本文梳理一下Spark作业执行的流程。
Spark作业和任务调度系统是其核心,通过内部RDD的依赖DAG,使得模块之间的调用和处理变得游刃有余。
相关概念
Job(作业):通过行动操作生成的一个或多个调度阶段
Stage:根据依赖关系划分的多个任务集,称为调度阶段,也叫做TaskSet(任务集)。划分Stage是由DAGScheduler进行的,任务阶段分为Shuffle Map Stage和Result Stage。
Task:是Spark执行计算的最小单位,会被分发到Executor中执行。
DAGScheduler:是面向调度阶段的任务调度器,接收Spark应用提交的作业,根据依赖关系划分stage,并提交给TaskScheduler。
TaskScheduler:是面向任务的 调度器,接收DAGScheduler划分好的stage,发送给Worker节点的Executor运行任务。
关于RDD相关知识、行动操作、宽窄依赖请参考Spark RDD基本概念、宽窄依赖、转换行为操作
概述
Spark作业主要是根据我们编写的业务处理代码,生成一系列相互依赖的调度阶段,之后将调度阶段中的任务提交Executor的执行的过程。
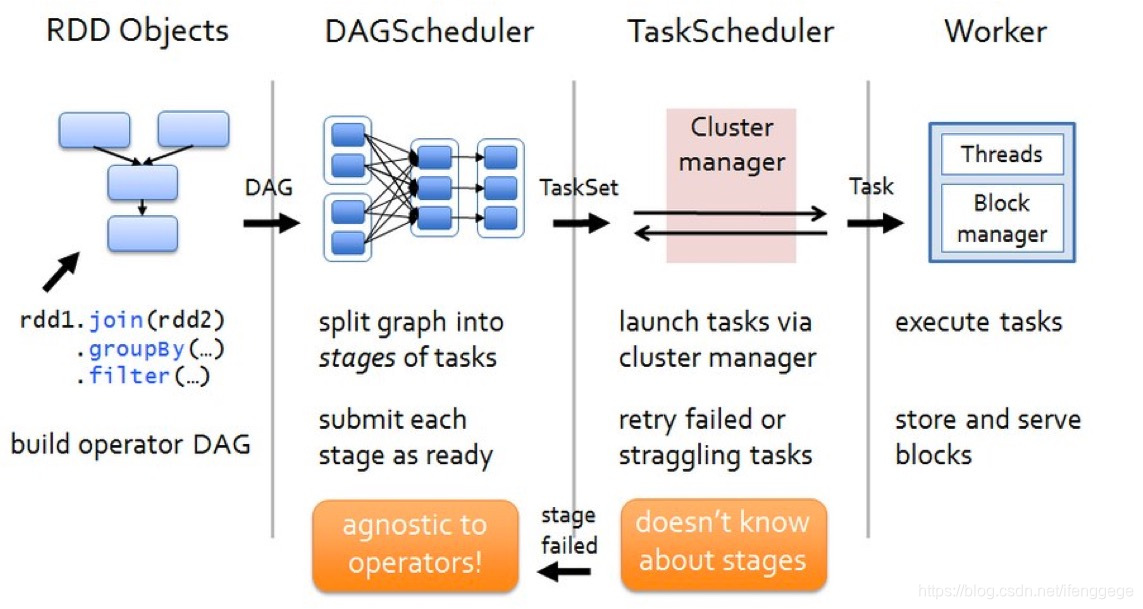
上图是spark作业运行流程图。主要分为四块:

构建DAG
行动操作触发提交作业,提交之后根据依赖关系构造DAG。
划分调度阶段、提交调度阶段
DAGScheduler中根据宽依赖划分调度阶段(stage)。每个stage包含多个task,组成taskset提交给TaskScheduler执行
通过集群管理器启动任务
TaskScheduler收到DAGScheduler提交的任务集,以任务的形式一个个分发到Executor中进行执行。
Executor端执行任务,完成后存储报告结果
Executor接到任务后,扔到线程池中执行任务。任务完成后,报告结果给Driver。
源码解析
从以下的代码展开叙述:
def main(args: Array[String]): Unit = {
val sc = new SparkContext("local", "word-count", new SparkConf())
val words = Seq("hello spark", "hello scala", "hello java")
val rdd = sc.makeRDD(words)
rdd
.flatMap(_.split(" "))
.map((_, 1))
.reduceByKey(_ + _)
.sortByKey()
.foreach(println(_))
}这是一个简单的WordCount案例。首先根据序列生成RDD,再经过一系列算子调用计算word的个数,之后再进行排序,输出结果。
作业提交
上面的代码中,flatMap、map、reduceByKey、sortByKey都是转化算子,不会触发计算;foreach是行动算子,会提交作业,触发计算。
看看foreach的内部的实现:
def foreach(f: T => Unit): Unit = withScope {
val cleanF = sc.clean(f)
// 将当前rdd引用和我们编写的函数传给sc.runJob
sc.runJob(this, (iter: Iterator[T]) => iter.foreach(cleanF))
}
// 以下runJob函数都是SparkContext内部的重载函数
def runJob[T, U: ClassTag](rdd: RDD[T], func: Iterator[T] => U): Array[U] = {
// 添加分区信息
runJob(rdd, func, 0 until rdd.partitions.length)
}
def runJob[T, U: ClassTag](
rdd: RDD[T],
func: Iterator[T] => U,
partitions: Seq[Int]): Array[U] = {
val cleanedFunc = clean(func)
runJob(rdd, (ctx: TaskContext, it: Iterator[T]) => cleanedFunc(it), partitions)
}
def runJob[T, U: ClassTag](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int]): Array[U] = {
// 创建一个数组来保存结果
val results = new Array[U](partitions.size)
runJob[T, U](rdd, func, partitions, (index, res) => results(index) = res)
results
}
// 多次调用runJob,之后将调用DAGScheduler的runJob提交作业
def runJob[T, U: ClassTag](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
// 任务成功后的处理函数
resultHandler: (Int, U) => Unit): Unit = {
if (stopped.get()) {
throw new IllegalStateException("SparkContext has been shutdown")
}
val callSite = getCallSite
val cleanedFunc = clean(func)
logInfo("Starting job: " + callSite.shortForm)
if (conf.getBoolean("spark.logLineage", false)) {
logInfo("RDD's recursive dependencies:\n" + rdd.toDebugString)
}
// 调用DAGScheduler.runJob提交作业
dagScheduler.runJob(rdd, cleanedFunc, partitions, callSite, resultHandler, localProperties.get)
