前言
本篇博客出于学习交流目的,主要是用来记录自己学习中遇到的问题和心路历程,方便之后回顾。过程中可能引用其他大牛的博客,文末会给出相应链接,侵删!
对抗样本可转移性与黑盒攻击深入研究
论文原文:Delving into Transferable Adversarial Examples and Black-box Attacks
文章主要研究对抗样本的可转移性以及黑盒攻击下的特性,并且关注点不再只是停留在小样本集,而针对大规模样本集。并在Clarifai.com(最先进的在线分类模型)上实现黑盒攻击。
正文
贡献及创新点:
1、发现对ImageNet数据集的模型现有方法难以实现目标攻击的迁移;
2、提出了一个ensemble-based算法,能够在多个模型下实现样本迁移攻击;
3、首次实现迁移样本对黑盒系统的攻击(Clarifai.com,最先进的在线分类模型),不知道攻击模型的具体参数和训练集,并且类标也十分不同;
4、首次分析大数据模型的几何特性,发现了一些有趣的东西,比如模型间梯度相互正交;
对抗样本的基础知识我就不赘述了,之前写的几篇博客都有。本文使用的生成对抗样本的算法: 权重; 扰动大小
基于优化:
快速梯度法: ,原理类似于DeepFool
FGSM:
注:超参数 在原文中用 表示,为方便,下面我也都用 。
每种算法分别进行目标攻击生成和非目标攻击生成,目标攻击就是把上述公式中的 替换成目标类标 ,并将梯度符号及损失符号变号。
攻击模型: , , , ,
数据集: ILSVRC 2012 validation set ,随机选择100张图像
测量可转移性: 给定两个模型,通过计算一个模型生成的对抗样本在另一个模型上分类正确的百分比,称作accuracy,来测量非目标攻击的可转移性。accuracy越低,说明攻击效果越好。而目标攻击的可转移性计算一个模型生成的对抗样本在另一个模型中分类为指定类别的百分比,称作matching rate。matching rate越高表明目标攻击效果越好。
失真率 (RMSD):评价原始图像和对抗样本之间的失真率,
非目标攻击

如题所示,为基于优化算法和基于快速梯度法的结果,RMED表示最左侧模型得到结果的平均失真率,而表中间每个格则是模型(行)生成的样本在模型(列)上迁移的结果。FGSM得到的结果更差所以就不在这比较。
研究对抗样本的最小可转移RMSD
超参数 和RMSD有着密切的关系,呈正相关。也可以看出,RMSD同可转移性是正相关,即RMSD越大,扰动越强烈,转移性越好。所以要通过控制 来控制最小转移性的RMSD,实现干扰和转移性的折中。
给定一个图像 和两个模型 , ,我们可以近似最小扰动 沿着方向 。有: ; 可以是FGSM中的梯度方向,以此类推;
近似最小转移性的RMSD通过每0.1步对B进行采样的线性查找。

作者给出的实验结果如图所示,VGG-16,ResNet-15;左图为FG结果,右图为FGSM算法结果;CDF为对应的累积分布函数,按原文可理解为转移性;FG算法的结果要好于FGSM;
作者还给出了基于优化算法的,基于随机扰动的实验结果,但是效果并不显著就不列了,可以上原文附录查看。
目标攻击
作者发现目标攻击对于用于训练的模型能够得到好的结果,但是对于其他模型的转移能力几乎没有,可以看下图,基于优化算法的结果。

