本文将继续介绍神经网络优化过程中可能遇到的一些问题,以及解决这些问题的常用方法。在训练复杂神经网络模型时,过拟合是一个非常常见的问题。本文介绍解决这个问题的主要方法。
所谓过拟合,指的是当一个模型过为复杂之后,它可以很好地“记忆”每一个训练数据中随机噪音的部分而忘记了要去“学习”训练数据中通用的趋势。
为了避免过拟合问题,一个非常常用的方法是正则化(regularization)。正则化的思想就是在损失函数中加入刻画模型复杂程度的指标。假设用于刻画模型在训练数据上表现的损失函数为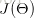
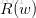
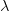
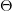
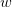
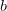
常用的刻画模型复杂度的函数有两种,一种是L1正则化,计算公式是:

另一种是L2正则化,计算公式是:

无论是哪一种正则化方式,基本的思想都是希望通过限制权重的大小,使得模型不能任意拟合训练数据中的随机噪音。但这两种正则化的方法也有很大的区别。首先,L1正则化会让参数变得更稀疏,而L2正则化不会。所谓参数变得更稀疏是指会有更多的参数变为0,这样可以达到类似特征选取的功能。之所以L2正则化不会让参数变得稀疏的原因是当参数很小时,比如0.001,这个参数的平方基本上就可以忽略了,于是模型不会进一步将这个参数调整为0。其次,正则化的计算公式不可导,而L2正则化公式可导。因为在优化时需要计算损失函数的偏导数,所以对含有L2正则化损失函数的优化要更加简洁。优化带正则化的损失函数要更加复杂,而且优化方法也有很多种。在实践中,也可以将L1正则化和L2正则化同时使用:

TensorFlow可以优化任意形式的损失函数,所以TensorFlow自然也可以优化带正则化的损失函数。以下代码给出了一个简单的带L2正则化的损失函数定义:
w= tf.Variable(tf.random_normal([2, 1], stddev=l, seed=l)) y = tf.matmul(x, w) loss = tf.reduce_mean(tf.square(y_ - y) ) + tf.contrib.layers.l2_regularizer(lambda_)(w) # loss为定义的损失函数,它由两个部分组成,第一个部分是均方误差损失函数,它刻画了模型在训练数据上的表现 # 第二个部分就是正则化,它防止模型过度模拟训练数据中的随机噪音
通常我们会使用TensorFlow中提供的集合(collection)。它可以在一个计算图(tf.Graph)中保存一组实体(比如张量)。以下代码给出了通过集合计算一个5层神经网络带L2正则化的损失函数的计算方法:
import tensorflow as tf
def get_weight(shape, lambda_):
"""
获取一层神经网络边上的权重,并将这个权重的L2正则化损失加入名称为“losses”的集合中
其中,lambda_参数表示了正则化项的权重。TensorFlow提供了tf.contrib.layers.l2_regularizer函数,
它可以返回一个函数,这个函数可以计算一个给定参数的l2正则化项的值。
类似的,tf.contrib.layers.l1_regularizer可以计算L1正则化项的值
"""
var = tf.Variable(tf.random_normal(shape), dtype = tf.float32) # 生成一个变量
#add_to_collection函数将这个新生成变量的L2正则化损失项加入集合。
#这个函数的第一个参数‘losses’是集合的名字,第二个参数是要加入这个集合的内容。
regularizer = tf.contrib.layers.l2_regularizer( lambda_ )
tf.add_to_collection("losses", regularizer(var))
# 返回生成的变量。
return var
x = tf.placeholder(tf.float32, shape=(None, 2))
y_ = tf.placeholder(tf.float32, shape=(None, 1))
batch_size = 8 #每一个样本数据batch的大小
layer_dimension = [2, 10, 10, 10, 1] #定义每一层网络中节点的个数
n_layers = len(layer_dimension) #神经兩络的层数
#这个变量维护前向传播时最深层的节点,幵始的时候就是输入层。
cur_layer = x #当前层的节点个数
in_dimension = layer_dimension[0]
for i in range (1, n_layers): #通过一个循环来生成5层全连接的神经网络结构。
out_dimension = layer_dimension[i] #layer_dimension [i]为下一层的节点个数。
# 根据上一层和当前层的节点数,生成当前层中权重的变量,并将这个变量的L2正则化损失加入计算图上的集合。
weight = get_weight([in_dimension, out_dimension], 0.001)
bias = tf.Variable(tf.constant(0.1, shape=[out_dimension]))
cur_layer = tf.nn.relu(tf.matmul(cur_layer,weight) + bias) #使用ReLU激活函数。
in_dimension = layer_dimension[i]
# 在定义神经网络前向传播的同时已经将所有的L2正则化损失加入了图上的集合,
# 这里只需要计算刻画模型在训练数据上表现的损失函数。
mse_loss = tf.reduce_mean(tf.square(y_ - cur_layer))
tf.add_to_collection('losses',mse_loss) #将均方误差损失函数加入损失集合。
# get_collection返回一个列表,这个列表是所有这个集合中的元素。在这个样例中,
# 这些元素就是损失函数的不伺部分,将它们加起来就可以得到最终的损失函数。
loss = tf.add_n(tf.get_collection('losses'))