什么是“对抗样本攻击”
笔者给“对抗样本攻击”下的定义是:通过精心的构造原始数据,使得机器学习模型以较大概率返回和事实相反的结果。
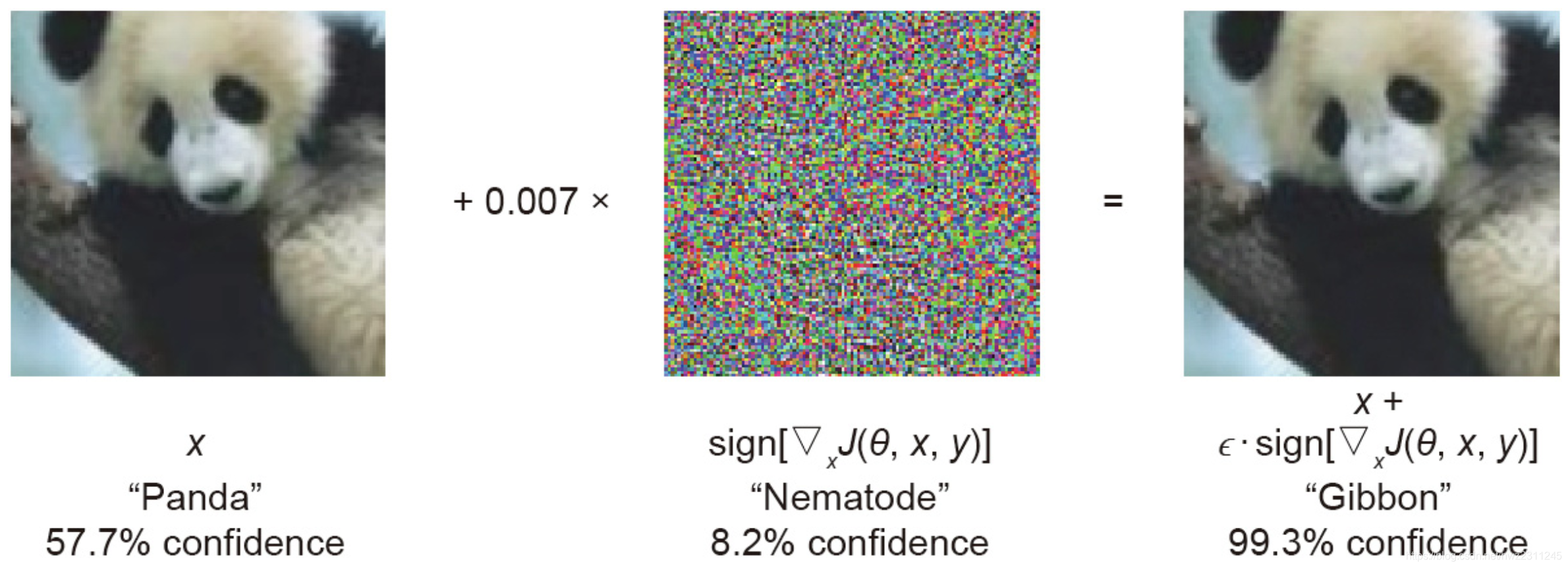
最经典的例子就是对于图像、人脸识别系统的攻击样本了。比如
- 加入一些噪点,让GoogleNet把“熊猫”当成“长臂猿”:
- 带上一个眼睛,让人脸识别模型连性别都搞错:

“对抗样本攻击”的现实意义
上面这些例子,简单看起来很恐怖,因为和事实偏差极大。但在此需要强调的是,对抗样本攻击的可怕之处,不仅仅在于它使得模型结果和事实偏差极大,更在于它可以将这种偏差变成必然:上面的例子仅仅是个例,事实上,任何机器学习算法都无法保障100%的准确率,因此,有个别的失误其实并不说明什么。但是,研究表明,通过对抗样本攻击,可以让一个准确率90%的图像识别算法,直接把准确率降到0%。将偶然变成必然,才是对抗样本攻击,真正可怕的地方。
再来打个比方。2015年,全球航班失事的概率是1/200万,每638万坐飞机的就有一个死于空难。这个概率显然非常低,低到让你甘于冒1/638万的风险,仍然去选择飞机的便利性。即使告诉你每年都有人死于空难的事实,也并不会影响你的选择。但是,想象一下,如果这个概率变成一个人为可控的必然事件(比如飞机没有安检,恐怖分子可以轻易携带炸药),你的选择是否会发生变化?换一句话说,不论概率上多么完美,一旦这个概率由不可控的偶然变成可控的必然,这个概率基本就失去了它的意义。在各行各业,其实所追求的,都是去尽可能的消除已知的可控因素(如安检、禁止酒驾等)。
为什么会存在“对抗样本攻击”
目前,学术界对于对抗样本的原因分析还没有完全定论,比较主流的观点是:样本维度增加和训练样本不足导致了对抗样本攻击的存在。这里简单谈一下我的理解。
对抗样本的成因在于不确定性,比如“熊猫”的图片到底应该是“熊猫”还是“长臂猿”,是没有明确的判定标准的,只能通过人为经验来进行判决。而对于一个图片所对应的样本空间,显然是极大的(一个128位的黑白图片,样本空间是2^(128*128))。换句话说,任何模型所能得到的训练数据,对比整个样本空间来说,是极其稀疏的。而对于这其中的灰色地带,机器学习只能基于概率分布,去寻求一个最优解。打个比方,我告诉你1是好人,10是坏人,请你确定一个阈值来区分好人和坏人。这个答案显然是模糊的,基于样本的分布,可能最优解的阈值是9。那这个时候漏洞就出现了:8是个坏人,但模型会判定为好人。但由于训练样本的缺乏,并没有足够的数据来帮助模型修正这个错误。而攻击者恰恰可以利用这个知识盲区,对模型发起攻击。