版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/Aaron_Gan/article/details/79338035
Scrapy爬取静态页面
安装Scrapy框架:
Scrapy是python下一个非常有用的一个爬虫框架
Pycharm下:
搜索Scrapy库添加进项目即可
终端下:
#python2
sudo pip install scrapy
#python3
sudo pip3 install scrapy
#安装完成测试一下
scrapy version
爬取赶集网租房信息
们通过Chrome查看源代码可以发现所有的内容都是静态的,这种是比较容易爬取的。
Chrome下可以安装插件XPath。
终端下
scrapy shellhttp://bj.ganji.com/fang1/ 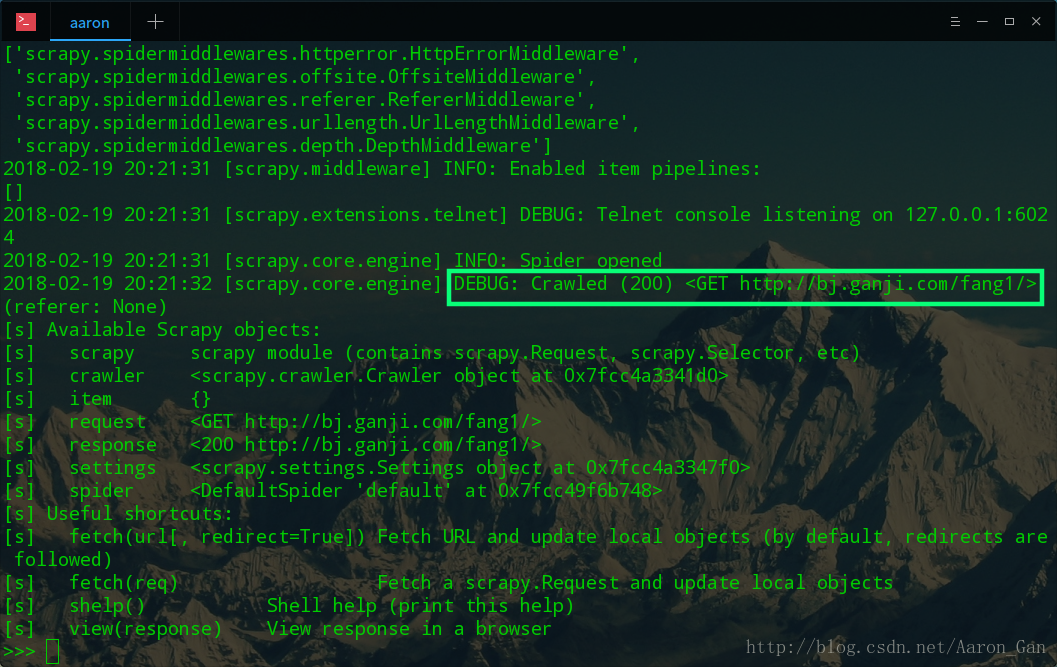
返回200即表示获取成功
#调用默认的浏览器打开缓存的页面
view(response)f12控制台下找到对应元素的xpath,可以在XPath插件下检查是不是对应的元素,复制这个对应的xpath
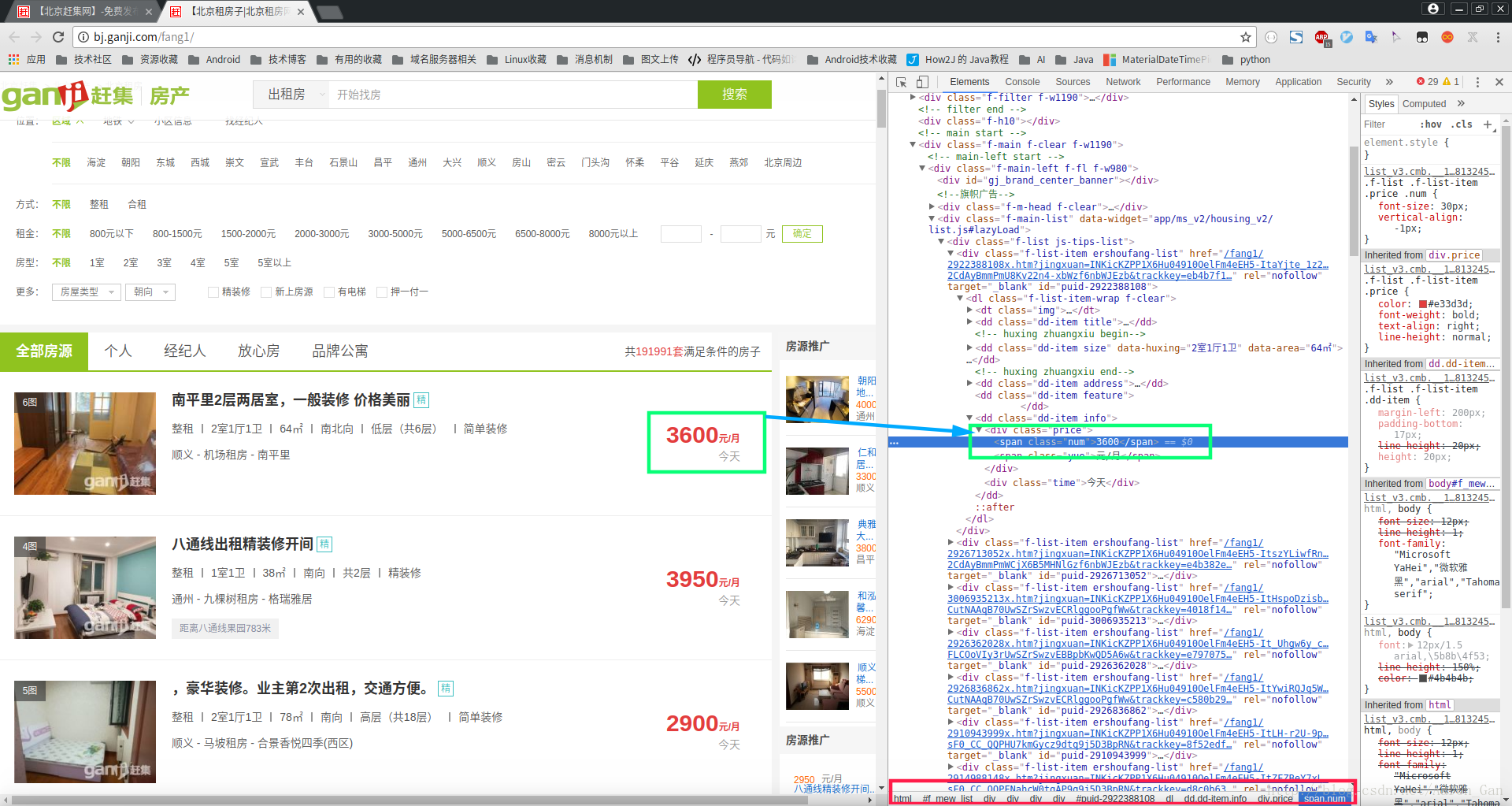
终端下
response.xpath('//*[@id="puid-2922388108"]/dl/dd[5]/div[1]/span[1]').extract()
response.xpath('//*[@id="puid-2922388108"]/dl/dd[5]/div[1]/span[1]/text()').extract()
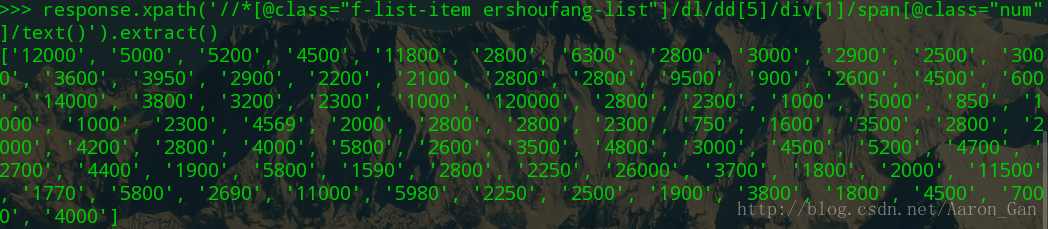
