简介
现在在整理原来写过的东西,这是一个比较简单的爬虫项目,就是进行动态页面的爬取,主要的难点是实现模拟点击。
查看目标网站
查看目标网站:
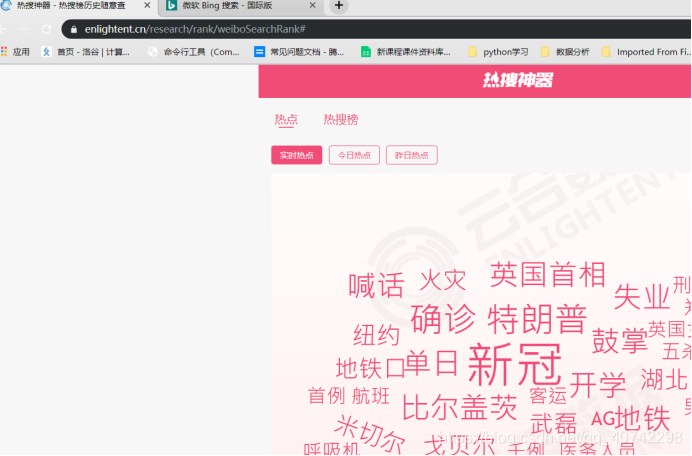

但是这不是我们的目标,我们要爬取的是点击热搜榜之后的热搜话题:
是这样的:
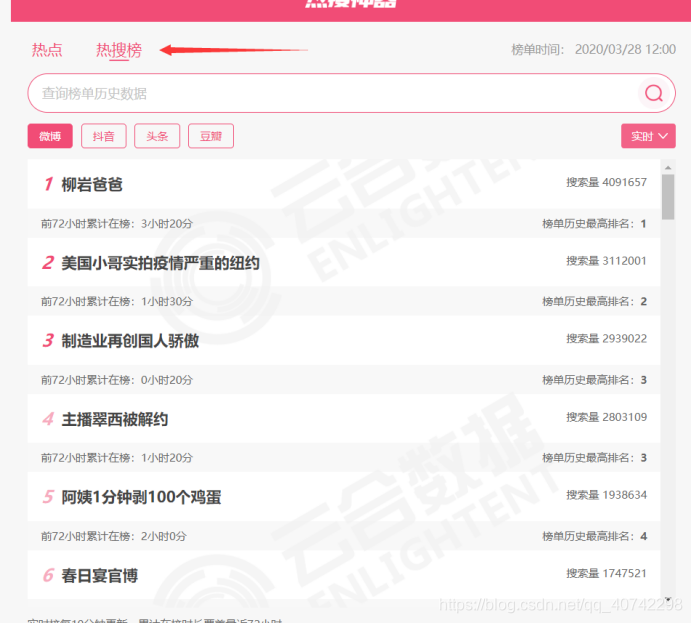
然后才能爬取,所以这是一个爬取动态页面的项目。
这里我用到了selenium库进行模拟操作,首先使用该库模拟点击然后进行数据的爬取。
要在scrapy中爬取动态页面需要添加中间件,也就是说再middleware中添加模拟操作。
代码部分
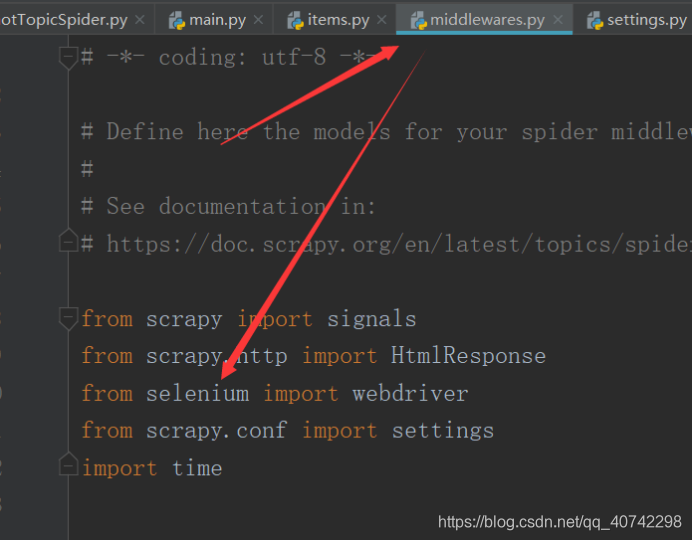
添加如下代码:
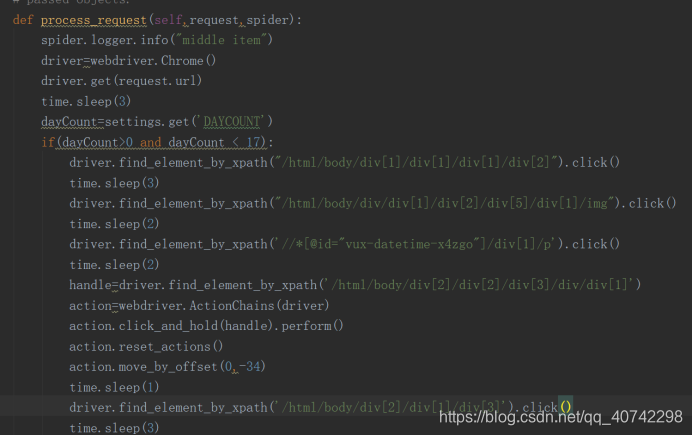
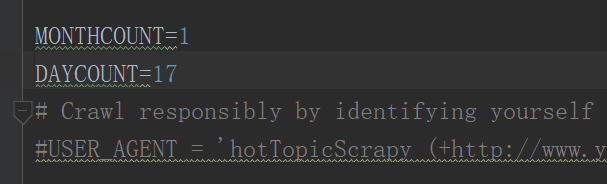
DAYCOUNT设置在setting.py中作为一个全局变量,用来控制爬取几天的热搜。
这里使用的是xpath用来定位:

