常用到的包:
所谓的包,就是三方模块,在代码最上方用import引入的。这种都是要先安装的。pip install xxx
1,requests 一个HTTP库,功能是解析地址,获取页面代码
安装: pip install requests 引入:import requests
2,美丽的汤,也就是BeautifulSoup,作用是解析html页面,获得包含标签的若干对象。
安装: pip install beautifulsoup4 引入:from bs4 import BeautifulSoup as bs (引入时,as bs可写可不写,意思是 把美丽的汤引入进来,在实际用到的时候,用bs来代替BeautifulSoup)
3,openpyxl 作用是把爬取到的数据 存放在一个excel表格里。
安装 pip install openpyxl 引入 from openpyxl import Workbook
4, 其他包。 还有很多包,不能一一列举。思路是,用到什么包就引入什么包。
实际操作:
页面可以分为三种:
- 静态页面,就是数据不会变动的页面
- 动态页面,就是数据会随时变动的页面,数据是js生成的
- 需要登录的静态/动态页面,有些页面还需要各种验证码
先来梳理一下爬取的流程:
1,先引入需要的包,可以边写边引入,用到哪个包就引入哪个包 from xxx import xxx
2, 按F12,选择network选项,找到type为document或js或XHR的页面,把header内容取出来。headers = {...}
3,把url也取出来,等待解析 url = xxx
4,用requests 解析地址,获取页面代码 res = requests.get(url, headers=headers) html = res.text
5,用美丽的汤解析html页面,获取我们需要的包含标签的soup对象 soup = bs(html, 'html.parser')
6,筛选我们需要爬取的内容标签,内容在哪个标签里,就把那个标签选出来 div = soup.select('selector') 这一步的selector可以用右击标签,选择copy里面的copy selector来获取。 这里获取到的div是若干div对象
7,遍历div,把div对象转换出div标签 for div in divs: ...
8,把获取的内容加入进excel表格,具体步骤是:
# 1, 引入Workbook模块
from openpyxl import Workbook
wb = Workbook() # 2,创建一个文件
ws = wb.active # 3,激活文件
ws.append(['内容1','内容2',...]) # 4,往文件里加内容
wb.save('文件名.xlsx') # 保存成excel表格
根据不同的页面,我们采取稍有不同的爬取策略:
1,静态页面
这个页面的特点就是,数据是死的,不会随机变动。
示例:我们以csdn首页为例,获取左边列表内的一些内容,即
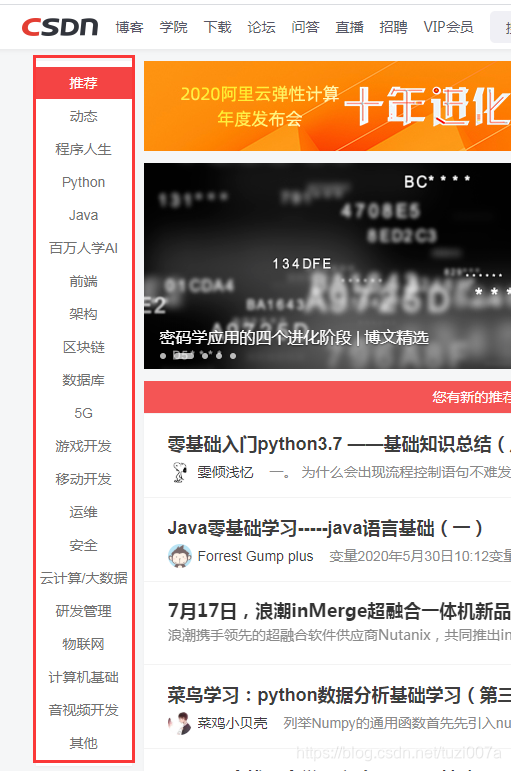
红框里的内容。这些内容是静态的,不会动,所以我们去到首页,F12,找到这个type为document的页面即可。然后编写代码:
# 以csdn首页为例,获取首页的部分内容
import requests
from bs4 import BeautifulSoup as bs
url = 'https://www.csdn.net/' # 拿到首页的url
res = requests.get(url) # 发出请求,解析url
html = res.text
# print(html)
soup = bs(html,'html.parser') # 解析html
a = soup.select('#nav > div > div > ul > li > a') # 把需要的标签获取出来
for a in a: # 对标签对象进行遍历,得到列表里的每个a标签
print(a.text) # 输出a标签里的内容
输出结果:
推荐
动态
程序人生
Python
Java
百万人学AI
前端
架构
区块链
数据库
5G
游戏开发
移动开发
运维
安全
云计算/大数据
研发管理
物联网
计算机基础
音视频开发
其他
这样就获取到了页面的静态内容。 可以看出来,静态页面是最简单的一种。
2,动态页面
动态的内容牵扯就比较广泛了,会动的数据,会动的内容,会翻页的页面,会动的cookie,等等。
但是,万变不离其宗。我们只需要知道,我们要什么数据,就去相应的js或者XHR里面找数据即可。
比如前面写过的有道翻译,就是获取了有道的翻译数据,然后呈现出来。这里把思路再回顾一遍:
import urllib.request
import urllib.parse # 可以实现url的构造,但是去掉也不影响结果
import json # 把获取到的字符串转换成字典的时候需要用到
content = input('输入要翻译的内容: ')
url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule'
# 取network里面找到这个url,把里面的_o去掉,这个是有道的加密,详情可以在csdn里搜一下
data = {}
# 在network里找到data,复制过来
data['i'] = content
data['from'] = 'AUTO'
data['to'] = 'AUTO'
data['smartresult'] = 'dict'
data['client'] = 'fanyideskweb'
data['salt'] = '15938760135952'
data['sign'] = 'af3f1c36a96655e1a13616ec4e523d9c'
data['ts'] = '1593876013595'
data['bv'] = 'ce1fe729a12a6b5169046dd3aac11e4c'
data['doctype'] = 'json'
data['version'] = '2.1'
data['keyfrom'] = 'fanyi.web'
data['action'] = 'FY_BY_CLICKBUTTION'
data = urllib.parse.urlencode(data).encode('utf-8')
# urlencode()将字符串以URL编码,用于编码处理,返回的是字符串。
# 得到的字符串再编译成utf-8的形式
response = urllib.request.urlopen(url, data)
html = response.read().decode('utf-8') # 得到的html是字符串
target = json.loads(html)['translateResult'][0][0]['tgt']
# 把得到的字符串转化成字典 再从字典里获取翻译结果
print('翻译结果: ', target)
可以看得出来,动态页面的获取,就相对复杂了。这里获取的是有道的data数据。因为输入的内容保存在这里,我们需要拿出来。 然后通过url解析,来获得我们需要的翻译结果。
3,需要登录的页面爬取
前面说了关于爬取静态页面和动态页面。那些都是不需要登录就可以直接去爬取的。
有些网站是不登录就看不到数据的,比如淘宝,人人网,还有各种管理后台。这些都是登陆后才能看到数据的。
这里提供一种思路供大家参考。就是自己有账号密码,爬取登录后的数据。
先用账号密码登录,进入到要爬取的页面。然后看下要爬取的页面是静态的,还是动态的,
如果是静态的,就按照静态页面爬取页面内容。
如果是动态的,就按照动态方法爬取动态内容。
友情提示:爬取须谨慎,且爬且珍惜!!!