最近实习任务除了用公司内部机器学习平台(tensorflow引擎)跑模型就是调研一下浅层机器学习算法的并行与分布式,稍微做个总结
浅层机器学习中能够应用并行或者分布式的方面
1.1 ModelAssessment with Cross validation
相信对机器学习比较熟的都经常用交叉验证,简单解释一下就是把样本划分为n块相同大小的,选一些出来做训练集,剩下的做验证集,比较常见的是就留1块数据集做验证集。如果留1块数据集做验证的话,也就是说我们需要训练n个模型,用图说明一下
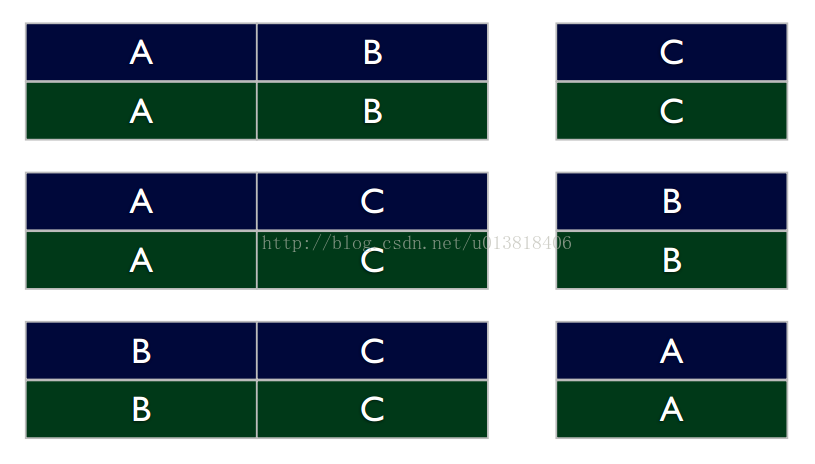
这里将数据分成ABC三块,分别使用AB,AC,BC作为训练集,用C,B,A作为验证集,在这个实验中我们需要生成3个模型,然而这3个模型的生成时是可以并行的或者分布式的,将AB在node1上生成模型,AC和BC在node2和node3上生成模型,各自拉下来每个结点需要训练的数据就可以开始并行或者分布式跑模型
1.2 ModelSelection with Grid Search
对于确定的机器学习算法选择参数也是一个比较大的工程,拿SVM打比方,一般SVM需要设置核函数、gamma和惩罚系数C,假如每个参数有三种选择,那么我们需要跑3*3*3=27个模型才能确定参数设置。现在假设有两个参数param_1有3个设置1,10,100,param_2有三个设置1e3,1e4,1e5,再结合交叉验证现在如图所示

1.3 BaggingModels: Random Forests
Bagging models是集成算法,按比例抽取样本集得到新的样本集合,然后根据多个新样本集合训练出不同的模型,以随机森林为例子,随机森林的bag稍微有点不同,它不仅仅随机抽取样本,还随机抽取属性,抽取完后,每个样本集合生成一个树模型,对于回归问题就求树的均值,对于分类问题就按vote数目,这种并行也非常好理解,我直接上一段sklearn的代码
trees = Parallel(n_jobs=self.n_jobs, verbose=self.verbose,
backend="threading")(
delayed(_parallel_build_trees)(
t, self, X, y, sample_weight, i, len(trees),
verbose=self.verbose, class_weight=self.class_weight)
for i, t in enumerate(trees))
这里需要了解一下joblib里面Parallel(我在joblib里面还看到了一个parallel函数说明差不多)和delayed用法,delayed获取后面函数的参数并分发给前面的n_jobs,Parallel建立多进程或者多线程通过backend选择,mulprocessing(多进程)threading(多线程),其实python还有一个Parallel的包不止支持多核还支持局域网内多台机器
1.4 In-LoopAveraged Models
前面讲到的所有的方法都是将模型作为一个最小单位来进行并行或者分布式的,也就是说并没有模型内的参数共享的考虑,比较直观的就是tensorflow的多cpu或gpu同步随机梯度下降,使用tensorflow建立模型后计算每个可训练变量的更新参数,然后对不同设备计算出来的结果进行取均值更新。举两个算法例子,用LR和决策树打比方 LR并行化
假设用随机梯度下降来更新参数,计算梯度公式如下
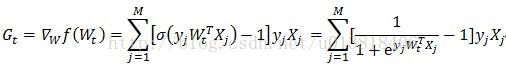
可以看出这个计算可以并行化的地方主要是矩阵的乘法与加法,其实也就是用分布式的矩阵乘法来优化,想要详细过程的可以查看这个博客
决策树的并行化
对数据集进行横切与纵切得到这样的<key,value>对,key为属性名,value为<属性值,属性名,样本id>,接着做map操作,将同一属性的value划分到一个reduce上,reduce根据属性值计算信息增益,最后根据最大的信息增益返回划分的数据集,将分割的数据集再次切分,直到到达终止条件比如信息增益阈值、最大深度或者最小叶子数
ps.本来想看下sklearn svm的并行的,发现是直接调用的libsvm就没看了,还有就是sklearn LR用的是二分的,如果出现多个标签,也就是ONE VS REST,sklearn会先调整损失函数,然后使用parallel来训练n(n-1)/2个分类器
(实验室和实习两头跑好累,好久没写blog了~。~,还是希望能坚持下去吧 )