:住宅平均房间数)
循环处理,知道所留下的特征的P_value都低于显著水平阈值
最后:
X_opt = X_train[:,[0,1,2,4,5,6,8,9,10,11,12,13]]
regressor_OLS = sm.OLS(endog=Y_train,exog=X_opt).fit()
regressor_OLS.summary() 输出:
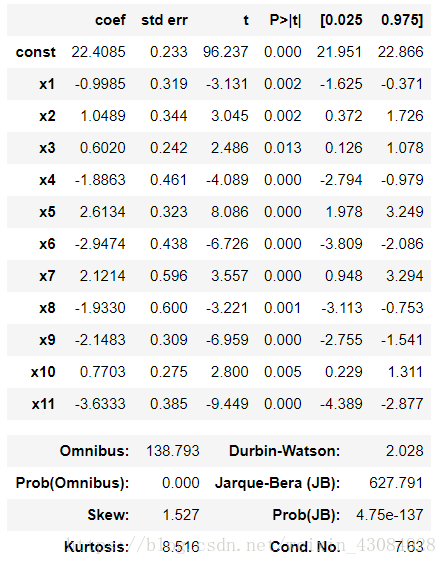
可以看到剩下的P_value小于设定的显著水平,这就是最终的结果了。
#利用拟合好的最终模型,进行测试集的预测
y_pre = ols.predict(x_test[:,[0,1,2,4,5,6,8,9,10,11,12,13]])#模型评估
from sklearn.metrics import r2_score, mean_squared_error
print(r2_score(y_test,y_pre))#(确定系数)回归分数函数。
print(mean_squared_error(y_test,y_pre)) #均方误差回归损失输出:
r2_score : 0.6368341501259818
mean_squared_error : 29.670292375423013
#结论看,模型不怎么好。。哈哈哈接下来尝试用多次项试试看下结果:
#数据的载入与处理
Boston = datasets.load_boston()
x = Boston.data #shape:(506, 13)
y = Boston.target #shape:(506,)
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
x = ss.fit_transform(x) #特征缩放
x = x[:,[0,1,2,4,5,6,8,9,10,11,12]] #这里采用了上文剔除特征的结果
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size = 0.25,random_state = 0)#分割数据集
from sklearn.preprocessing import PolynomialFeatures
pf = PolynomialFeatures(degree=2)
x_train = pf.fit_transform(x_train)#这个操作会自动增加常数项的系数,用法可以参考文档#建立模型
from sklearn.linear_model import LinearRegression
regressor = LinearRegression()
regressor = regressor.fit(x_train,y_train)#预测测试集
x_test = pf.fit_transform(x_test) #对测试集也进行多项处理
y_pre = regressor.predict(x_test) #预测#模型评估
from sklearn.metrics import r2_score, mean_squared_error
print(r2_score(y_test,y_pre)) #(确定系数)回归分数函数。
print(mean_squared_error(y_test,y_pre)) #均方误差回归损失输出:
r2_score : 0.7530871120604362
mean_squared_error : 20.17253984362321貌似稍微好了一些。也不知道做对了没,或者大家有什么好的方案,欢迎交流~