版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/u012750702/article/details/54381503
主要参考书 《Machine Learning》Tom M.Mitchell
过度拟合现象描述:
死扣细节而忽略其他更重要的问题,过度在意细节而忽略大趋势。
或者说,当数据中有噪声或训练样例的数量太少以至于不能产生目标函数的有代表性的条件时,策略会遇到困难。
或者说,当数据中有噪声或训练样例的数量太少以至于不能产生目标函数的有代表性的条件时,策略会遇到困难。
决策树
现象:
算法在训练样例上表现很好,在测试样例上表现不好。
看张图,来自参考书中:
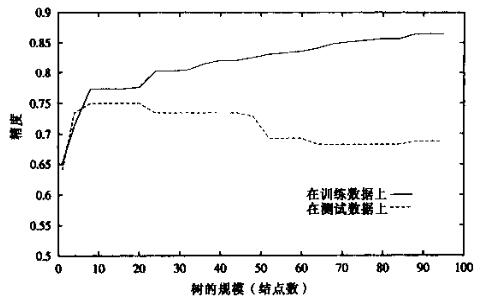
成因:
训练样例中含有随机错误或噪声(不过当没有随机错误或噪声时也有可能发生过度拟合现象,那就是误把个例当成特殊)。
训练样例中含有随机错误或噪声(不过当没有随机错误或噪声时也有可能发生过度拟合现象,那就是误把个例当成特殊)。
解决方法:
及早停止树的生长,后修剪法(错误概率降低修剪、规则后修剪)。
实际上,但凡有过度拟合出现的算法,都要有验证集合来验证,验证集合是从训练集中分出来的,注意与测试集区分开。这样做的原因很显然,因为验证集与训练集表现相同的随机错误或噪声的可能性很低。
人工神经网络(ANN)
现象、成因:与决策树完全相同。
解决方法:引入SVM。
现象、成因:与决策树完全相同。
解决方法:引入SVM。