progressBar.foreach(_.finishAll())
rdd.doCheckpoint()
}foreach内部调用了SparkContext.runJob()提交作业,SparkContext内部反复调用了几次重载的runJob方法。
runJob最终的参数中有当前rdd的引用、处理逻辑函数、分区数等,之后调用DagScheduler.runJob()提交作业。
现在再来到DagScheduler.runJob(),看看内部调用:
def runJob[T, U](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
callSite: CallSite,
resultHandler: (Int, U) => Unit,
properties: Properties): Unit = {
val start = System.nanoTime
// 提交作业
// waiter是等待DAGScheduler作业完成的对象。
// 任务完成后,它将结果传递给给定的处理函数
val waiter = submitJob(rdd, func, partitions, callSite, resultHandler, properties)
ThreadUtils.awaitReady(waiter.completionFuture, Duration.Inf)
waiter.completionFuture.value.get match {
case scala.util.Success(_) =>
case scala.util.Failure(exception) =>
val callerStackTrace = Thread.currentThread().getStackTrace.tail
exception.setStackTrace(exception.getStackTrace ++ callerStackTrace)
throw exception
}
}
// 提交job,划分调度阶段
def submitJob[T, U](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
callSite: CallSite,
resultHandler: (Int, U) => Unit,
properties: Properties): JobWaiter[U] = {
// 检查以确保我们没有在不存在的分区上启动任务。
val maxPartitions = rdd.partitions.length
partitions.find(p => p >= maxPartitions || p < 0).foreach { p =>
throw new IllegalArgumentException(
"Attempting to access a non-existent partition: " + p + ". " +
"Total number of partitions: " + maxPartitions)
}
// 为当前job获取id
val jobId = nextJobId.getAndIncrement()
// 如果分区为0,返回一个空job
if (partitions.size == 0) {
return new JobWaiter[U](this, jobId, 0, resultHandler)
}
assert(partitions.size > 0)
val func2 = func.asInstanceOf[(TaskContext, Iterator[_]) => _]
// 封装waiter,用于在执行结束时,回调处理结果
val waiter = new JobWaiter(this, jobId, partitions.size, resultHandler)
// eventProcessLoop是用于提交/接收DAG调度事件的事件环
// 提交作业,告知DAGScheduler开始划分调度阶段。
eventProcessLoop.post(JobSubmitted(
jobId, rdd, func2, partitions.toArray, callSite, waiter,
SerializationUtils.clone(properties)))
waiter
}内部调用了submitJob(),发送提交作业的消息到DAGScheduler的eventProcessLoop事件环中。
划分&提交调度阶段
eventProcessLoop是用于接收调度事件的调度环,对应的类是DAGSchedulerEventProcessLoop。
内部通过模式匹配接收消息,作出相应处理。接收到提交作业的消息后,调用dagScheduler.handleJobSubmitted()开始划分调度阶段、提交调度阶段。
private def doOnReceive(event: DAGSchedulerEvent): Unit = event match {
// 匹配提交作业的消息
case JobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties) =>
dagScheduler.handleJobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties)
}看看dagScheduler.handleJobSubmitted()内部:
private[scheduler] def handleJobSubmitted(jobId: Int,
finalRDD: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
callSite: CallSite,
listener: JobListener,
properties: Properties) {
var finalStage: ResultStage = null
try {
// 根据依赖关系创建ResultStage
finalStage = createResultStage(finalRDD, func, partitions, jobId, callSite)
} catch {
...
