1、SSE Intrisic based on x86
x86架构下的优化有多种手段,常见的有纯汇编优化、inline汇编、Intrinsic优化。前两种对编译器的依赖比较大,跨平台(windows\linux等)编译问题比较多,例如纯汇编:win32、win64、linux64下函数形参入栈规则都不一样,且需要保护的寄存器也有较大区别,此外还有汇编重定位问题等等;而inline汇编在windows下是intel格式,在linux下是AT&T格式。intrinsic入门快,且没有以上诸多问题,比较适合初学者,但是其性能相对纯汇编或Inline汇编,会差一些。本文就intrinsic优化作一些简单的介绍,具体需结合实践理解学习。
1.1 指令集对应的位数
| 指令集类型 | 所占位数 |
|---|---|
| – MMX | : Multi Media Extensions 8 x 64bit (1997) |
| – SSE/SSE2/SSE3/SSSE3/SSE4.x | : Streaming SIMD Extensions 8 x 128bit (1999) |
| – AVX/AVX2/FMA | : Advanced Vector Extensions 16 x 256 bit (2008) |
| – AVX-512/KNC | : Advanced Vector Extensions 32 x 512 bit (2012) |
备注:第二列8*64代表MMX寄存器有8个,每个是64位;8x128道理类似。
1.2 指令集intrinsic版对应的头文件
(1)、不同版本的指令集对应的intrinsic头文件如表1.1所示;表1.1中也列出了不同版本的VS对Intrinsic的支持能力不一。此外,需要注意的是1>、在VS中如果想win32及win64都能编译通过,应避免使用__m64类型的数据,数据类型在本文中会有讲述;2>、如果想在linux中编译成功,需在编译选项中加 -msse、-msse4.1等。
表1.1 指令集对应的头文件
| File | 描述 | VS | VisualStudio |
|---|---|---|---|
| intrin.h | AllArchitectures | 8.0 | 2005 |
| mmintrin.h | MMXintrinsics | 6.0 | 6.0SP5+PP5 |
| xmmintrin.h | StreamingSIMDExtensionsintrinsics | 6.0 | 6.0SP5+PP5 |
| emmintrin.h | WillametteNewInstructionintrinsics(SSE2) | 6.0 | 6.0SP5+PP5 |
| pmmintrin.h | SSE3intrinsics | 9.0 | 2008 |
| tmmintrin.h | SSSE3intrinsics | 9.0 | 2008 |
| smmintrin.h | SSE4.1intrinsics | 9.0 | 2008 |
| nmmintrin.h | SSE4.2intrinsics. | 9.0 | 2008 |
| wmmintrin.h | AESandPCLMULQDQintrinsics. | 10.0 | 2010 |
| immintrin.h | Intel-specificintrinsics(AVX) | 10.0 | 2010SP1 |
2、数据类型
| Data type | 表现形式 |
|---|---|
| __m64 | eight 8-bit values, four 16-bit values, two 32-bit values, or one 64-bit value. |
| __m128 | = {float f0, f1, f2, f3} |
| __m128d | = {double d0, d1} |
| __m128i | 16 8-bit, 8 16-bit, 4 32-bit, or 2 64-bit ints |
| __m265 | 256-bit as eight single-precision floating-point values |
| __m265d | 256-bit as four double-precision floating-point values |
| __m256i | 256-bit as integers, (bytes, words, etc.) |
备注:MMX指令集使用 64位数据类型、SSE指令集使用 128数据类型、AVX指令集使用256位数据类型,如图2.1所示:
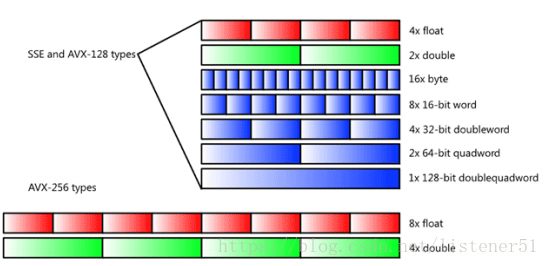
2.1 数据类型的转换
SSE汇编指令和其Intrinsic函数之间基本存在这一一对应的关系,有了汇编的实现再改为Intrinsic是挺简单的,再在这罗列代码也乜嘢什么意义了。这里就记录下使用的过程中遇到的最大的问题:数据类型之间的转换。 做图像处理,由于像素通道值是8位的无符号整数,而与其运算的往往又是浮点数,这就需要将8位无符号整数转换为浮点数;运算完毕后,得到的结果又要写回图像通道,就要是8位无符号整数,还要涉及到超出8位的截断。开始不注意时吃了大亏….
