前言
本篇博客出于学习交流目的,主要是用来记录自己学习中遇到的问题和心路历程,方便之后回顾。过程中可能引用其他大牛的博客,文末会给出相应链接,侵删!
DeepFool算法
特点:两种黑箱算法,即UPSET和ANGRI
论文原文:UPSET and ANGRI : Breaking High Performance Image Classifiers
正文
一些对抗样本的基础知识在这里就不赘述了,可以看我之前的博客。
先介绍两种算法的主要部分,具体网络结构以及共用同样的损失评价函数,在后面介绍。
UPSET: Universal Perturbations for Steering to Exact Targets
类标:
对抗扰动:
,
即生成第j个目标分类的扰动
残差生成网络:
,
原始样本:
对抗样本:
,生成公式如下
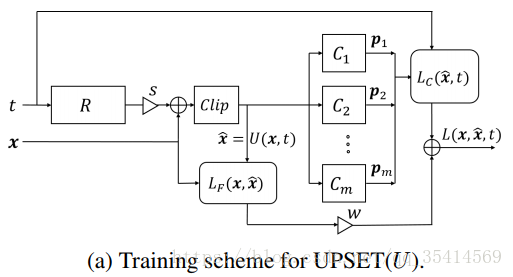
整体训练策略如下图所示,误差函数之后解释。
ANGRI: Antagonistic Network for Generating Rogue Images
原始样本:
正确类别:
目标类别:
,
对抗样本:
生成公式如下
整体训练策略如下图所示,误差函数之后解释。
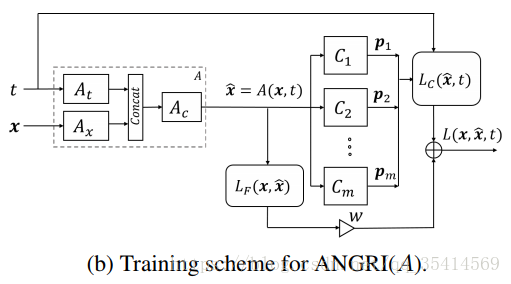
损失函数(以上两个方法都用的这个损失评估函数)
有
个预训练的分类器
,表示对抗样本
输出的分类概率
,
误差函数由两部分组成, 表示分类器损失, 表示保真度损失。
对不能产生目标攻击类进行惩罚。
保证输出的对抗样本和原始样本足够相似。
权重 用来折中两个损失指标的, 的选择应该使它不会促进稀疏性,否则一些小的区域会很明显。如果 ,那么就是 范数,可以由 替换。
评价指标:
Targeted fooling rate (TFR):
,
Misclassification rate (MR):
,
Fidelity score (FS):每个像素在每个通道下的平均残差范数
Confidence (C):成功欺骗为目标类时的平均概率,是一个置信度指标。