}
// 提交作业,清除内部数据
barrierJobIdToNumTasksCheckFailures.remove(jobId)
// 通过jobId, finalStage创建job
val job = new ActiveJob(jobId, finalStage, callSite, listener, properties)
val jobSubmissionTime = clock.getTimeMillis()
// 将job存入jobId映射到job的map中
jobIdToActiveJob(jobId) = job
activeJobs += job
finalStage.setActiveJob(job)
val stageIds = jobIdToStageIds(jobId).toArray
val stageInfos = stageIds.flatMap(id => stageIdToStage.get(id).map(_.latestInfo))
listenerBus.post(
SparkListenerJobStart(job.jobId, jobSubmissionTime, stageInfos, properties))
// 提交调度阶段
submitStage(finalStage)
}handleJobSubmitted主要分为两块,一块是根据依赖生成ResultStage,一块是提交ResultStage。
生成ResultStage
先看一下生成ResultStage,也就是createResultStage方法。
private def createResultStage(
rdd: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
jobId: Int,
callSite: CallSite): ResultStage = {
checkBarrierStageWithDynamicAllocation(rdd)
checkBarrierStageWithNumSlots(rdd)
checkBarrierStageWithRDDChainPattern(rdd, partitions.toSet.size)
// 先获取当前rdd的父调度阶段
val parents = getOrCreateParentStages(rdd, jobId)
val id = nextStageId.getAndIncrement()
val stage = new ResultStage(id, rdd, func, partitions, parents, jobId, callSite)
stageIdToStage(id) = stage
updateJobIdStageIdMaps(jobId, stage)
stage
}
会首先获取当前RDD的父阶段,获取后根据父阶段,创建ResultStage。
这里注意一下,这里的rdd是ShuffledRDD的引用。因为我们foreach触发计算的时候,将调用rdd的引用传了进来,也就是sortByKey生成的ShuffledRDD的引用。
接着看getOrCreateParentStages()是怎么获取当前RDD的父阶段的:
private def getOrCreateParentStages(rdd: RDD[_], firstJobId: Int): List[Stage] = {
// 获取宽依赖,之后根据获取的宽依赖,创建对应的ShuffleMapStage
getShuffleDependencies(rdd).map { shuffleDep =>
getOrCreateShuffleMapStage(shuffleDep, firstJobId)
}.toList
}
// 获取当前RDD的宽依赖
// 返回作为给定RDD的直接父级的shuffle依赖项
// 此函数将不会返回更远的祖先。例如,如果C对B具有宽依赖性,而B对A具有宽依赖性
// A <-- B <-- C
// 用rdd C调用此函数只会返回B <-C依赖项。
private[scheduler] def getShuffleDependencies(
rdd: RDD[_]): HashSet[ShuffleDependency[_, _, _]] = {
val parents = new HashSet[ShuffleDependency[_, _, _]]
val visited = new HashSet[RDD[_]]
val waitingForVisit = new ArrayStack[RDD[_]]
waitingForVisit.push(rdd)
while (waitingForVisit.nonEmpty) {
val toVisit = waitingForVisit.pop()
if (!visited(toVisit)) {
visited += toVisit
toVisit.dependencies.foreach {
case shuffleDep: ShuffleDependency[_, _, _] =>
parents += shuffleDep
case dependency =>
waitingForVisit.push(dependency.rdd)
}
}
}
parents
}
// 如果shuffle map stage已在shuffleIdToMapStage中存在,则获取
// 不存在的话,将创建shuffle map stage
private def getOrCreateShuffleMapStage(
shuffleDep: ShuffleDependency[_, _, _],
firstJobId: Int): ShuffleMapStage = {
shuffleIdToMapStage.get(shuffleDep.shuffleId) match {
case Some(stage) =>
stage
case None =>
// 查找尚未在shuffleToMapStage中注册的祖先shuffle依赖项,
// 并为它创建shuffle map stage
getMissingAncestorShuffleDependencies(shuffleDep.rdd).foreach { dep =>
if (!shuffleIdToMapStage.contains(dep.shuffleId)) {
createShuffleMapStage(dep, firstJobId)
}
}
// 为当前shuffle依赖创建shuffle map stage
createShuffleMapStage(shuffleDep, firstJobId)
}
}getOrCreateParentStages中先调用getShuffleDependencies(),获取当前RDD的宽依赖;获取后,调用getOrCreateShuffleMapStage()为宽依赖创建stage(如果stage已存在就直接获取)。