类型转换主要以下几种:
1>. 浮点数和整数的转换及32位浮点数和64位浮点数之间的转换。 这种转换简单直接,只需要调用相应的函数指令即可。
2>. 有符号整数的高位扩展将8位、16位、32位有符号整数扩展为16位、32位、64位。
3>. 有符号整数的截断 将16位、32位、64位有符号压缩
4>. 无符号整数到有符号整数的扩展
在Intrinsic函数中 上述类型转换的格式
_mm_cvtepixx_epixx (xx是位数8/16/32/64)这是有符号整数之间的转换
_mm_cvtepixx_ps / _mm_cvtepixx_pd 整数到单精度/双精度浮点数之间的转换
_mm_cvtepuxx_epixx 无符号整数向有符号整数的扩展,采用高位0扩展的方式,这些函数是对无符号高位0扩展变成相应位数的有符号整数。没有32位无符号整数转换为16位有符号整数这样的操作。
_mm_cvtepuxx_ps / _mm_cvtepuxx_pd 无符号整数转换为单精度/双精度浮点数。
上面的数据转换还少了一种,整数的饱和转换。什么是饱和转换呢,超过的最大值的以最大值来计算,例如8位无符号整数最大值为255,则转换为8位无符号时超过255的值视为255。
整数的饱和转换有两种:
1>、有符号之间的 SSE的Intrinsic函数提供了两种
__m128i _mm_packs_epi32(__m128i a, __m128i b)
__m128i _mm_packs_epi16(__m128i a , __m128i b)用于将16/32位的有符号整数饱和转换为8/16位有符号整数。
2>、有符号到无符号之间的 SSE的Intrinsic函数提供了两种
__m128i _mm_packus_epi32(__m128i a, __m128i b)
__m128i _mm_packus_epi16(__m128i a , __m128i b)用于将16/32位的有符号整数饱和转换为8/16位无符号整数
3、 intrinsic函数命名
Naming convention: _mm_<intrin_op>_<suffix> where mm is the prefix for working on the 64-bit registers or 128-bit registers; intrin_op is the operation, like add for addition or sub for subtraction; and suffix denotes the type of data to operate on, with the first letters denoting packed (p), extended packed (ep), or scalar (s). The remaining letters are the types given in the table below.suffix Markings
| suffix | 数据类型 |
|---|---|
| [s/d] | Single- or double-precision floating point |
| [i/u]nnn | Signed or unsigned integer of bit size nnn, where nnn is 128, 64, 32, 16, or 8 |
| [ps/pd/sd] | Packed single, packed double, or scalar double |
| epi32 | Extended packed 32-bit signed integer |
| si256 | Scalar 256-bit integer |
4、示例
c代码
void add(float *a, float *b, float *c)
{
int i;
for (i = 0; i < 4; i++) {
c[i] = a[i] + b[i];
}
}对应的Intrinsic代码

#include <xmmintrin.h>
void add(float *a, float *b, float *c)
{
__m128 t0, t1;
t0 = _mm_load_ps(a);
t1 = _mm_load_ps(b);
t0 = _mm_add_ps(t0, t1);
_mm_store_ps(c, t0);
}备注:代码摘自https://software.intel.com/sites/default/files/managed/9e/bc/64-ia-32-architectures-optimization-manual.pdf 4.3.1.2 小节
5、附录
intel intrinsic手册 : https://software.intel.com/en-us/articles/intel-sdm
5.1 Latency and Throughput
Latency: 指令占据多少个时钟周期,此后数据才可被下一条指令使用。
Throughput:指令占据运算单元多少个时钟周期,此后运算单元才可被下一条指令使用。
参考网址:https://software.intel.com/en-us/articles/measuring-instruction-latency-and-throughput
参考网址:
https://blog.csdn.net/brookicv/article/details/52295043
https://software.intel.com/en-us/comment/1758892
http://verchetensna.ga/software/4247intel-intrinsics-guide-download.html#
https://www-m17.ma.tum.de/foswiki/pub/M17/Lehrstuhl/LehreWiSe1516ATHPSC/INT1.pdf
https://db.in.tum.de/~finis/x86-intrin-cheatsheet-v2.1.pdf
https://www.inf.ethz.ch/personal/markusp/teaching/263-2300-ETH-spring11/slides/class17.pdf
http://sseplus.sourceforge.net/fntable.html
https://stackoverflow.com/questions/661338/sse-sse2-and-sse3-for-gnu-c/662250#662250
https://stackoverflow.com/questions/7156908/sse-intrinsic-functions-reference
https://gcc.gnu.org/onlinedocs/gcc-4.3.3/gcc/i386-and-x86_002d64-Options.html#i386-and-x86_002d64-Options
http://www.agner.org/optimize/
http://www.ehu.eus/sgi/ARCHIVOS/c_ug_lnx.pdf