版权声明:Hello https://blog.csdn.net/Edward_is_1ncredible/article/details/82427636
import numpy as np
import matplotlib.pyplot as plt
# 引入sklearn包中的datasets接口模拟一些点
from sklearn.datasets import make_circles,make_moons,make_blobs
n_samples = 1000
circles = make_circles(n_samples=n_samples,factor=0.5,noise=0.05)
moons = make_moons(n_samples=n_samples,noise=0.05)
blobs = make_blobs(n_samples=n_samples,random_state=8,center_box=(-1,1),cluster_std=0.1)
random_data = np.random.rand(n_samples,2),None # 二维是为了方便可视化
colors = "bgrcmyk"
data = [circles,moons,blobs,random_data]
models = [("None",None)]
f = plt.figure()
# Clustering-i.基于切割的K-means
# 1.原则:所有的类都有一个中心,属于一个类的点到它的中心的距离比到其他类中心点的距离更近
# 2.算法:A.从n个样本中随机选取K个作为初始化的质心,K的个数为分类的数
# B.对每个样本测量其到各个质心的距离,并把它归到最近的质心的类中
# C.重新计算已经得到的各类的质心
# D.迭代B和C过程,直到新的质心不变或小于指定的阈值
# 3.几个注意点
# 1)初始质心的位置可能会影响最终聚类的结果(多试几次找出稳定点)
# 2)离群点会影响整体的聚类效果(将质心换成取重点的K-Medoids算法)
# 3)必须要指定K(借助其他衡量因子)
from sklearn.cluster import KMeans
# n_cluster:分类数
models.append(("Kmeans",KMeans(n_clusters=3)))
# Clustering-ii.基于密度的DBSCAN(找到密度相连的最大集合)
# 1.原则:一定区域内,密度到达一定程度才叫一个类,否则叫离群点
# 2.概念:
# 1)E邻域:给定对象半径为E内的区域为该对象的E邻域
# 2)核心对象:如果给定对象E邻域内的样本点个数大于等于MinPts。则称该对象为核心对象
# 3)直接密度可达:对于样本集合D,如果样本点q在p的E邻域内,且p为核心对象,那么对象q从对象p直接密度可达
# 4)密度可达:对于样本集合D,给定一串样本点p1,p2…pn,p=p1,q=pn,假设对象pi从pi-1直接密度可达,则对象q从对象p密度可达
# 5)密度相连:存在样本集合D中的一点o,如果对象o到对象p和对象q都是密度可达,那么p和q密度相连
# 3.几个注意点:
# 1)优:对离群点不敏感
# 2)劣:需要KD-Tree等数据结构辅助,且参数问题的解决
from sklearn.cluster import DBSCAN
# min_samples:最小分类数,eps:E邻域
models.append(("DBSCAN",DBSCAN(min_samples=3,eps=0.2)))
# Clustering-iii.基于层次的聚类算法
# 1.原则:依次聚类距离最近的集合
# 2.距离衡量的方法:最短距离,最长距离,平均距离,Ward
# 3.几个注意点:
# 1)优:聚类灵活
# 2)劣:计算复杂度比较高,离群点影响比较大
from sklearn.cluster import AgglomerativeClustering
# n_cluster:分类数,linkage:距离计算方式
models.append(("AgglomerativeClustering",AgglomerativeClustering(n_clusters=3,linkage="ward")))
# Clustering-iv.基于图的Split算法
# 1.原则:与基本层次聚类思路相反,为从顶至下
# 3.几个注意点:
# 1)优:图建立方式及分裂方式灵活
# enumerate()函数用于将一个可遍历的数据对象(如列表,元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在for循环当中
# 遍历下标inx,实体部分clt
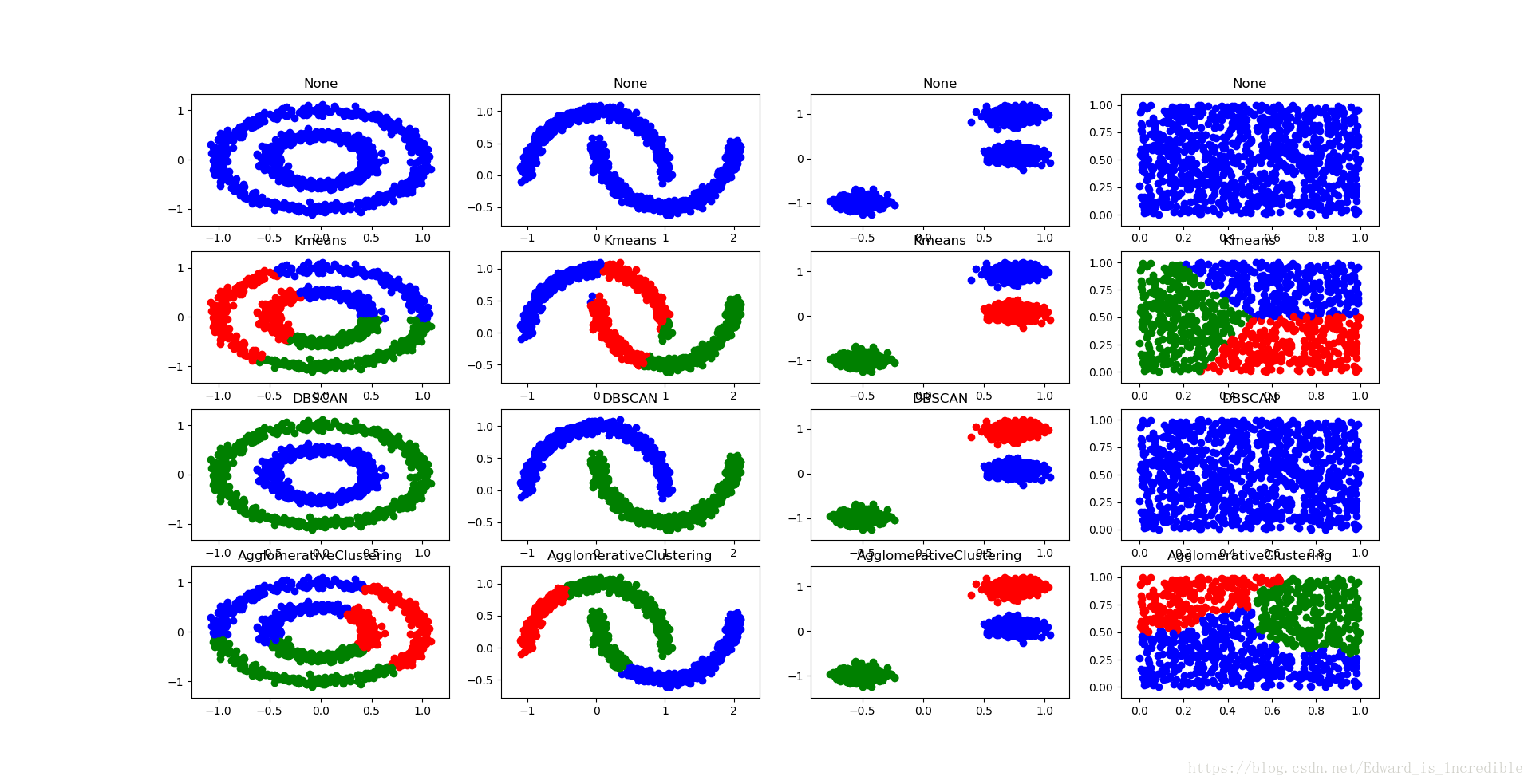