然后右键:
然后我们能希望能找到历史的热搜数据,所有又模拟了多次鼠标点击:

大致的顺序就是先点击”热搜榜”,然后点击”实时”,再然后选择”热搜历史”。分别对应下面代码中的三次模拟点击事件:

每一次操作为了等待网页反应的时间所以都使用了sleep函数。
然后为了能得到更多的数据,还模拟了鼠标下拉的这一个动作:

最后得到网页源代码,然后返回html文件。

这就是中间件模块的全部工作。
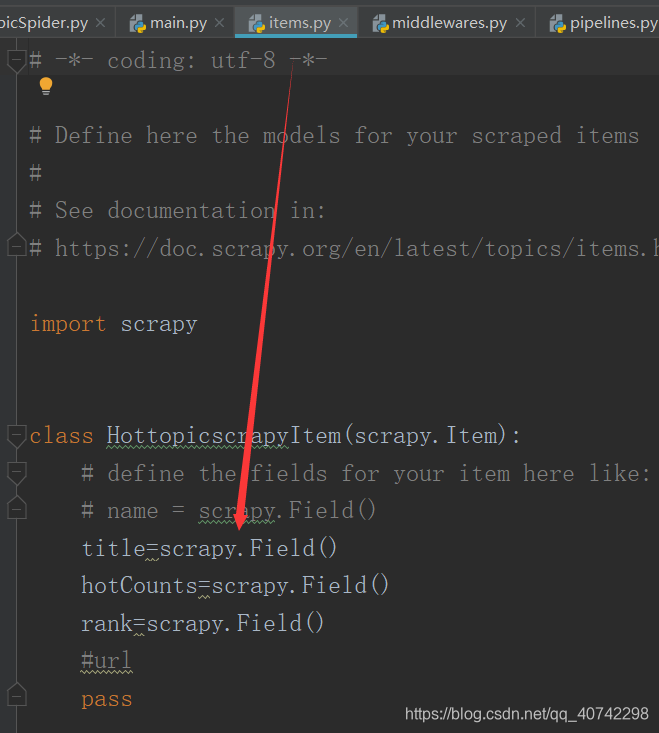
然后是parse解析函数,这里同样使用了xpath的方法,具体操作见上述对于xpath的copy操作,然后我们选择‘title’‘hotcounts’和‘rank’这三个维度的数据,具体的定义在item.py中已经写完。
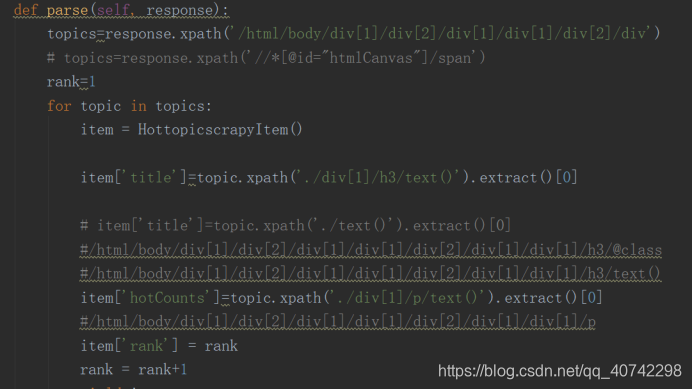
为了能做到循环爬取固定天数,所以还有循环机制:

存储
数据的存储由pipeline模块完成:
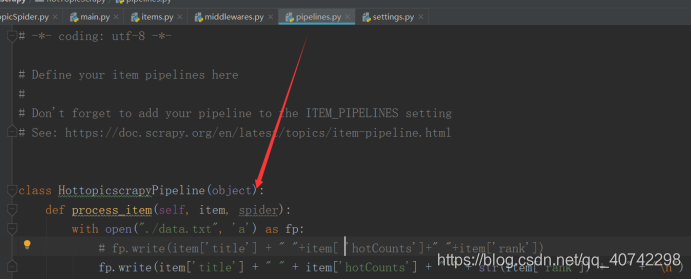
我直接写入到txt文件下。
运行后得到结果:
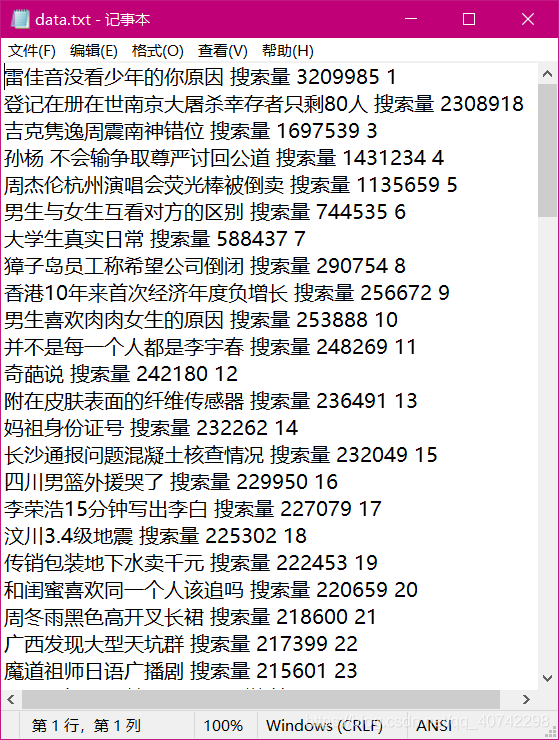
哈哈,从我爬的结果就知道这是比较久之前的了,做个小总结,也和大家共勉~~