
数量技术宅团队在CSDN学院推出了量化投资系列课程
欢迎有兴趣系统学习量化投资的同学,点击下方链接报名:
为何产生过度拟合
我们在做数据分析建模,或是量化策略回测的过程中,会模型在训练时过度拟合了历史数据(回测),导致在新数据上的预测(实盘)效果不佳。造成这种现象有以下几种原因:
一是这可能是因为模型过于复杂,参数过多,使其可以轻松地拟合历史数据,但在新数据上的预测能力较差。一起来看一个典型的过度拟合的例子。
import numpy as np
import matplotlib.pyplot as plt
# Generate some data
x = np.linspace(0, 10, 100)
y = np.sin(x) + np.random.normal(scale=0.1, size=100)
# Fit a polynomial of degree 20
p = np.polyfit(x, y, 20)
y_pred = np.polyval(p, x)
# Plot the data and the fitted polynomial
plt.scatter(x, y)
plt.plot(x, y_pred, color='red')
plt.show()我们生成了一组sin函数加上随机数的序列,同时用20阶的高阶函数去拟合这组样本数据,如此高维的数据,必然会产生样本内拟合极度优秀的效果。而模型在学习训练数据时过度拟合了数据的细节,导致模型过于复杂,也就失去了泛化能力。

另一个可能的原因是样本选择偏差。如果使用的历史数据不足以代表未来的变化,那么模型在训练时就会过度拟合,从而在实际应用中无法正确地预测。例如采用15年8月以前数据测试的股指期货短周期\高频策略,由于股指期货手续费改变造成的市场结构剧变,除非手续费重新恢复,否则数据偏差极易产生未来绩效的偏差。
如何解决过度拟合问题
为了解决数据分析、量化策略构建过程中最常见的过拟合问题,我们需要采取一些措施。
交叉验证
数据集划分是避免过度拟合问题的关键步骤之一。在构建量化策略时,我们通常将数据集划分为训练集和测试集。训练集用于训练模型,测试集用于验证模型的泛化能力。为了避免过度拟合问题,我们可以使用交叉验证的方法,将数据集分成10份,每次选取其中一份作为测试集,其他九份作为训练集。这样可以更好地验证模型的泛化能力,避免过度拟合。
下面是一个使用sklearn库做10折交叉验证的例子,调用cross_val_score方法,生成Cross-validation scores、Mean score、Standard deviation等交叉验证结果并展示。
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LinearRegression
# Generate some data
x = np.linspace(0, 10, 100)
y = np.sin(x) + np.random.normal(scale=0.1, size=100)
# Fit a polynomial of degree 20
p = np.polyfit(x, y, 20)
y_pred = np.polyval(p, x)
# Use linear regression with cross-validation to evaluate the model
lr = LinearRegression()
scores = cross_val_score(lr, x.reshape(-1, 1), y, cv=10)
# Print the mean score and standard deviation
print("Cross-validation scores:", scores)
print("Mean score:", np.mean(scores))
print("Standard deviation:", np.std(scores))
'''
output
Cross-validation scores: [-7.06062585e+00 -4.33284120e-04 -2.57612012e+01 -2.13349644e+00
-6.45893114e-01]
Mean score: -7.120329969404656
Standard deviation: 9.643292108330295
'''扩充训练数据集
下面示例,展示了不同的训练数据集大小对于模型预测能力的影响。图表中的横轴表示训练集的大小,纵轴表示模型在测试集上的预测误差。可以看到,当训练集较小时,模型在测试集上的预测误差较大,而当训练集较大时,模型的预测误差较小。这表明,训练数据集大小对于模型的预测能力具有重要影响。

因此,在数据运行范围内,我们应该尽可能选择更大的训练(回测)数据集,例如我们如果构建中低频策略,可以使用5年、甚至10年以上的数据集进行训练,而构建高频策略,也需要尽可能大的训练集,具体以可获取的Tick、OrderBook数据范围为准。
特征选择与正则化
特征选择是避免过度拟合问题的另一个关键。在数据、策略的建模过程中,我们通常会有许多备选特征可以用于建模预测,如果选择所有的备选特征进行建模,会导致模型过于复杂,容易过度拟合。因此,我们通过正则化筛选最重要的特征,减少特征数量,降低过度拟合的风险。
下面是一个正则化避免过度拟合的例子(省略加载数据步骤),我们创建逻辑回归模型,并使用L1正则化来选择重要特征。然后使用所选择的特征来拟合逻辑回归模型,在测试集上评估该模型。这种方法通过只选择最重要的特征来避免过拟合,从而降低了模型的复杂性并提高了其泛化性能。
# Import necessary libraries
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.feature_selection import SelectFromModel