for inx,clt in enumerate(models):
# clt分为2部分,可以用这个形式指定clt名字和clt实体
clt_name, clt_entity = clt
for i, dataset in enumerate(data):
X, Y = dataset
if not clt_entity:
clt_res = [0 for item in range(len(X))]
else:
clt_entity.fit(X)
clt_res = clt_entity.labels_.astype(np.int)
f.add_subplot(len(models),len(data),inx*len(data)+i+1)
plt.title(clt_name)
[plt.scatter(X[p,0],X[p,1],color=colors[clt_res[p]]) for p in range(len(X))]
plt.show()
# Association-i.关联规则(反映一个事物与其他事物之间的相互依存性和关联性,目的:找到频繁项集)
# 1.概念:
# 1)项目:一个字段,对交易来说一般指一次交易中的一个物品,如尿布
# 2)事物:一个集合,对交易来说一般指发生的所有项目集合,如{啤酒,尿布}
# 3)项集:一个集合,包含若干项目的集合(一次事务中的)
# 4)频繁项集:某个项集的支持度大于设定阈值,则称这个项集为频繁项集
# 5)支持度:项集{X,Y}在总项集中出现的概率(Support)
# 6)置信度:在先决条件X发生的条件下,由关联规则{X->Y}推出Y的概率(Confidence),条件概率的概念
# 7)提升度:表示含有X的条件下同时含有Y的概率,与无论含不含X含有Y的概率之比,(Confidence({X->Y})/Support({Y}))
# * 频繁项集的组合可能是频繁的也可能是非频繁的,非频繁项集的组合一定是非频繁的
# 2.算法:Apriori:用低阶频繁项集和设定的阈值找到高阶频繁项集
# A.指定支持度的阈值
# B.判断项集的支持度与阈值的大小关系
#
# Association-i.序列规则(在关联规则的前提下将时间因素考虑进来,剔除关联规则中时间点靠后的项对时间点靠前的项的支持)
# 1.应用:预测用户在本次购物之后,下次购物会购买其他什么用作搭配
# 2.算法:Apriori-All
# A.Forward:Apriori
# B.Backward:去掉时间序列之后的项对之前的项的支持
from itertools import combinations
def comb(lst):
ret=[]
for i in range(1,len(lst)+1):
ret+=list(combinations(lst,i))
return ret
class AprLayer(object):
d=dict()
def __init__(self):
self.d=dict()
class AprNode(object):
def __init__(self,node):
self.s=set(node)
self.size=len(self.s)
self.lnk_nodes=dict()
self.num=0
def __hash__(self):
return hash("__".join(sorted([str(itm) for itm in list(self.s)])))
def __eq__(self, other):
if "__".join(sorted([str(itm) for itm in list(self.s)]))=="__".join(sorted([str(itm) for itm in list(other.s)])):
return True
return False
def isSubnode(self,node):
return self.s.issubset(node.s)
def incNum(self,num=1):
self.num+=num
def addLnk(self,node):
self.lnk_nodes[node]=node.s
class AprBlk():
def __init__(self,data):
cnt=0
