Spark的作业和任务调度系统是Spark的核心,它能够有效地进行调度根本原因是对任务划分DAG和容错,使得它对低层到顶层的各个模块之间的调用和处理显得游刃有余。下面介绍一些相关术语。
- 作业(Job):RDD中由行动操作所生成的一个或多个调度阶段。
- 调度阶段(Stage):每个Job作业会因为RDD之间的依赖关系拆分成多组任务集合,称为调度阶段,简称阶段,也叫做任务集(TaskSet)。调度阶段的划分是由DAGScheduler(DAG调度器)来划分的。调度阶段有Shuffle Map Stage和Result Stage两种。
- 任务(Task):分发到Executor上的工作任务,是Spark实际执行应用的最小单元。Task会对RDD的partition数据执行指定的算子操作,比如flatMap、map、reduce等算子操作,形成新RDD的partition。
- DAGScheduler(DAG调度器):DAGScheduler是面向Stage(阶段)的任务调度器,负责接收Spark应用提交的作业,根据RDD的依赖关系划分调度阶段,并提交Stage(阶段)给TaskScheduler。
- TaskScheduler(任务调度器):TaskScheduler是面向任务的调度器,它接收DAGScheduler提交过来的Stage(阶段),然后把任务分发到Worker节点运行,由Worker节点的Executor来运行该任务。
1、作业执行原理概述
Spark的作业调度主要是指基于RDD的一系列操作构成一个作业,然后在Executor中执行。这些操作算子主要分为转换操作和行动操作,对于转换操作的计算是lazy级别的,也就是延迟执行,只有出现了行动操作才触发作业的提交。在Spark调度中最重要的是DAGScheduler和TaskScheduler两个调度器,其中DAGScheduler负责任务的逻辑调度,将Job作业拆分成不同阶段的具有依赖关系的任务集,而TaskScheduler则负责具体任务的调度执行。
通过下图从整体上对Spark的作业和任务调度系统进行分析,图中的执行流程总体上可分为提交作业、划分调度阶段(Stage)、提交调度阶段(Stage)、提交任务、执行任务、获取执行结果。
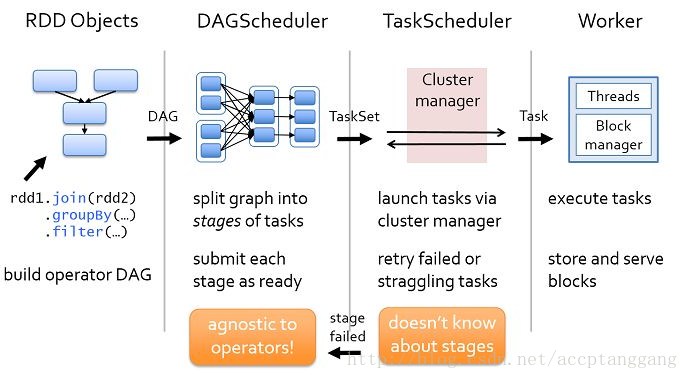
(1)Spark应用程序进行各种转换操作,通过行动操作触发Job作业运行。Job提交之后根据RDD之间的依赖关系构建DAG图,DAG图提交给DAGScheduler进行解析。
(2)DAGScheduler是面向调度阶段的高层次的调度器,DAGScheduler把DAG拆分成相互依赖的Stage调度阶段,拆分的Stage阶段是以RDD的依赖是否是宽依赖界限。当遇到宽依赖就划分为新的Stage。每个Stage阶段包含一个或多个任务,这些任务形成任务集,提交给底层调度器TaskScheduler进行调度运行。另外,DAGScheduler记录哪些RDD被存入磁盘等动作,同时要寻求任务的最优化调度,例如数据本地性等。DAGScheduler监控运行调度阶段过程,如果某个调度阶段运行失败,则需要重新提交该调度阶段。
(3)每个TaskScheduler只为一个SparkContext实例服务,TaskScheduler接收来自DAGScheduler发送过来的任务集(TastSet),TaskScheduler收到任务后负责把任务集以任务的形式一个个分发到集群Worker节点的Executor中去运行。如果某个任务运行失败,TaskScheduler要负责重试。另外,如果TaskScheduler发现某个任务一直未运行完,就可能启动同样的任务运行同一个计算,哪一个任务先运行完就用哪个任务的结果。
(4)Worker中的Executor收到TaskScheduler发送过来的任务后,以多线程的方式运行,每一个线程负责一个任务。任务运行结束后要返回给TaskScheduler,不同类型的任务,返回的方式也不同。ShuffleMapTask返回的是一个MapStatus对象,而不是结果本身。如果任务是ResultTask,判断该作业是否完成,如果完成,则标记该作业已经完成,清除作业依赖的资源并发送消息给系统监听总线告知作业执行完毕。