先说一下getShuffleDependencies方法,如代码注释所说:返回作为给定RDD的直接父级的shuffle依赖项,不会返回整个DAG上所有的宽依赖。另外说一下,getShuffleDependencies这种写法感觉极度舒适,之后还有一个方法也是这么写。
我们传入的RDD是sortByKey生成的ShuffleRDD实例,调用getShuffleDependencies就会返回ShuffleDependency。
再说一下getOrCreateShuffleMapStage方法,它为返回的ShuffleDependency创建shuffle map stage。
它内部会在shuffleIdToMapStage中找当前ShuffleDependency是否存在stage,如果存在则返回,不存在则创建。
在创建之前,首先会调用getMissingAncestorShuffleDependencies()获取当前依赖的所有祖先宽依赖,并判断他们是否存在对应的调度阶段,如果不存在则调用createShuffleMapStage()创建。确保所有祖先宽依赖都存在对应的调度阶段后,调用createShuffleMapStage()为当前ShuffleDependency创建stage。
看看getMissingAncestorShuffleDependencies和createShuffleMapStage的实现:
// 查找所有尚未在shuffleToMapStage中注册的祖先shuffle依赖项
private def getMissingAncestorShuffleDependencies(
rdd: RDD[_]): ArrayStack[ShuffleDependency[_, _, _]] = {
val ancestors = new ArrayStack[ShuffleDependency[_, _, _]]
val visited = new HashSet[RDD[_]]
val waitingForVisit = new ArrayStack[RDD[_]]
waitingForVisit.push(rdd)
while (waitingForVisit.nonEmpty) {
val toVisit = waitingForVisit.pop()
if (!visited(toVisit)) {
visited += toVisit
// 获取宽依赖
getShuffleDependencies(toVisit).foreach { shuffleDep =>
if (!shuffleIdToMapStage.contains(shuffleDep.shuffleId)) {
ancestors.push(shuffleDep)
waitingForVisit.push(shuffleDep.rdd)
}
}
}
}
ancestors
}
// 为shuffle依赖创建shuffle map stage
def createShuffleMapStage(shuffleDep: ShuffleDependency[_, _, _], jobId: Int): ShuffleMapStage = {
val rdd = shuffleDep.rdd
checkBarrierStageWithDynamicAllocation(rdd)
checkBarrierStageWithNumSlots(rdd)
checkBarrierStageWithRDDChainPattern(rdd, rdd.getNumPartitions)
val numTasks = rdd.partitions.length
val parents = getOrCreateParentStages(rdd, jobId)
val id = nextStageId.getAndIncrement()
val stage = new ShuffleMapStage(
id, rdd, numTasks, parents, jobId, rdd.creationSite, shuffleDep, mapOutputTracker)
stageIdToStage(id) = stage
// 创建stage时会将stage放入shuffleId映射到stage的Map中
shuffleIdToMapStage(shuffleDep.shuffleId) = stage
updateJobIdStageIdMaps(jobId, stage)
if (!mapOutputTracker.containsShuffle(shuffleDep.shuffleId)) {
mapOutputTracker.registerShuffle(shuffleDep.shuffleId, rdd.partitions.length)
}
stage
}getMissingAncestorShuffleDependencies和getShuffleDependencies的实现方法类似,返回所有尚未在shuffleToMapStage中注册的祖先shuffle依赖项。createShuffleMapStage为shuffle dependency创建shuffle map stage。
到此,getOrCreateParentStages的步骤就走完了,也就获取到了当前rdd的父阶段。
视线回到createResultStage方法中来:
val stage = new ResultStage(id, rdd, func, partitions, parents, jobId, callSite)将stageId、rdd、处理逻辑方法、分区、父调度阶段等作为参数构造ResultStage。ResultStage就生成成功了。
提交ResultStage
在handleJobSubmitted方法中,调用submitStage()将生成的ResultStage提交。
看看submitStage内部:
// 提交阶段,但首先递归提交所有丢失的父阶段
private def submitStage(stage: Stage) {
val jobId = activeJobForStage(stage)
if (jobId.isDefined) {
logDebug("submitStage(" + stage + ")")
// 如果当前阶段不是在等待&不是在运行&没有结束,开始运行
if (!waitingStages(stage) && !runningStages(stage) && !failedStages(stage)) {
val missing = getMissingParentStages(stage).sortBy(_.id)
logDebug("missing: " + missing)
if (missing.isEmpty) {
logInfo("Submitting " + stage + " (" + stage.rdd + "), which has no missing parents")
submitMissingTasks(stage, jobId.get)
} else {
for (parent <- missing) {
submitStage(parent)