批量价格获取,这里做一个选择,原来是用id来标记价格,而这个id是一个item唯一的,所以我们要找到所有items的共性,这里借助类选择器来实现,因为所有的item的css类都是f-list-item ershoufang-list,这样获取到的就是一个价格列表,在span里面再用类选择器区分一下价格和单位。总之就是找共性,一步一步将元素从复杂的页面中剥离出来。
response.xpath('//*[@class="f-list-item ershoufang-list"]/dl/dd[5]/div[1]/span[@class="num"]/text()').extract()
爬取知乎日报首页
值得注意的直接脚本爬取知乎日报的首页会返回500错误,需要对项目进行一些设置,让爬虫模拟浏览来访问页面
终端下新建Scrapy项目
scrapy startproject spiderZhihuDaily
修改settings.py,添加
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'USER-AGENT': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36',
}找到页面中要获取的对应元素
这里是:图片,标题,链接
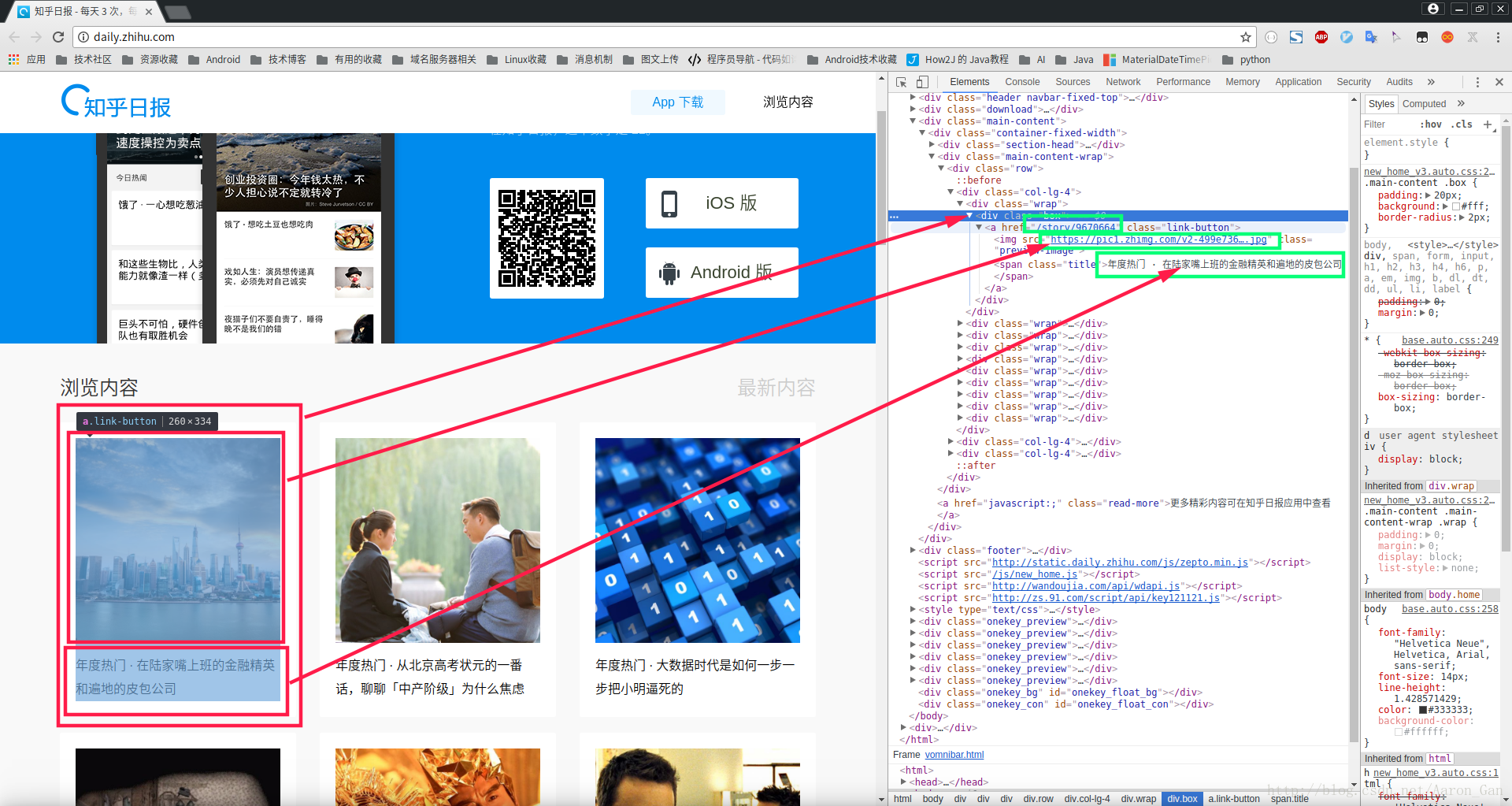
f12控制台下检查元素,找到xpath,将这个Xpath复制下来,在代码中会用到
注
#我们获取的xpath是单个元素的,这里以title为例
/html/body/div[3]/div/div[2]/div/div[1]/div[1]/div/a/span
#如果需要批量获取元素,需要借助类选择器来辅助,这里做一个选择
#注意观察网页代码中的规律,每一个item的类选择器都是class="box"
#所以通过这个来实现批量title的获取
/html/body/div[3]/div/div[2]/div/div[1]/div[@class="box"]/div/a/span/text()代码
import scrapy
class ZhihuDailySpider(scrapy.Spider):
name = 'zhihuDaily'
start_urls = ['http://daily.zhihu.com/']
def parse(self, response):
titles = response.xpath('/html/body/div[3]/div/div[2]/div/div[@class="col-lg-4"]/div[@class="wrap"]/div[@class="box"]/a/span/text()').extract()
imgSrcs= response.xpath('/html/body/div[3]/div/div[2]/div/div[@class="col-lg-4"]/div[@class="wrap"]/div[@class="box"]/a/img/@src').extract()
links = response.xpath('/html/body/div[3]/div/div[2]/div/div[@class="col-lg-4"]/div[@class="wrap"]/div[@class="box"]/a/@href').extract()
for title,img,link in zip(titles,imgSrcs,links):
print(title+"---"+img+"---"+link)运行
终端下进入爬虫脚本所在文件夹
#执行爬虫命令
scrapy crawl zhihuDaily