self.apr_layers = dict()
self.data_num=len(data)
for datum in data:
cnt+=1
datum=comb(datum)
nodes=[AprNode(da) for da in datum]
for node in nodes:
if not node.size in self.apr_layers:
self.apr_layers[node.size]=AprLayer()
if not node in self.apr_layers[node.size].d:
self.apr_layers[node.size].d[node]=node
self.apr_layers[node.size].d[node].incNum()
for node in nodes:
if node.size==1:
continue
for sn in node.s:
sub_n=AprNode(node.s-set([sn]))
self.apr_layers[node.size-1].d[sub_n].addLnk(node)
def getFreqItems(self,thd=1,hd=1):
freq_items=[]
for layer in self.apr_layers:
for node in self.apr_layers[layer].d:
if self.apr_layers[layer].d[node].num<thd:
continue
freq_items.append((self.apr_layers[layer].d[node].s,self.apr_layers[layer].d[node].num))
freq_items.sort(key=lambda x:x[1],reverse = True)
return freq_items[:hd]
def getConf(self,low=True, h_thd=10, l_thd=1, hd=1):
confidence = []
for layer in self.apr_layers:
for node in self.apr_layers[layer].d:
if self.apr_layers[layer].d[node].num < h_thd:
continue
for lnk_node in node.lnk_nodes:
if lnk_node.num < l_thd:
continue
conf = float(lnk_node.num) / float(node.num)
confidence.append([node.s, node.num, lnk_node.s, lnk_node.num, conf])
confidence.sort(key=lambda x: x[4])
if low:
return confidence[:hd]
else:
return confidence[-hd::-1]
class AssctAnaClass():
def fit(self,data):
self.apr_blk=AprBlk(data)
return self
def get_freq(self,thd=1,hd=1):
return self.apr_blk.getFreqItems(thd=thd,hd=hd)
def get_conf_high(self,thd,h_thd=10):
return self.apr_blk.getConf(low=False, h_thd=h_thd, l_thd=thd)
def get_conf_low(self,thd,hd,l_thd=1):
return self.apr_blk.getConf(h_thd=thd,l_thd=l_thd,hd=hd)
def main():
data=[
["牛奶","啤酒","尿布"],
["牛奶","啤酒","咖啡","尿布"],
["香肠","牛奶","饼干"],
["尿布","果汁","啤酒"],
["钉子","啤酒"],
["尿布","毛巾","香肠"],
["啤酒","毛巾","尿布","饼干"]
]
print("Freq",AssctAnaClass().fit(data).get_freq(thd=3,hd=10))
print("Conf",AssctAnaClass().fit(data).get_conf_high(thd=3,h_thd=3))
if __name__=="__main__":
main()