}
waitingStages += stage
}
}
} else {
abortStage(stage, "No active job for stage " + stage.id, None)
}
}submitStage先调用getMissingParentStages获取所有丢失的父阶段。
如果没有丢失的父阶段,才会调用submitMissingTasks()提交当前阶段的任务集;如果存在丢失的父阶段,则递归调用submitStage先提交父阶段。
getMissingParentStages的实现方式和getShuffleDependencies也类似,这里就不看了,它的作用就是获取所有丢失的父阶段。
再大致说一下submitMissingTasks()是怎么提交任务的:
val tasks: Seq[Task[_]] = try {
stage match {
case stage: ShuffleMapStage =>
stage.pendingPartitions.clear()
partitionsToCompute.map { id =>
val locs = taskIdToLocations(id)
val part = partitions(id)
stage.pendingPartitions += id
// 创建shuffleMapTask
new ShuffleMapTask(stage.id, stage.latestInfo.attemptNumber,
taskBinary, part, locs, properties, serializedTaskMetrics, Option(jobId),
Option(sc.applicationId), sc.applicationAttemptId, stage.rdd.isBarrier())
}
case stage: ResultStage =>
partitionsToCompute.map { id =>
val p: Int = stage.partitions(id)
val part = partitions(p)
val locs = taskIdToLocations(id)
// 创建ResultTask
new ResultTask(stage.id, stage.latestInfo.attemptNumber,
taskBinary, part, locs, id, properties, serializedTaskMetrics,
Option(jobId), Option(sc.applicationId), sc.applicationAttemptId,
stage.rdd.isBarrier())
}
}
}
if (tasks.size > 0) {
// 调用taskScheduler.submitTasks()提交task
taskScheduler.submitTasks(new TaskSet(
tasks.toArray, stage.id, stage.latestInfo.attemptNumber, jobId, properties))
}submitMissingTasks内部根据ShuffleMapStage和ResultStage分别生成ShuffleMapTask和ResultTask。
之后将task封装为TaskSet,调用TaskScheduler.submitTasks()提交任务。
到这里,划分和提交调度阶段已经走完了。接下来开始看提交任务的源码。
提交任务
上面调用了TaskScheduler.submitTasks()提交任务,TaskScheduler是特质,真正方法实现在类TaskSchedulerImpl中,我们看看内部实现:
override def submitTasks(taskSet: TaskSet) {
val tasks = taskSet.tasks
this.synchronized {
// 为该TaskSet创建TaskSetManager,管理这个任务集的生命周期
val manager = createTaskSetManager(taskSet, maxTaskFailures)
val stage = taskSet.stageId
val stageTaskSets =
taskSetsByStageIdAndAttempt.getOrElseUpdate(stage, new HashMap[Int, TaskSetManager])
stageTaskSets.foreach { case (_, ts) =>
ts.isZombie = true
}
stageTaskSets(taskSet.stageAttemptId) = manager
// 将该任务集的管理器加入到系统调度池中去,由系统统一调度
schedulableBuilder.addTaskSetManager(manager, manager.taskSet.properties)
if (!isLocal && !hasReceivedTask) {
starvationTimer.scheduleAtFixedRate(new TimerTask() {
override def run() {
if (!hasLaunchedTask) {
logWarning("Initial job has not accepted any resources; " +
"check your cluster UI to ensure that workers are registered " +
"and have sufficient resources")
} else {
this.cancel()
}
}
}, STARVATION_TIMEOUT_MS, STARVATION_TIMEOUT_MS)
}
hasReceivedTask = true
}
backend.reviveOffers()
}会首先为每个TaskSet创建TaskSetManager用于管理整个TaskSet的生命周期,并调用schedulableBuilder.addTaskSetManager将任务集管理器添加到系统调度池中去,之后调用SchedulerBackend.reviveOffers()分配资源并运行
看一下SchedulerBackend的其中一个子类CoarseGrainedSchedulerBackend的实现:
override def reviveOffers() {
// 向Driver发送ReviveOffsers的消息
driverEndpoint.send(ReviveOffers)
}内部会向Driver终端点发送ReviveOffers的消息,分配资源并运行。
CoarseGrainedSchedulerBackend的实例就是代表Driver端的守护进程,其实也相当于自己发给自己。
接收到ReviveOffers的消息后,会调用makeOffers()。
看看makeOffers()实现:
private def makeOffers() {
val taskDescs = withLock {