作者发现即使增加扰动也不能提高转移性,包括基于梯度的算法。
基于集成的方法(Ensemble - based approaches)
假设对抗样本对多个模型都有攻击作用,那么对其他模型很可能也有效。作者提出了从多个模型中生成对抗样本,思想就是集成学习。给定
个白盒模型;Softmax outputs
;原始样本
;正确类标
;公式如下:
是集成模型; 是对应权值,且 。作者希望生成的对抗样本能攻击其他黑盒模型 。
为评估算法的有效性,作者对每五个模型中的四个作为生成对抗样本,视为白盒,另一个模型作为攻击对象,视为黑盒。
作者分别针对几个模型进行了独立的实验,论文中有详细的结果,这里就不附上来了。实验结果表明,无论是目标攻击还是非目标攻击效果都有很大的提升,但是作者也发现对角线上的accuracy不是0;作者假设这一现象存在的原因是不同模型之前的梯度相互正交,因此沿着这个方向可能需要很大的失真才能得到对抗样本。
使用FG和FGS的算法基于集成算法得到的对抗样本转移性并没有比单模型的结果好,作者认为是因为一维子空间中只存在很少的一些可能类标。(补充一点,基于快速梯度思想生成对抗样本的算法得到的对抗样本都在一维子空间内。即只在梯度方向的一维空间内)
不同模型的几何特性
为了更好的理解对抗样本转移性,作者从几何的角度来观察。作者参考1000个类标的大型数据集。
据作者实验观察,不同模型之间的梯度方向几乎是正交的,不同模型梯度方向间夹角的余弦值,非对角值都接近于0。
单模型算法非目标攻击的决策边界
作者选取VGG-16的梯度方向
,以及另一个与之相正交的随机方向
,然后每个点
对应图像
,画出二维图像如下图所示:

第一行的图像是第二行的放大之后的细节。通过图像可以看到,能够正确分类的结果只在中心的部分,沿着梯度方向(x轴),很快出了有限的边界,就分类错误了;不同的模型距离原始类标也不同,即使是ResNet模型之间;每个平面能表示的类标也有限,实验中最多久21个类。也就是所有类标的2.1%。作者认为这是基于梯度的方法很难转移的原因。
将图像的中心区域重合到一起,如下图所示:

可以看出来,形状都很类似,基本上重合,这也就解释了无目标攻击能转移的原因。
梯度方向边界直径小于随机方向的,一个潜在原因就是沿着梯度方向改变损失效果显著;即使沿着x轴向左移动图像,这相当于最大化真实的预测概率,它也比沿着随机方向移动更快到达边界。
对于VGG-16模型,在与真实相对应的区域内存在一个小洞。这也许可以部分解释为什么非靶向畸变小的对抗性图像存在,但不能很好地转移。这个洞在其他模型决策平面中不存在。在这种情况下,非目标对抗性图像在这个洞不转移。
基于目标集合的方法的决策边界。
作者选择除了ResNet-101和随机正交方向之外的所有模型集合的目标对抗性方向,并在由这两个方向向量张成的平面上绘制决策边界,如下图所示。
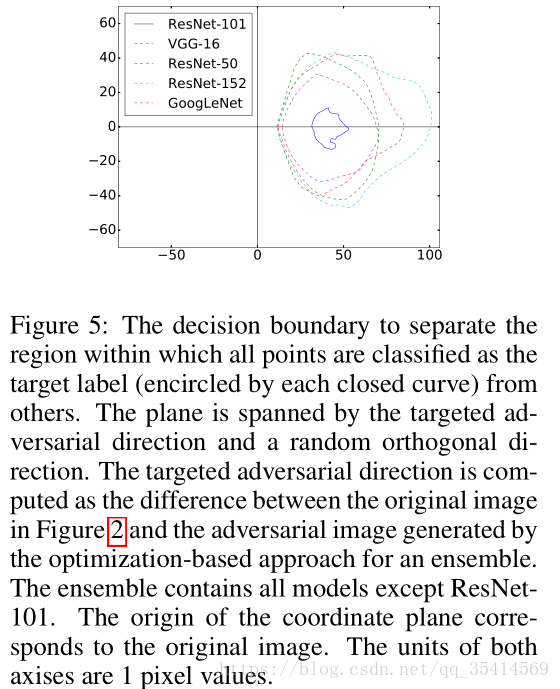
可以观察到,被预测为目标标签的图像区域,与集成中的四个模型很好地对齐。然而,对于不用于生成对抗性图像的模型(ResNet-101),它也有一个非空区域被成功误导到目标标签,虽然面积小得多。同时,各模型闭合曲线内的区域几乎具有相同的中心。
真实世界的案例:生成Clarifai.com的对抗样本
这个网址目前提供最先进的分类服务,其使用的模型、训练集和类标都是不可知的,所以这是一个黑盒攻击。
非目标攻击的转移效果用单模型和基于集成的方法都不错;目标攻击的转移效果,VGG-16的对抗样本57%可转移,集成算法生成的对抗样本76%可转移(只是误导分类,并没有分到指定类标);集成算法生成的对抗样本18%可转移为指定类标。