# Load data ......
# Split data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(data.drop('target', axis=1), data['target'], test_size=0.2, random_state=42)
# Create logistic regression model
lr = LogisticRegression()
# Use L1 regularization to select important features
selector = SelectFromModel(estimator=lr, threshold='1.25*median')
selector.fit(X_train, y_train)
# Transform training and testing sets to include only important features
X_train_selected = selector.transform(X_train)
X_test_selected = selector.transform(X_test)
# Fit logistic regression model on selected features
lr_selected = LogisticRegression()
lr_selected.fit(X_train_selected, y_train)
# Evaluate model performance on testing set
print('Accuracy on testing set:', lr_selected.score(X_test_selected, y_test))控制模型复杂度
控制模型复杂度的概念相对来说更加主观,其一,在建模(回测)中,我们通常会使用一些复杂的模型,如决策树、神经网络等。这些模型具有很强的拟合能力,但我们的模型选择并不是越复杂越好,最重要的是贴合数据背后的经济、行为逻辑。
除了模型选择,还需要控制参数的数量、以及特征的数量,控制模型复杂度是一个整体的工作,贯穿于整个数据建模与策略回测的过程。
此外,我们还可以采用数据增强、集成学习等方法来避免过度拟合问题。这些措施可以提高模型的稳定性和可靠性,为模型的实际应用提供保障。
对量化投资:实盘不如回测是过度拟合吗
最后一段,我们针对量化投资,再做一些展示。时常有粉丝朋友问到技术宅:我做了一个模型开始跑实盘,但是策略在实盘过程中运行的绩效远远不如回测,是因为我过度拟合了吗?
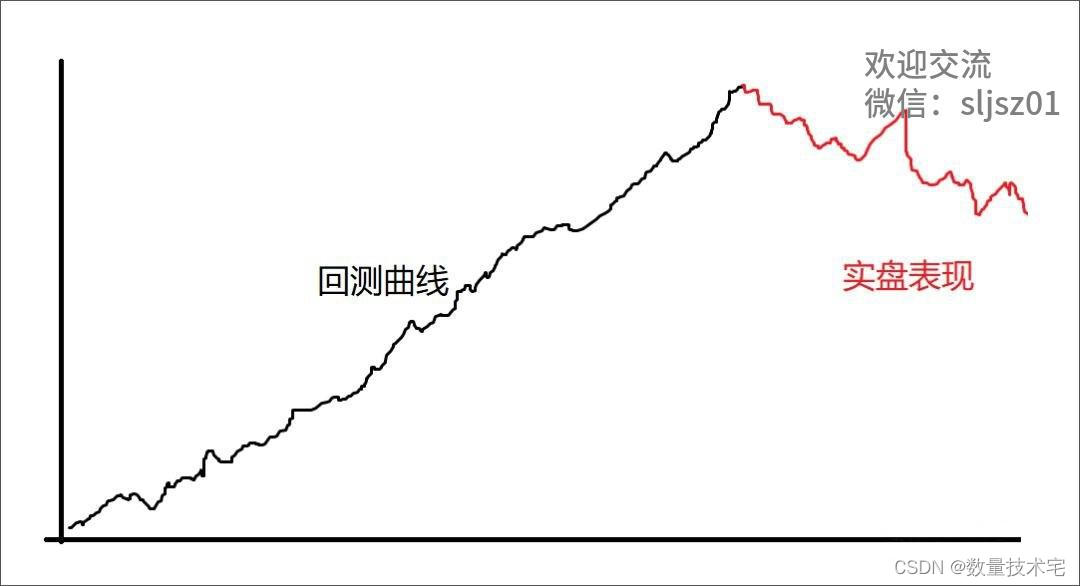
其实,策略在回测时的表现与实盘表现不一致,是量化投资领域一种普遍存在的现象。这种不一致不完全是因为过度拟合产生的,可能是多种因素引起的:
-
数据偏差:回测时使用的历史数据可能与实际市场环境存在一定的差异,例如我们在上文中提到的股指期货的例子,变化的市场结构会对策略的表现产生影响。
-
滑点和交易成本:回测时通常假设买卖价格可以立即获得,但实际交易中存在滑点和交易成本,这些因素都可能会对策略的表现产生影响。
-
策略实现:在实盘交易中,策略的实现可能会受到多种因素的影响,例如交易执行的速度、交易规模的限制等,这些因素也可能会对策略的表现产生影响。
-
过度拟合:也是本文讨论的重点,在回测中,策略的过度拟合,使得策略在回测中表现良好,但在实际交易中表现不佳。
为了减少回测和实盘表现的差异,可以采取以下措施:
-
尽可能使用更真实、更贴近目前市场状况的历史数据。
-
在回测时保守的考虑交易成本和滑点等因素。
-
在回测中尽可能遵循策略实盘交易的执行规则。
-
采用交叉验证、扩充训练数据集、正则化特征选择、控制模型复杂度等有效方法,避免过度拟合。
如果你也觉得这次的分享给你的学习、工作、生活效率带来了经济实惠,建议点赞、收藏,同时也分享你的小伙伴,让我们一起独乐乐不如众乐乐。高效工作,快乐生活!