// 获取集群中可用的Executor列表
val activeExecutors = executorDataMap.filterKeys(executorIsAlive)
val workOffers = activeExecutors.map {
case (id, executorData) =>
new WorkerOffer(id, executorData.executorHost, executorData.freeCores,
Some(executorData.executorAddress.hostPort))
}.toIndexedSeq
// 分配运行资源
scheduler.resourceOffers(workOffers)
}
if (!taskDescs.isEmpty) {
// 提交任务
launchTasks(taskDescs)
}
}makeOffers()内部会先获取所有可用的Executor列表,然后调用TaskSchedulerImpl.resourceOffers()分配资源,分配资源完成后,调用launchTask()提交任务。
看看TaskSchedulerImpl.resourceOffers()的实现:
// 由集群管理器调用以在slave上提供资源。
def resourceOffers(offers: IndexedSeq[WorkerOffer]): Seq[Seq[TaskDescription]] = synchronized {
//将每个slave标记为活动并记住其主机名, 还跟踪是否添加了新的Executor
var newExecAvail = false
for (o <- offers) {
if (!hostToExecutors.contains(o.host)) {
hostToExecutors(o.host) = new HashSet[String]()
}
if (!executorIdToRunningTaskIds.contains(o.executorId)) {
hostToExecutors(o.host) += o.executorId
executorAdded(o.executorId, o.host)
executorIdToHost(o.executorId) = o.host
executorIdToRunningTaskIds(o.executorId) = HashSet[Long]()
newExecAvail = true
}
for (rack <- getRackForHost(o.host)) {
hostsByRack.getOrElseUpdate(rack, new HashSet[String]()) += o.host
}
}
// 移除黑名单中的节点
blacklistTrackerOpt.foreach(_.applyBlacklistTimeout())
val filteredOffers = blacklistTrackerOpt.map { blacklistTracker =>
offers.filter { offer =>
!blacklistTracker.isNodeBlacklisted(offer.host) &&
!blacklistTracker.isExecutorBlacklisted(offer.executorId)
}
}.getOrElse(offers)
// 为任务随机分配Executor,避免任务集中分配到Worker上
val shuffledOffers = shuffleOffers(filteredOffers)
// 存储已分配好的任务
val tasks = shuffledOffers.map(o => new ArrayBuffer[TaskDescription](o.cores / CPUS_PER_TASK))
val availableCpus = shuffledOffers.map(o => o.cores).toArray
val availableSlots = shuffledOffers.map(o => o.cores / CPUS_PER_TASK).sum
// 获取按照调度策略排序好的TaskSetManager
val sortedTaskSets = rootPool.getSortedTaskSetQueue
for (taskSet <- sortedTaskSets) {
logDebug("parentName: %s, name: %s, runningTasks: %s".format(
taskSet.parent.name, taskSet.name, taskSet.runningTasks))
if (newExecAvail) {
taskSet.executorAdded()
}
}
// 为排好序的TaskSetManager列表进行分配资源。分配的原则是就近原则,按照顺序为PROCESS_LOCAL、NODE_LOCAL、NO_PREF、RACK_LOCAL、ANY
for (taskSet <- sortedTaskSets) {
if (taskSet.isBarrier && availableSlots < taskSet.numTasks) {
...
} else {
var launchedAnyTask = false
val addressesWithDescs = ArrayBuffer[(String, TaskDescription)]()
for (currentMaxLocality <- taskSet.myLocalityLevels) {
var launchedTaskAtCurrentMaxLocality = false
do {
launchedTaskAtCurrentMaxLocality = resourceOfferSingleTaskSet(taskSet,
currentMaxLocality, shuffledOffers, availableCpus, tasks, addressesWithDescs)
launchedAnyTask |= launchedTaskAtCurrentMaxLocality
} while (launchedTaskAtCurrentMaxLocality)
}
...
}
}
if (tasks.size > 0) {
hasLaunchedTask = true
}
return tasks
}
resourceOffers中按照调度策略、就近原则为Task分配资源,返回分配好资源的Task。
分配好资源后,调用launchTasks()提交任务。
private def launchTasks(tasks: Seq[Seq[TaskDescription]]) {
for (task <- tasks.flatten) {
// 序列化任务
val serializedTask = ser.serialize(task)
if (serializedTask.limit >= maxRpcMessageSize) {
...
