1.首先看一下代码。
package day01
import org.apache.log4j.{Level, Logger}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* 这是一个scala版本的Spark词频统计程序
* Created by zhangjingcun on 2018/9/17 16:01.
*/
object ScalaWordCount {
def main(args: Array[String]): Unit = {
Logger.getLogger("org.apache.spark").setLevel(Level.OFF)
val conf = new SparkConf().setAppName("ScalaWordCount").setMaster("local")
//SparkContext,是Spark程序执行的入口
val sc = new SparkContext(conf)
//通过sc指定以后从哪里读取数据
//RDD弹性分布式数据集,一个神奇的大集合
val lines: RDD[String] = sc.textFile(args(0))
//将内容分词后压平
val words: RDD[String] = lines.flatMap(_.split(" "))
println(words.collect().toBuffer)
//将单词和1组合到一起
val wordAndOne: RDD[(String, Int)] = words.map((_, 1))
//分组聚合
val reduce: RDD[(String, Int)] = wordAndOne.reduceByKey(_+_)
//排序
val sorted = reduce.sortBy(_._2, false)
/* //保存结果
sorted.saveAsTextFile(args(1))*/
println(sorted.collect().toBuffer)
//释放资源
sc.stop()
}
}
以上面的程序进行分析
val lines: RDD[String] = sc.textFile(args(0))
这行代码会生成两个RDD(HadoopRDD、MapPartitionsRDD)
//将内容分词后压平
val words: RDD[String] = lines.flatMap(.split(" "))
这行代码通过flatMap生成一个新的RDD
//将单词和1组合到一起
val wordAndOne: RDD[(String, Int)] = words.map((, 1))
通过map生成一个新的RDD
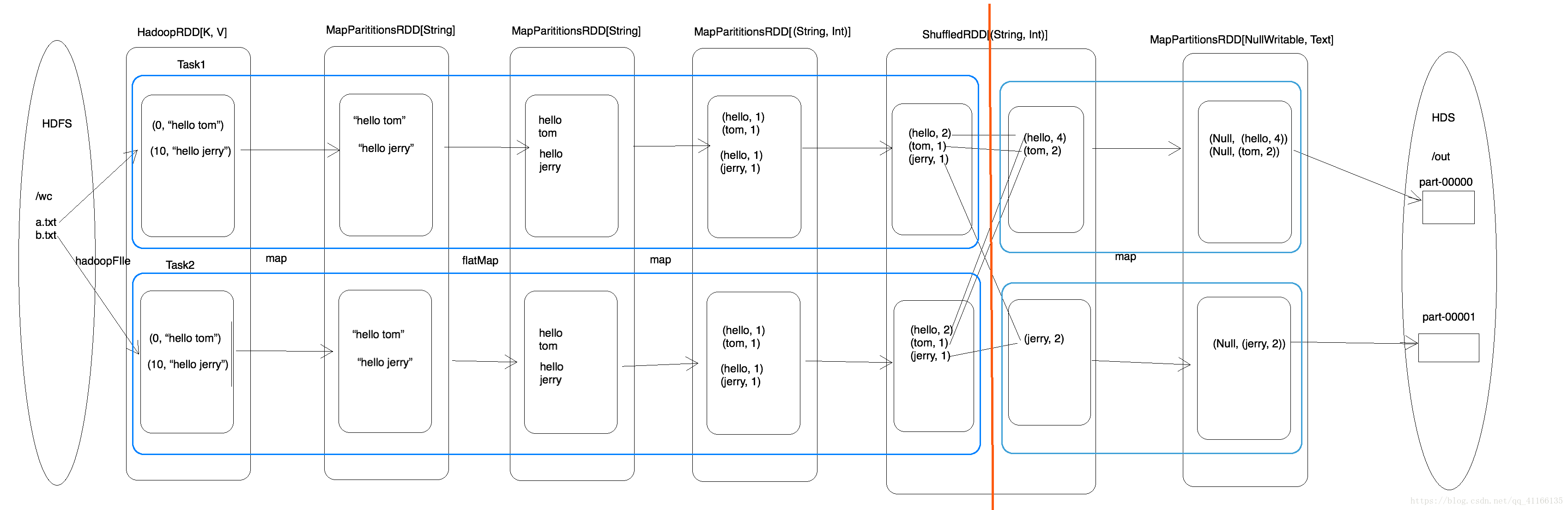
这时候就开始了一个ShuffedRDD,开始触发计算
val reduce: RDD[(String, Int)] = wordAndOne.reduceByKey(_+_)
**形成了一个新的RDD MapPartitionsRDD**
sorted.saveAsTextFile(args(1))*/
1.在这个过程中,生成两种类型的RDD,一种是shufferMapTask,另一种是resultTask 。
2.这个代码中生成了四个RDD,有两个阶段,
(1)一个是Shuffer前的相当与MapTask对中间数据进行计算(局部聚合)
(2)一个是Shuffer后的相当于ReduceTask进行计算写入到HDFS.(全局聚合)
(3)每个阶段又有最少两种RDD(map、flatMap、map可以合并),一个是a.txt文件的,另一个是b.txt文件的,所以这个过程生成了四个RDD