}
else {
val executorData = executorDataMap(task.executorId)
executorData.freeCores -= scheduler.CPUS_PER_TASK
// 向Executor所在节点终端发送LaunchTask的消息
executorData.executorEndpoint.send(LaunchTask(new SerializableBuffer(serializedTask)))
}
}
}
launchTasks内部先将任务序列化,之后把任务一个个的发送到对应的CoarseGrainedExecutorBackend进行执行。
至此任务就提交完成了,接下来看Executor是如何执行任务的。
执行任务
CoarseGrainedExecutorBackend接收到LaunchTask消息后,会调用Executor.launchTask()执行任务。
override def receive: PartialFunction[Any, Unit] = {
case LaunchTask(data) =>
if (executor == null) {
exitExecutor(1, "Received LaunchTask command but executor was null")
} else {
val taskDesc = TaskDescription.decode(data.value)
logInfo("Got assigned task " + taskDesc.taskId)
// 调用Executor.launchTask执行任务
executor.launchTask(this, taskDesc)
}
}看看Executor.launchTask的实现:
def launchTask(context: ExecutorBackend, taskDescription: TaskDescription): Unit = {
// 将Task封装到TaskRunner中
val tr = new TaskRunner(context, taskDescription)
runningTasks.put(taskDescription.taskId, tr)
// 将TaskRunner扔到线程池中进行执行
threadPool.execute(tr)
}launchTask中会将Task封装到TaskRunner中,然后把TaskRunner扔到线程池中进行执行。
TaskRunner是一个线程类,看一下它run方法的操作:
override def run(): Unit = {
threadId = Thread.currentThread.getId
Thread.currentThread.setName(threadName)
val threadMXBean = ManagementFactory.getThreadMXBean
val taskMemoryManager = new TaskMemoryManager(env.memoryManager, taskId)
val deserializeStartTime = System.currentTimeMillis()
val deserializeStartCpuTime = if (threadMXBean.isCurrentThreadCpuTimeSupported) {
threadMXBean.getCurrentThreadCpuTime
} else 0L
Thread.currentThread.setContextClassLoader(replClassLoader)
val ser = env.closureSerializer.newInstance()
// 开始运行
execBackend.statusUpdate(taskId, TaskState.RUNNING, EMPTY_BYTE_BUFFER)
var taskStartTime: Long = 0
var taskStartCpu: Long = 0
startGCTime = computeTotalGcTime()
try {
// 反序列化任务
task = ser.deserialize[Task[Any]](
taskDescription.serializedTask, Thread.currentThread.getContextClassLoader)
// value是返回结果
val value = Utils.tryWithSafeFinally {
// 调用Task.run运行Task,并获取返回结果
val res = task.run(
taskAttemptId = taskId,
attemptNumber = taskDescription.attemptNumber,
metricsSystem = env.metricsSystem)
threwException = false
res
} {
val releasedLocks = env.blockManager.releaseAllLocksForTask(taskId)
val freedMemory = taskMemoryManager.cleanUpAllAllocatedMemory()
}
val resultSer = env.serializer.newInstance()
val beforeSerialization = System.currentTimeMillis()
val valueBytes = resultSer.serialize(value)
val afterSerialization = System.currentTimeMillis()
val directResult = new DirectTaskResult(valueBytes, accumUpdates)
val serializedDirectResult = ser.serialize(directResult)
val resultSize = serializedDirectResult.limit()
// 执行结果的处理
val serializedResult: ByteBuffer = {
// 结果大于maxResultSize,直接丢弃;这个值通过spark.driver.maxResultSize进行设置
if (maxResultSize > 0 && resultSize > maxResultSize) {
ser.serialize(new IndirectTaskResult[Any](TaskResultBlockId(taskId), resultSize))
}
// 结果大于maxDirectResultSize,存放到BlockManager中,然后将BlockId发送到Driver
else if (resultSize > maxDirectResultSize) {
val blockId = TaskResultBlockId(taskId)
env.blockManager.putBytes(
blockId,
new ChunkedByteBuffer(serializedDirectResult.duplicate()),
StorageLevel.MEMORY_AND_DISK_SER)
ser.serialize(new IndirectTaskResult[Any](blockId, resultSize))
}
// 直接将结果发到Driver
else {
serializedDirectResult
}
}
// 任务执行完成,调用CoarseGrainedExecutorBackend.statusUpdate
execBackend.statusUpdate(taskId, TaskState.FINISHED, serializedResult)
} catch {
...
} finally {
runningTasks.remove(taskId)
}
}
run方法中,会将任务反序列化,然后调用Task.run()执行Task;执行完成后获取执行结果,根据结果的大小分情况处理,之后调用CoarseGrainedExecutorBackend.statusUpdate()向Driver汇报执行结果。
Task的run方法中,会调用runTask()执行任务。
Task是抽象类,没有对runTask()进行实现。具体的实现是由ShuffleMapTask和ResultTask进行的。
先看看ShuffleMapTask的runTask的实现:
override def runTask(context: TaskContext): MapStatus = {
val threadMXBean = ManagementFactory.getThreadMXBean
val deserializeStartTime = System.currentTimeMillis()
val deserializeStartCpuTime = if (threadMXBean.isCurrentThreadCpuTimeSupported) {
threadMXBean.getCurrentThreadCpuTime
} else 0L
// 反序列化
val ser = SparkEnv.get.closureSerializer.newInstance()
val (rdd, dep) = ser.deserialize[(RDD[_], ShuffleDependency[_, _, _])](
ByteBuffer.wrap(taskBinary.value), Thread.currentThread.getContextClassLoader)
_executorDeserializeTime = System.currentTimeMillis() - deserializeStartTime
_executorDeserializeCpuTime = if (threadMXBean.isCurrentThreadCpuTimeSupported) {
threadMXBean.getCurrentThreadCpuTime - deserializeStartCpuTime
} else 0L
var writer: ShuffleWriter[Any, Any] = null
try {
val manager = SparkEnv.get.shuffleManager
writer = manager.getWriter[Any, Any](dep.shuffleHandle, partitionId, context)
// 执行计算,并将结果写入本地系统的BlockManager中
writer.write(rdd.iterator(partition, context).asInstanceOf[Iterator[_ <: Product2[Any, Any]]])
// 关闭writer,返回计算结果
// 返回包含了数据的location和size元数据信息的MapStatus信息
writer.stop(success = true).get
} catch {
}
}
ShuffleMapTask会将计算结果写入到BlockManager中,最终会返回包含相关元数据信息的MapStatus。MapStatus将成为下一阶段获取输入数据时的依据。
再看看ResultTask的runTask的实现:
override def runTask(context: TaskContext): U = {
// Deserialize the RDD and the func using the broadcast variables.
val threadMXBean = ManagementFactory.getThreadMXBean
val deserializeStartTime = System.currentTimeMillis()
val deserializeStartCpuTime = if (threadMXBean.isCurrentThreadCpuTimeSupported) {
threadMXBean.getCurrentThreadCpuTime
} else 0L
val ser = SparkEnv.get.closureSerializer.newInstance()
// 反序列化
val (rdd, func) = ser.deserialize[(RDD[T], (TaskContext, Iterator[T]) => U)](
ByteBuffer.wrap(taskBinary.value), Thread.currentThread.getContextClassLoader)
_executorDeserializeTime = System.currentTimeMillis() - deserializeStartTime
_executorDeserializeCpuTime = if (threadMXBean.isCurrentThreadCpuTimeSupported) {
threadMXBean.getCurrentThreadCpuTime - deserializeStartCpuTime
} else 0L
// 执行func进行计算
func(context, rdd.iterator(partition, context))
}ResultTask会直接执行封装进来的func函数,返回计算结果。
执行完成后,调用CoarseGrainedExecutorBackend.statusUpdate()。statusUpdate方法中向Driver终端点发送StatusUpdate的消息汇报任务执行结果。
结果处理
Driver接到StatusUpdate消息后,调用TaskSchedulerImpl.statusUpdate()进行处理
override def receive: PartialFunction[Any, Unit] = {
case StatusUpdate(executorId, taskId, state, data) =>
// 调用statusUpdate处理
scheduler.statusUpdate(taskId, state, data.value)
if (TaskState.isFinished(state)) {
executorDataMap.get(executorId) match {
case Some(executorInfo) =>
executorInfo.freeCores += scheduler.CPUS_PER_TASK
makeOffers(executorId)
case None =>
》。
}
}
}看看statusUpdate方法:
def statusUpdate(tid: Long, state: TaskState, serializedData: ByteBuffer) {
var failedExecutor: Option[String] = None
var reason: Option[ExecutorLossReason] = None
synchronized {
try {
taskIdToTaskSetManager.get(tid) match {
case Some(taskSet) =>
// 如果FINISHED,调用taskResultGetter.enqueueSuccessfulTask()
if (TaskState.isFinished(state)) {
cleanupTaskState(tid)
taskSet.removeRunningTask(tid)
if (state == TaskState.FINISHED) {
taskResultGetter.enqueueSuccessfulTask(taskSet, tid, serializedData)
} else if (Set(TaskState.FAILED, TaskState.KILLED, TaskState.LOST).contains(state)) {
taskResultGetter.enqueueFailedTask(taskSet, tid, state, serializedData)
}
}
case None =>
....
}
} catch {
}
}
}
statusUpdate内部会根据任务的状态不同做不同处理,这里只说一下任务是FINISHED的情况。
如果状态是TaskState.FINISHED,调用TaskResultGetter的enqueueSuccessfulTask方法处理。
enqueueSuccessfulTask内部根据结果类型进行处理。如果是IndirectTaskResult,通过blockid从远程获取结果;如果DirectTaskResult,那么无需远程获取。
如果任务是ShuffleMapTask,需要将结果告知下游调度阶段,以便作为后续调度阶段的输入。
这个是在DAGScheduler的handleTaskCompletion中实现的,将MapStatus注册到MapOutputTrackerMaster中,从而完成ShuffleMapTask的处理
如果任务是ResultTask,如果完成,直接标记作业已经完成。
至此整个流程就走了一遍了。
在任务资源分配和结果处理说的有点不清晰,但对于了解整个任务执行流程没有很大影响。
end.
以上是结合看书以及看源码写的流程,如有偏差,欢迎交流指正。
Reference
《图解Spark核心技术与案例实战》
个人公众号:码农峰,定时推送行业资讯,持续发布原创技术文章,欢迎大家关注。